
HBase安裝 - 聯邦機制下的hadoop叢集
老師的聯邦機制的hadoop叢集的分佈 :
master1 : namenode zkfc
master1ha : namenode zkfc zookeeper journalnode
master2: namenode zkfc zookeeper journalnode
master2ha: namenode zkfc zookeeper journalnode
h2slave1: nodemanager datanode
h2slave2: nodemanager datanode
h2slave3: nodemanager datanode
HBase的安裝文件:
1.1 上傳
1.2 解壓
1.3 重新命名
1.4 修改環境變數(每臺機器都要執行)
1.5 修改配置檔案
1.6 分發
1.7 啟動
先在一臺機器上安裝,配置好了之後,再發送到其他的從機器上。
配置檔案 conf:
一般情況下,軟體有這麼三類配置檔案:1,xxxx-site.xml : 核心配置 2,xxx-env.sh : 配置環境變數的 3. xxxs :: 沒有後綴名的檔案 : 用來配置從節點的。
為什麼要配置環境變數?
如何沒配置環境變數,jdk照樣能用如果沒有配置環境變數的話,那麼就需要告訴軟體jdk在哪,所以最好指定環境變數。
export JAVA_HOME=/usr/jdk/
export JAVA_CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HBASE_OPTS="-XX:+UseConcMarkSweepGC" -- JVM引數
export HBASE_MANAGES_ZK=false -- 如果是false,那麼就需要使用自己配置的zookeeper叢集,如果是true,那麼就是使用HBase內建的單機版本的zoookeeper
- 配置從節點: regionservers
h2slave1 h2slave2 h2slave3
- hbase-site.xml : 核心配置
- Master的位置:
<property>
<name>hbase.master</name>
<value>master1:60000</value>
</property>
- 間隔時間 : 主和備NameNode需要檢查心跳。
執行主備的間隔時間
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
如果間隔時間出現問題報錯了,那麼就讓主備的時間同步,或者把這個間隔時間改大一點。
- HBase是依賴hdfs儲存的,需要制定儲存的位置
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop-cluster1/hbase</value>
</property>
<property>
hadoop-cluster1 是邏輯名字,如果是配置ip : port的話,那麼就只能指定一臺機器連線hdfs,但是主跟備會切換的。所以這裡指定的是主備的那套對映,這個對映是搭建hadoop聯邦機制機器的時候,hadoop的配置檔案裡面定義好了的。所以應該把hadoop的配置檔案 hdfs-site.xml 複製到這個HBase這個配置檔案下。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.nameservices</name>
<value>hadoop-cluster1,hadoop-cluster2</value>
</property>
<property>
<name>dfs.ha.namenodes.hadoop-cluster1</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop-cluster1.nn1</name>
<value>master1:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop-cluster1.nn2</name>
<value>master1ha:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoop-cluster1.nn1</name>
<value>master1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoop-cluster1.nn2</name>
<value>master1ha:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.hadoop-cluster1.nn1</name>
<value>master1:9001</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.hadoop-cluster1.nn2</name>
<value>master1ha:9001</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.hadoop-cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.namenodes.hadoop-cluster2</name>
<value>nn3,nn4</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop-cluster2.nn3</name>
<value>master2:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop-cluster2.nn4</name>
<value>master2ha:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoop-cluster2.nn3</name>
<value>master2:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoop-cluster2.nn4</name>
<value>master2ha:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.hadoop-cluster2.nn3</name>
<value>master2:9001</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.hadoop-cluster2.nn4</name>
<value>master2ha:9001</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.hadoop-cluster2</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop/namedir</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir.hadoop-cluster1.nn1</name>
<value>qjournal://master1ha:8485;master2:8485;master2ha:8485/cluster1</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir.hadoop-cluster1.nn2</name>
<value>qjournal://master1ha:8485;master2:8485;master2ha:8485/cluster1</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir.hadoop-cluster2.nn3</name>
<value>qjournal://master1ha:8485;master2:8485;master2ha:8485/cluster2</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir.hadoop-cluster2.nn4</name>
<value>qjournal://master1ha:8485;master2:8485;master2ha:8485/cluster2</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop/datadir</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master2ha:2181,master1ha:2181,master2:2181</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>5000</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/hadoop/jndir</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permission</name>
<value>false</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
</configuration>
HBase只認識主機名字跟ip,因此需要hdfs-site.xml,還需要hadoop聯邦機制下的core-site.xml
- 指定是否是叢集模式
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
- 指定zookeeper
<property>
<name>hbase.zookeeper.quorum</name>
<value>master1ha,master2,master2ha</value>
</property>
6.指定zookeeper的工作的資料目錄
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/hbase/tmp/zookeeper</value>
</property>
其他的配置都不需要配置,使用的都是預設的。
搞完了配置檔案,我們從配置檔案中,可以看出來,實際上HBase的從節點和主節點沒有一個太大的區別,不想zookeeper有一個myid,配置都是一樣的,主知道從是哪個,從也知道主是誰。
傳送:
scp -r hbase/ [email protected]:/home/hadoop/apps
scp -r hbase/ [email protected]:/home/hadoop/apps
scp -r hbase/ [email protected]:/home/hadoop/apps
接下來就是啟動了。

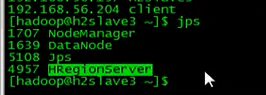
現在HBase啟動了一個主了,還需要啟動另外的三個從
h2slave1,h2slave2,h2slave3
在啟動一個主: 適合版本一
hbase-daemon.sh start master
啟動失敗,可以使用這個命令:
local-master-backup.sh start 2
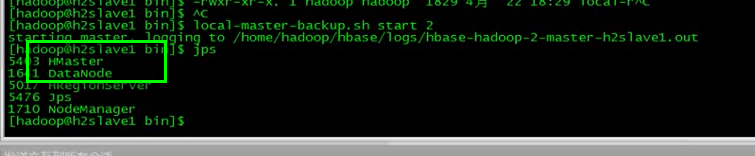
如果想新增HBase從節點,複製一臺從節點資訊到另一臺,然後直接啟動就行。
hbase-daemon.sh start regionserver
所以加雙主和動態增刪節點是很簡單就可以實現的。是有zookeeper來控制的。

zookeeper上有三個節點資訊。
還有backup-master
