
目標檢測YOLO進化史之yolov1
yolov3在目標檢測領域可以算得上是state-of-art級別的了,在實時性和準確性上都有很好的保證.yolo也不是一開始就達到了這麼好的效果,本身也是經歷了不斷地演進的.
yolov1
測試圖片

yolov1有個基本的思想,就是將圖片劃分為S*S個小格grid,每個grid負責一個目標.上圖裡的黃色框就是grid.藍色框就是預測的object.藍色點是object的中心,位於黃色框內.


每個grid只預測一個目標,這個就造成了yolo的一個缺陷,當多個目標的中心都落在同一個grid cell裡的時候,卻只能預測出來一個.比如上圖左下角有9個聖誕老人,但是隻預測出來5個.
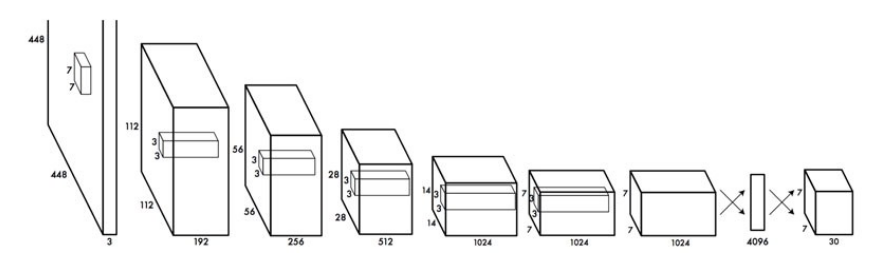
反映到模型上,也就是說輸入一個448*448*3圖片,經過不斷卷積,輸出一個7*7*30的tensor. 這裡的7*7就對應於上面說到的S*S.

那麼這裡的30怎麼來的呢? 每一個grid cell預測2個框出來,每個框對應5個值,(x,y,w,h)和一個box confidence score.box confidence score反映了預測出來的box含有目標的可能性以及這個預測的box的準確性. yolov1預測出20個類別的概率. 所以30 = 2*5 + 20
我們用B指代每個cell預測出B個box,C指代每個cell預測出C個類別的概率.那麼yolo的輸出的tensor的shape則為(S,S,Bx5+C)
這就是yolo的核心思想了,構建一個CNN網路,得到一個(7,7,30)的tensor.
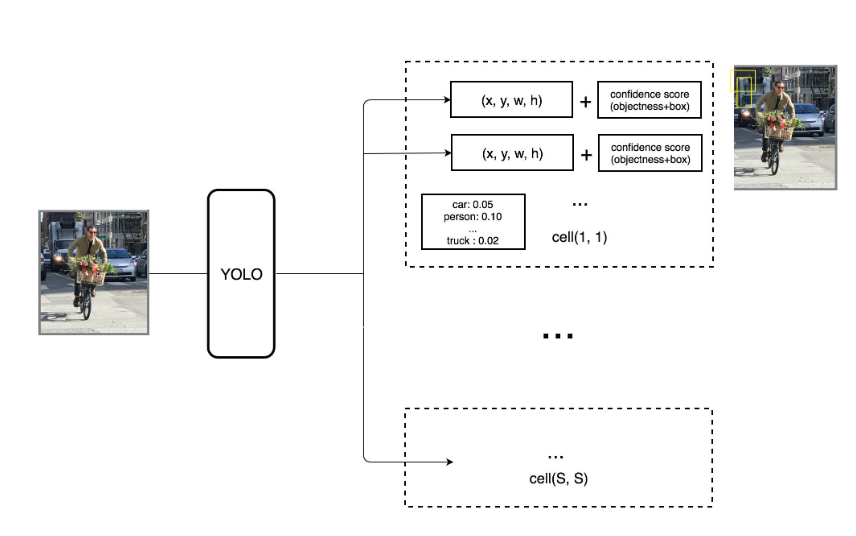
這樣的話就得到了7*7*2個box,我們只保留box confidence score>某個值的box作為我們最終的預測box.

loss
損失函式分為3個部分
- box位置錯誤
- confidence錯誤(box確實包含目標的可能性錯誤)
- 類別概率錯誤
其實也就是衡量我們的這些預測值(x,y,w,h,confidence,classp1,classp2....)和真實值的差異
首先,我們預測出了B個box,我們只會用其中一個去計算loss.我們選取與ground-truth box的IOU最大的作為我們計算loss的box.ground-truth box怎麼來,因為我們事先已經把資料標註好了,我們當然可以找到ground-truth box的中心位於某個grid cell內,如果有多個ground-truth box的中心都位於當前grid cell內,怎麼辦?計算每一個predict box和每一個ground-truth box的IOU,選取iou最大的作為相應的predict box,ground-truth box.這個方式帶來的一個問題就是前面聖誕老人那個圖說到的,當多個目標很密集,他們的中心都落在了同一個grid cell內的時候,yolov1只能檢測出其中之一.
loss函式如下圖所示:
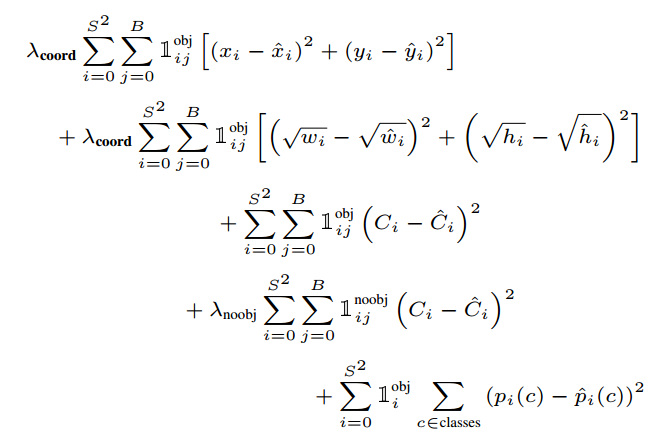
loss函式的設計基於以下幾種考慮
- 每一種loss都給相同的權重是不合適的,對於box位置錯誤給更多的權重,