
InnoDB儲存引擎索引——B+樹索引
一、InnoDB儲存引擎索引概述
* B+ 數索引
* 全文索引
* 雜湊索引
InnoDB 儲存引擎支援的雜湊索引是自適應的,InnoDB 儲存引擎會根據表的使用情況自動為表生成雜湊索引,不能人為干預是否在一張表中生成雜湊索引。
B+ 樹索引就是傳統意義上的索引,這是目前關係型資料庫系統中最為常用和最為有效的索引。B+ 樹索引的構造類似於二叉樹,根據鍵值(Key Value)快速找到資料。
B+ 樹中的B 不是代表二叉(binary),而是代表平衡(balance),因為B+樹是從最早的平衡二叉樹演化而來的,但是B+樹不是一個二叉樹。
還有,B+樹索引並不能找到一個給定鍵值的具體行。B+樹索引能找到的只能被查詢資料行所在的頁。然後資料庫通過把頁讀入到記憶體,再在記憶體中進行查詢,最後得到要查詢的資料。
二、資料結構與演算法
B+數索引是最為常見,也是在資料庫中使用最為頻繁的一種索引。在介紹高索引之前先介紹與之密切相關的一些演算法與資料結構。這樣有助於理解B+數索引的工作方式。
1. 二分查詢法
二分查詢法(binary search)也成為折半查詢法,用來查詢一組有序的記錄陣列中的某一記錄,其基本思想史:將記錄有序化(遞增或遞減)排列,在查詢過程中採用跳躍式方式查詢,即現以有序數列的終點位置為比較物件,如果要找的元素值小於該中點值,則將待查序列縮小為左半部分,否則為右半部分。通過一次比較,將查詢區間縮小一半。
例如:5、10、22、33、37、43、48、51、52這九個數。現要從這10個數中查詢43這條記錄,其查詢過程如下圖所示:

這是奇數個去中間值((1+9)/2 = 5),如果偶數個((1+8)/2 = 4),取整就好了。
從圖中可以看出,用了3次就找到了 43這個數。如果是順序查詢,則需要8次。因此,二分查詢法的效率比順序查詢法要好(平均來說)。但如果所要查 5 這條記錄,順序查詢只需1 次,而二分查詢需要 4次。我們看來,對於上面 10 個數來說,順序查詢平均次數為(1+2+3+4+5+6+7+8+9)/9 = 5。
而二分查詢為(3+2+3+4+1+3+2+3+4)/9=2.4.在最壞的情況下,順序查詢次數為9.二分查詢為4.
1. 二叉查詢樹和平衡二叉樹
在介紹 B+數前,需要先了解一下二叉查詢樹。B+樹是通過二叉查詢樹,在由平衡二叉樹,B樹演化而來。如圖,為一個二叉查詢樹。
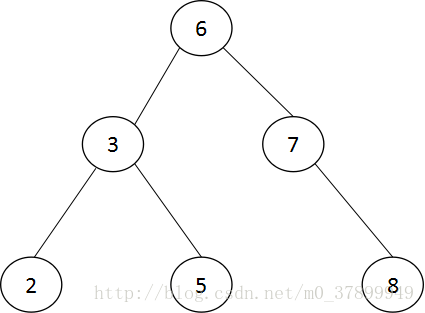
圖中數字代表每個節點的鍵值,在二叉查詢樹中,左子樹的鍵值總是小於根的鍵值,右子樹的鍵值總是大於根的鍵值。因此可以通過中序遍歷得到鍵值的排序輸出,圖中的二叉查詢樹經過中序遍歷後輸出:
2、3、5、6、7、8
(1. 前根序遍歷:先遍歷根結點,然後遍歷左子樹,最後遍歷右子樹。
2.中根序遍歷:先遍歷左子樹,然後遍歷根結點,最後遍歷右子樹。
3.後根序遍歷:先遍歷左子樹,然後遍歷右子樹,最後遍歷根節點。)
對圖中這顆二叉樹進行查詢,如查鍵值為5的記錄,先找到根,其鍵值是6,6大於5,因此查詢6的左子樹,找到3,,而5大於3,查詢3的右子樹,找到5;一種找了3次。如果按2、3、5、6、7、8這個順序來找同樣需要3次。用同樣的方法在查詢鍵值為8的這記錄,這次用了3次查詢,而順序查詢需要6次。計算平均可得:順序查詢的平均次數為(1+2+3+4+5+6)/6 = 3.3次,二叉查詢樹的平均次數為(3+3+3+2+2+1)/6 = 2.3次。二叉查詢樹的平均查詢速度比順序查詢來的更快。
二叉樹可以任意的構造,同樣是2、3、5、6、7、8這五個數字,也可以按下圖的方式建立二叉查詢樹。
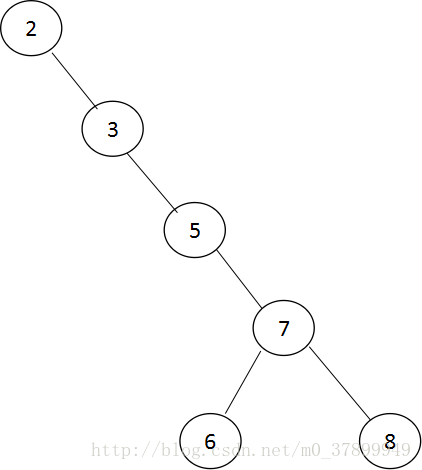
如圖的平均查詢次數為(1+2+3+4+5+5)/6 = 3.16次,和順序查詢差不多。顯然這課二叉查詢樹的查詢效率就低了。因此若想最大效能地構造一個二叉查詢樹,需要這棵二叉查詢樹是平衡的,從而引出了新的定義—平衡二叉樹,或稱AVL數。
平衡二叉樹定義如下:首先符合二叉查詢樹的定義,其次必須滿足任何節點的兩個子樹的最大高度差為1.顯然,上圖不滿足平衡二叉樹的定義。平衡二叉樹的效能是比較高的,但不是最高的,只是接近最高效能。最好的效能需要建立一棵最優二叉樹,但是最優二叉樹的建立和維護需要大量的操作,因此,使用者一般只需要建立一棵平衡二叉樹即可。
平衡二叉樹的查詢速度的確很快,但是維護一棵平衡二叉樹的代價是非常大的,通常來說,需要1 次或多次左旋和右旋來得到插入或更新後樹的平衡性。對於上圖來說,當用戶需要插入一個新的鍵值為9的節點時,需要下圖的變動。
這裡通過一次左旋操作就將插入後的樹重新變為平衡的了。但是有的情況可能需要多次
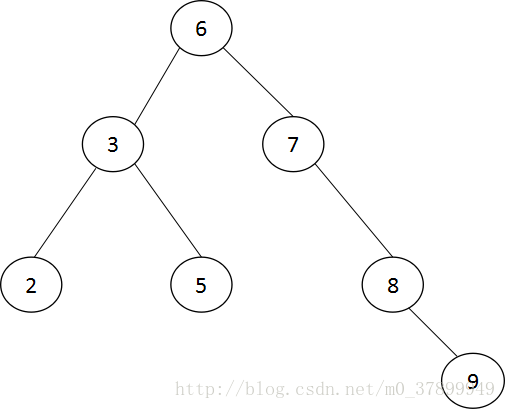
插入新值9
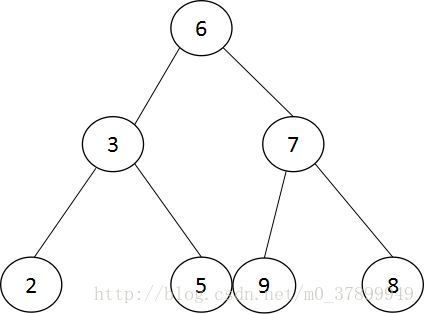
左旋以保證平衡
左旋就是7的右孩子8變成根節點,7變成8的左孩子
除了插入操作,還有更新和刪除操作,不過這和插入沒有本質區別,都是通過左旋或者右旋來完後才能的。因此對一棵平衡樹的維護是有一定開銷的,不過平衡二叉樹多用於記憶體結構物件中,因此維護的開銷相對較小。
三、B+樹
B+樹:B+樹是為磁碟或其他直接存取輔助裝置設計的一種平衡查詢樹。在B+樹中,所有記錄結點都是按鍵值的大小順序存放在同一層的葉子節點上,由個葉子節點指標進行連線。先來看一個B+樹,其高度為2,每頁可以存放4條記錄,扇出為5.如下圖所示
從圖中看出,所有記錄都在葉子節點上,並且是順序存放的,如果使用者從最左邊的葉子節點開始順序遍歷,可以得到所有鍵值的順序飄絮:5、10、15、20、25、30、50、55、60、65、75、80、85、90
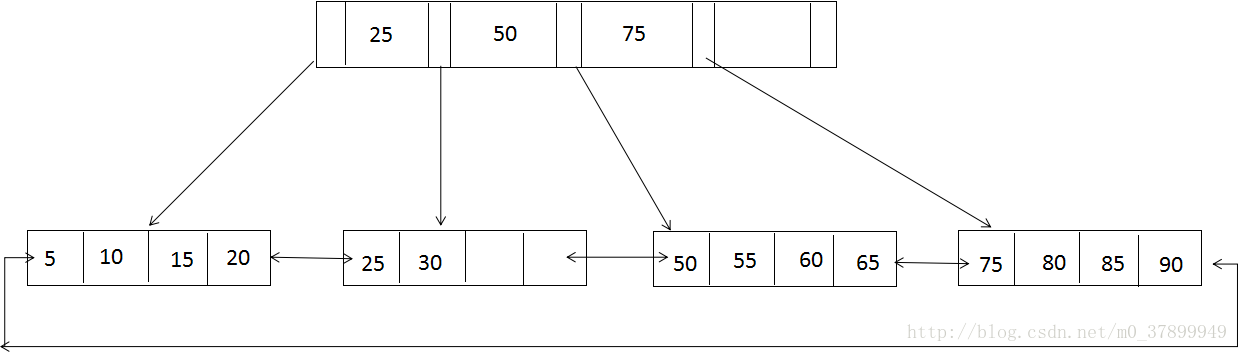
一棵高度為2的B+樹
四、B+樹索引
B+樹索引的本質就是B+樹在資料庫中的實現。但是B+索引在資料庫中有一個特點是高扇出性,因此在資料庫中,B+樹的高度一般都在2~4層,這也就是說查詢某一鍵值的行記錄時最多隻需要2到4次IO,這道不錯,因為當前一般的及其磁碟每秒至少可以做100次IO,2~4次的IO意味著查詢時間只需0.02~0.04秒。
資料庫中的B+樹索引可以分為聚集索引(clustered index)和輔助索引(secondary index),但是
不管是聚集索引還是輔助索引,其內部都是B+樹索引,即高度平衡的,葉子節點存放著所有的資料。聚集索引與輔助索引不同的是,葉子節點存放的是否是一整行的資訊。
* 聚集索引
InnoDB儲存引擎表時索引組織表,即表中資料按照主鍵順序存放。而聚集索引就是按照每張表的主鍵構造一棵B+樹,同時葉子節點中存放的即為整張表的行記錄資料,也將聚集索引的葉子節點稱為資料頁。聚集索引的這個特性決定了索引組織表中資料也是索引的一部分。同B+樹資料結構一樣,每個資料頁都通過一個雙向連結串列來進行連線。
由於實際的資料頁只能按照一棵B+樹進行排序,因此每張表只能擁有一個聚集索引。在多數情況下,查詢優化器傾向於採用聚集索引。因為聚集索引能夠在B+樹索引的葉子節點上直接找到資料。此外,由於定義了資料的邏輯順序,聚集索引能夠特別快的訪問針對範圍值的查詢。查詢優化器能夠快速發現某一段範圍的資料頁需要掃描。
* 輔助索引(非聚集索引)
對於輔助索引,葉子節點並不包含行記錄的全部資料。葉子節點除了包含鍵值以外,每個葉子節點中的索引行中還包含了一個書籤。高書籤用來告訴InnoDB 儲存引擎哪裡可以找到與索引相對應的行資料。由於InnoDB 儲存引擎表時索引組織表,因此 InnoDB 儲存引擎的輔助索引的書籤就是相應行資料的聚集索引。
輔助索引的存在並不影響資料在聚集索引中的組織,因此每張表上可以有多個輔助索引。當通過輔助索引來尋找資料時,InnoDB儲存引擎會遍歷輔助索引並通過葉級別的指標獲得指向主鍵索引的主鍵,然後再通過主鍵索引來找到一個完整的行記錄。