B+樹 && B+樹索引&&Cardinality值 ----- InnoDB儲存引擎內幕
1.二叉查詢樹&平衡二叉樹
- B+樹由二叉查詢樹+平衡二叉樹演化而來
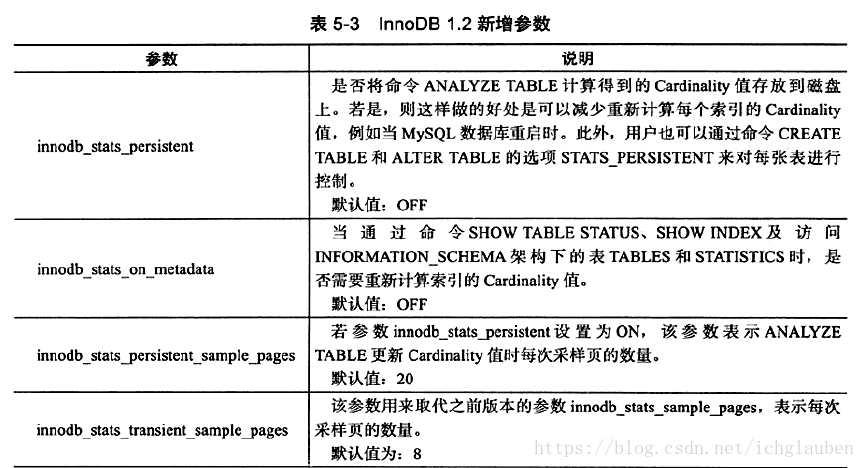
1.1下面來簡單介紹一下二叉查詢樹 - 例子:
上圖中:數字代表每個節點的鍵值
特點: - 1.左子樹的鍵值總是<右子樹的鍵值
- 2.右子樹的鍵值總是>左子樹的鍵值
若對該樹進行查詢,如查鍵值為5的記錄,先找到根6 因為6>5 往左子樹找 得到3 < 5 再找右子樹 找到鍵值 共需要3次
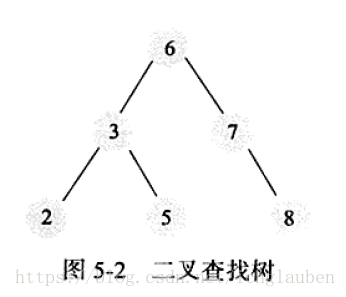
缺點
如果像上圖一樣查詢的效率就低下了
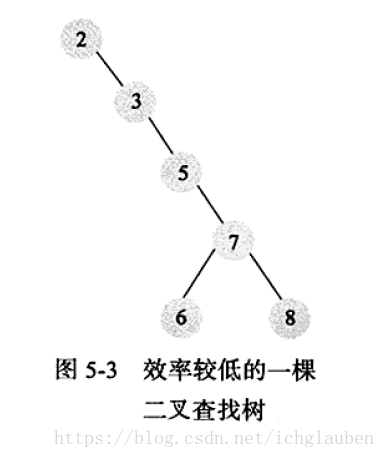
由此引入1.2AVL平衡二叉樹
AVL定義:
- 1.首先符合二叉查詢樹定義
- 2.滿足任何節點的兩個子樹高度差最大是1
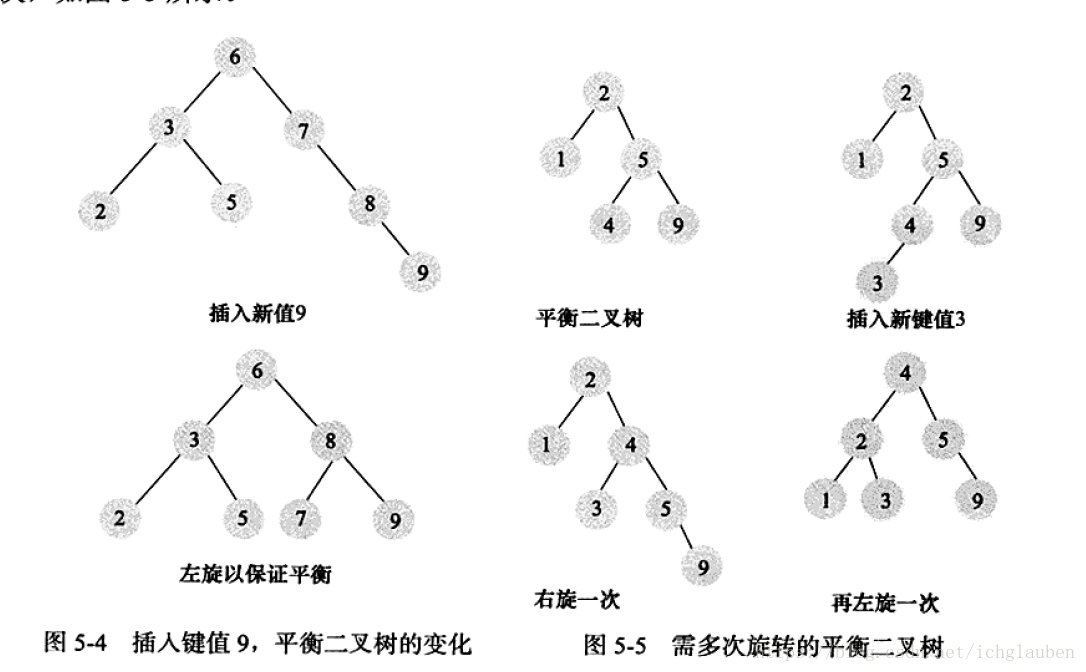
缺點:需要維護的代價非常大,一般需要1次或者多次左旋和右旋來得到插入或更新後樹的平衡性
– 示例:
平衡樹多用於記憶體結構物件中,因此維護的開銷相對較小。
2.B+樹
一顆B+樹要滿足以下特點:
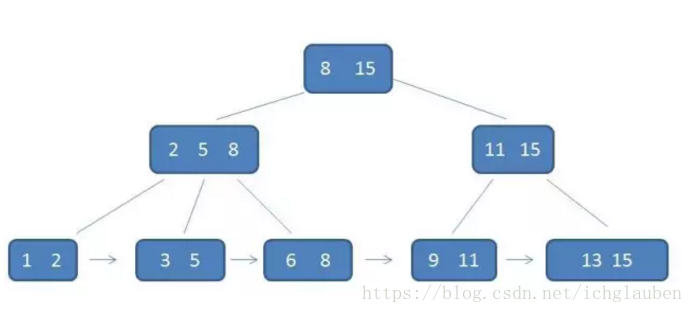
- 1.有k個子樹其中間的節點就包含了k個元素 每個元素不存資料 只是索引(指標) 所有值都儲存在葉子節點中
- 2.所有的葉子節點都包含了全部的元素資訊,包括指向該元素的指標,同時 葉子節點依照關鍵字的大小自小而大連結。
- 3.所有中間節點元素都同時存在於子節點,在子節點元素中最大(最小)的
簡單概括: - 1.子樹個數=非葉子節點數
- 2.非葉子節點僅是索引不存值 可以有重複的元素
- 3.葉子節點存值 用指標連線在一起
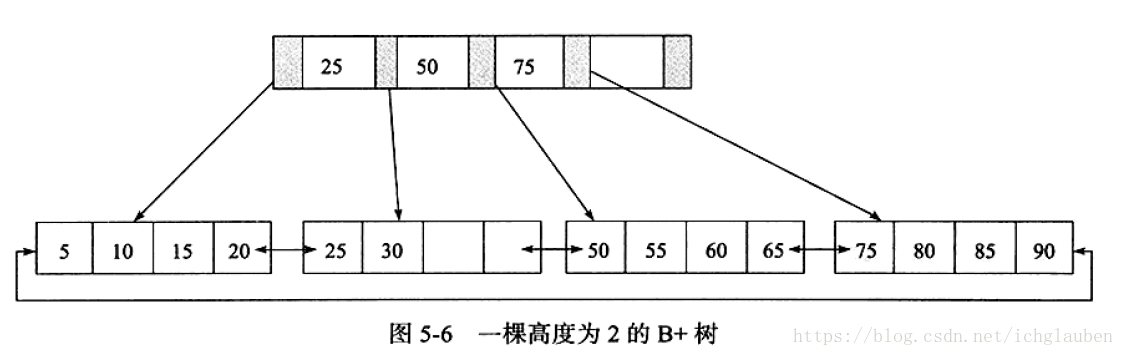
2.1B+樹的插入情況
插入的時候要保證插入後葉子節點依然排序 需要考慮以下三種情況:
舉例分析:

-
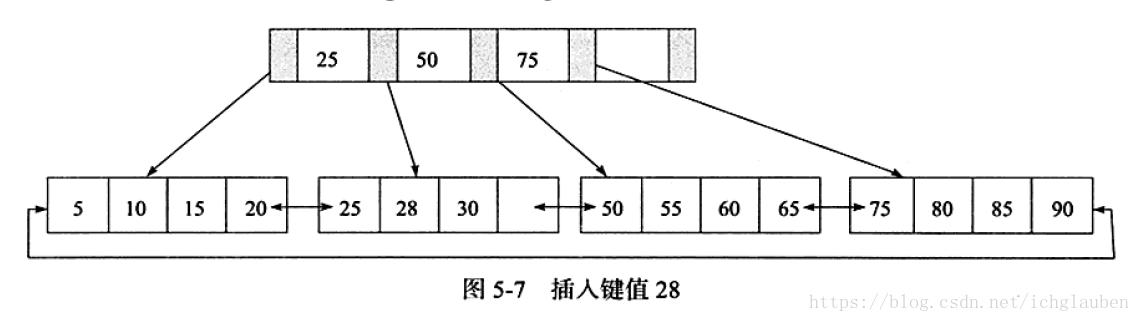
1.插入鍵值28 leaf page& index page都沒有滿 符合第一種情況 直接插入就可以
-
2.插入鍵值70 Leaf Page值滿 Index Page未滿 符合第二種情況
雖然沒有顯示,依然是雙向連結串列指標 存在的
-
3.插入鍵值95 Leaf Page & Index Page都滿了 需要做兩次拆分
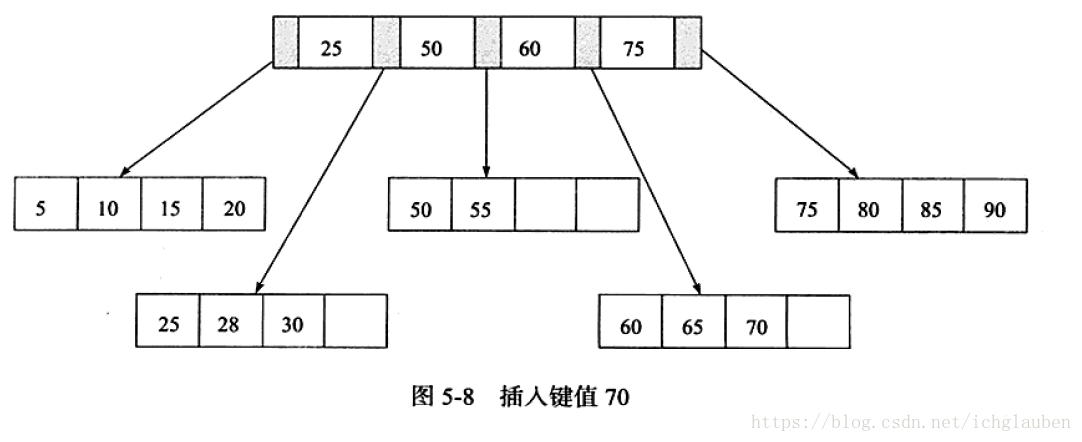
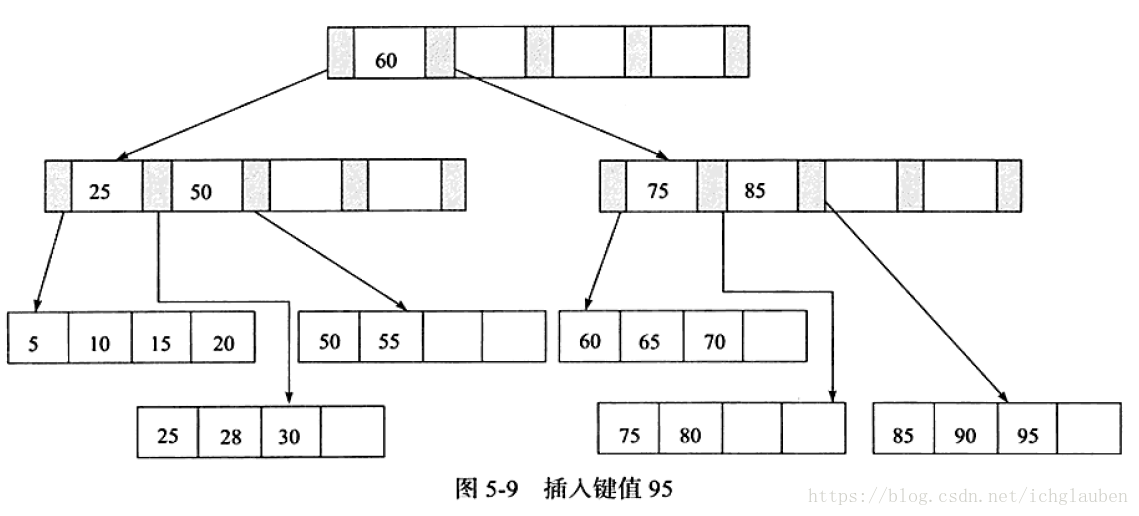
為了保持平衡對於新插入的鍵值需要做大量的拆分頁(split)操作。
由於B+樹主要用於磁碟,頁的拆分表示磁碟的操作,所以儘量減少頁的拆分操作。提供了旋轉操作(Rotation)
看一下旋轉發生的條件:
- 1.Leaf Page已滿 左右兄弟節點沒有滿
- 2.不做拆分 而是將記錄移到所在頁的兄弟節點上
- 示例:插入70

2.2B+樹的刪除操作
同樣也是滿足三種情況 B+樹的刪除操作同樣也要保證排序,根據其填充因子(fill factor 也就是非葉子節點部分 50%是最小值)的變化而衡量

示例
-
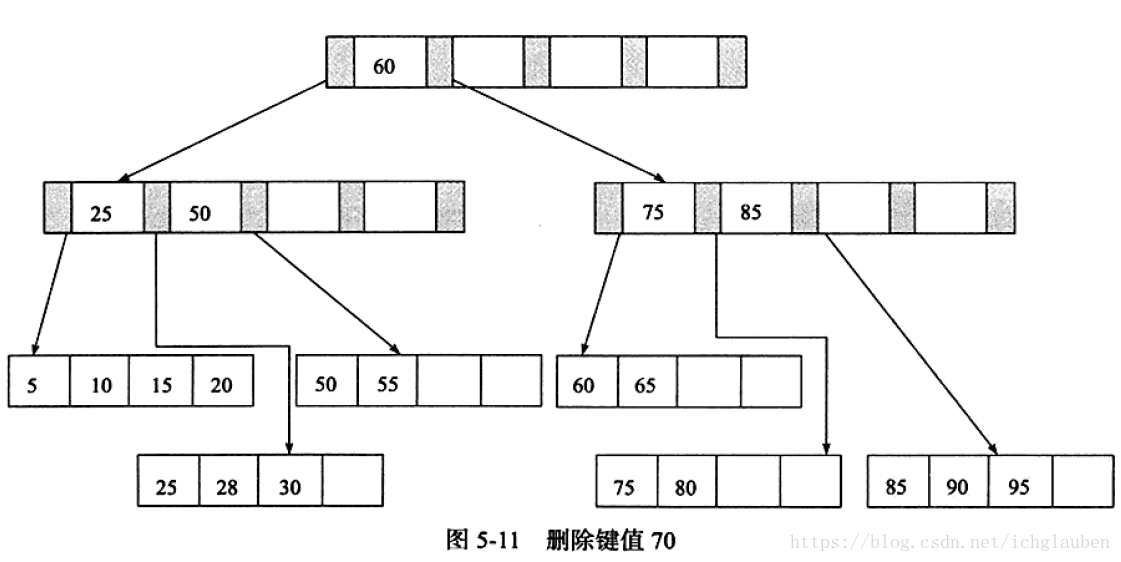
1.刪除鍵值70 符合第一種情況
-
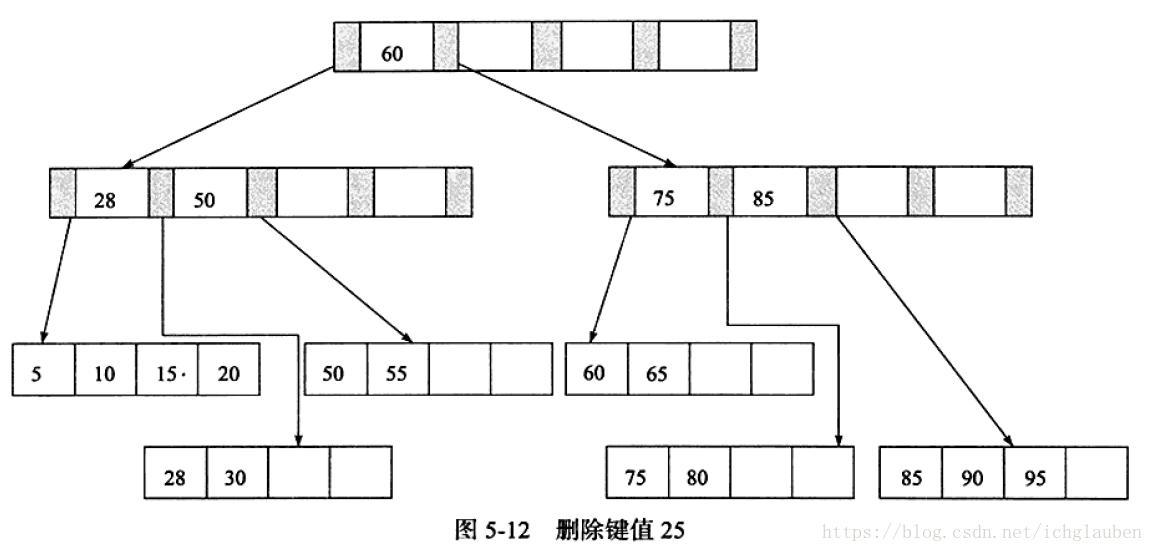
2.刪除鍵值25 同時是Index Page節點
-
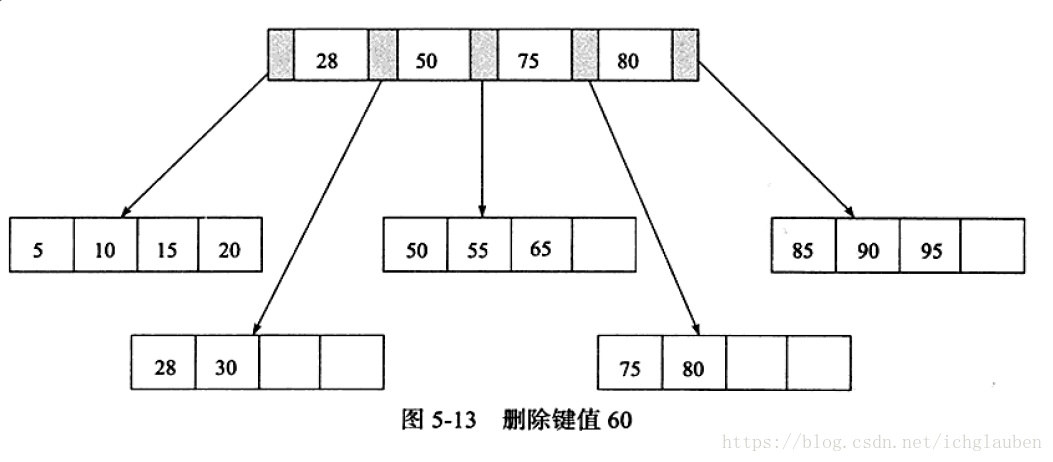
3.刪除鍵值60 Fill Factor<50% 刪除Index Page後 再次需要合併 Index Page
3.B+樹索引
在DB中的特點:高扇出性,B+樹的高度一般都是在2-4層 (查詢某鍵值只需要2-4次IO)
B+索引分類
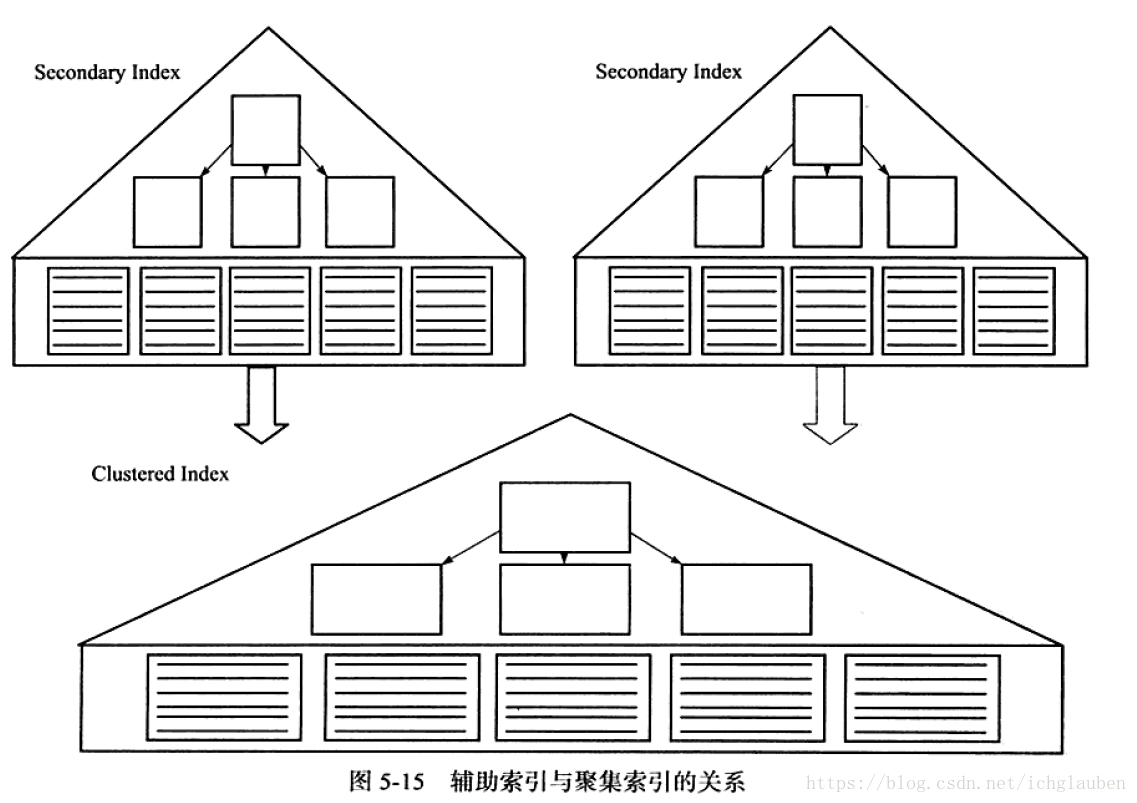
- 1.聚集索引(clustered index)
聚集索引就是按照每張表的主鍵構造一顆B+樹,而且葉子節點就存放了表的所有行記錄資料,也稱聚集索引的葉子節點是資料頁。每個資料頁都由雙向連結串列進行連結。**每個表只能有一顆B+數進行排序 只有一個聚集索引 **。
(接下來的表空間儲存分析只能以後補上了 目前還沒弄懂) - 2.輔助索引(Secondary Index 非聚集索引)
葉子節點並不包含全部資料。葉子節點包含了鍵值&&書籤(bookmark)書籤帶領指向與索引相對應的行資料
和聚集索引的關係
輔助索引不影響資料在聚集索引中的組織,每張表可以有多個輔助索引。
InnoDB引擎遍歷輔助索引找到主鍵索引的主鍵,再通過主鍵索引找到行記錄。
3.1B+樹索引的管理
3.1.1B+樹索引的管理
建立和刪除有兩種:1.ALTER TABLE 2.CREATE | DROP INDEX
- 1.ALTER TABLE
- 2.CREATE | DROP INDEX


如果要檢視:show index from tb
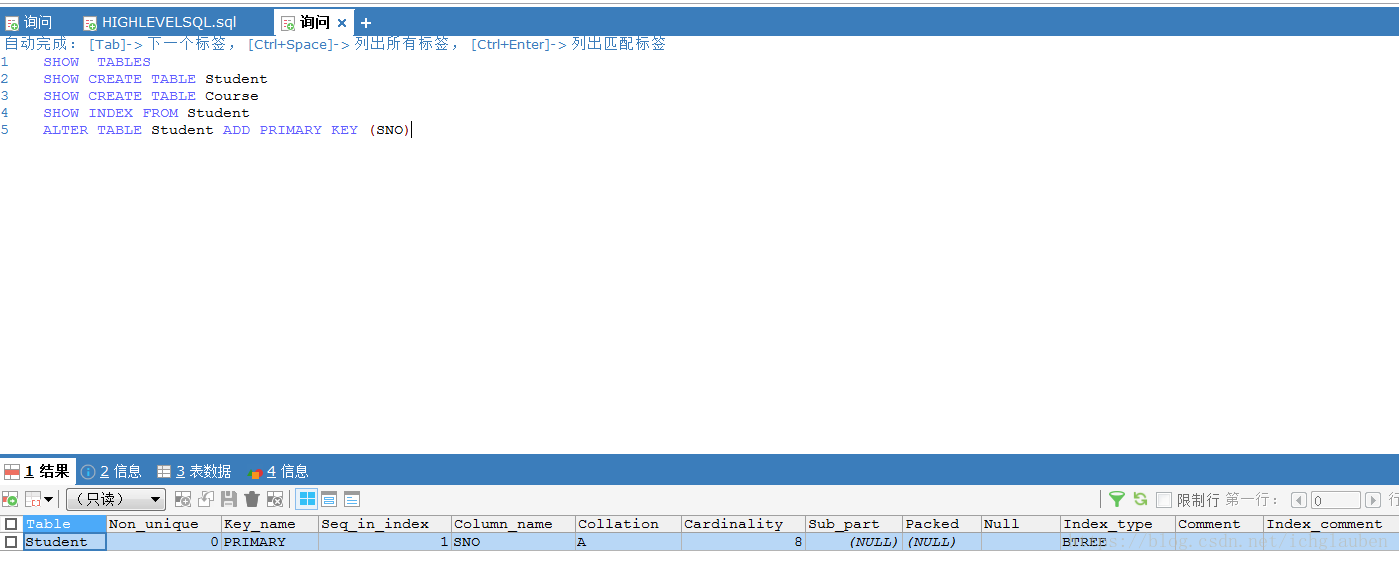
接下來分析每個引數的具體含義
- 1.Table:索引所在的表名
- 2.Non_unique:非唯一索引 如果聚集索引(primary key = 0)
- 3.Key_name:索引名字
- 4.Seq_in_index:索引中該列的位置
- 5.Column_name:索引列的名稱
- 6.Collation:列以什麼方式儲存在索引中。兩種結果 A | NULL A:B+樹索引 表示排序的 NULL:如果使用了Heap儲存引擎 建立Hash索引 顯示NULL.HASH根據Hash桶存放索引資料 不對資料排序
- 7.cardinality :很關鍵的值 表示索引中唯一值的數目的估計值。 行數應儘可能為1.若非常小 考慮是否刪除該索引
- 8.Sup_part:是否是列的部分索引(列只有部分被索引)NULL:整列被索引
- 9.Packed:關鍵字如何被壓縮
- 10.NULL:是否索引列含有NULL值
- 11.Index_type:索引型別 InnoDB只支援B+樹 顯示為BTREE
- 12.Comment:註釋
單獨介紹一下Cardinality: 該值優化器根據該值判斷是否使用這個索引 問題:不是實時更新(每次更新索引不會更新這個值) 建議更新完後使用 ANALYZE TABLE 命令。
- 1)Cardinality為NULL,在某些情況下可能發生索引建立了確沒有用 同樣的語句 一種走索引 另一種走全表掃描。建議:在非高峰時期,對應用程式下的幾張核心表做ANALYZE TABLE操作。
3.1.2Fast Index Creation(FIC):
一般建索引的DDL操作過程:

總結一下:1)新建臨時表(表結構用alter table實現) 2)把資料匯入到tmp表中 3)刪原表 4)把臨時表重名為原來的表
這種方式非常繁瑣 — 引入了FIC(快速索引建立)
輔助索引建立|刪除流程:
- 1)儲存引擎對建索引的表上加s鎖 不需要刪表 重建表 快速了 資料庫可用性得到提高
- 2)刪除輔助索引 需要更新內部檢視 將輔助索引的空間標記為可用 同時刪除DB內部檢視上對該表索引定義即可
3.1.3Online Schema Change(有空要做個實驗了!!!)
MySQL 大表線上DML神器–pt-online-schema-change
pt-online-schema-change的實現原理
OSC實現過程:


3.1.4DDL線上操作
MySQL5.6版本支援Online DDL操作,允許輔助索引建立同時 還允許其他INSERT DELETE UPDATE (DML)操作
以下幾類DDL可以通過線上方式進行操作:
- 1.輔助索引的建立和刪除
- 2.改變自增長
- 3.新增或刪除外來鍵約束
- 4.列的重新命名
語法:

ALGORITHM:指定了建立或刪除索引的演算法。
COPY(按照5.1版本前工作 即要複製表進行建立刪除) INPLACE(不需要建立臨時表) DEFAULT(根據old_alter_table來判斷是通過INPLACE | COPY演算法 預設值為OFF 使用inplace的方式)
LOCK:索引建立或刪除時對錶新增鎖的情況。
(1)NONE:執行索引或者刪除操作時 對目標表不新增任何的鎖 即事務仍然可以進行讀寫操作 不會收到阻塞。 可以獲得最大併發度。
(2)SHARE:類似FIC 建立或刪除索引加S鎖。對於併發讀事務依然可以執行 遇到寫事務 會發生等待操作。如果儲存引擎支援SHARE模式 會返回一個錯誤資訊。
(3)EXCLUSIVE:執行索引建立或刪除操作時,對目標表加上一個X鎖 讀寫事務不能進行 所以會阻塞所有的執行緒,和COPY方式執行得到的狀態類似,但不需要像COPY方式那樣建立一張臨時表。
(4)DEFAULT:首先判斷當前操作是否可以用NONE模式,不能就判斷是否使用SHARE模式了,最後判斷是否可以使用EXCLUSIVE模式
實現Online DDL的原理:在執行建立或者刪除操作的同時,將INSERT UPDATE DELETE這類DML操作日誌寫入到一個快取中。待完成索引後重新應用到表上,達到資料一致性。
4.Cardinality值:
- 新增索引的條件:在訪問表中很少使用一部分時使用B+樹索引有意義。具有高選擇性的 並且抽取小欄位的資料可以建B+樹索引
- 高選擇性:取值範圍大 如姓名 ID等大範圍 (低選擇性: 取值範圍小 如性別欄位 地區欄位 型別欄位 型別欄位 可取值的範圍很小)
4.1統計Cardinality值:
考慮統計的因素:(1)統計頻率 觸發更新為update & insert 更新一次就統計的話 頻繁了(2)統計表數量級過大 統計時間長不好
- 更新Cardinality策略:
- 1.表中1/16的資料已發生過變化
- 2.stat_modified_counter>2000 000 000(防止更新次數只在一行 若更新了該次數 也需要更新統計)
取樣過程 預設InnoDB儲存引擎對8個葉子節點進行取樣:
- 取得B+樹索引中葉子節點的數量 記為A
- 隨機取得B+樹索引中的8個葉子節點 統計每個頁不同記錄的個數 即為P1,P2…P8
- 根據取樣資訊給出Cardinality的預估值:Cardinality=(P1+P2+…P8)*A/8
可以得到統計取樣值不是精確值 可能每次得到的值都不一樣