
spark任務提交流程與管依賴和窄依賴

 恢復的時候得根據依賴關係恢復(checkPoint)
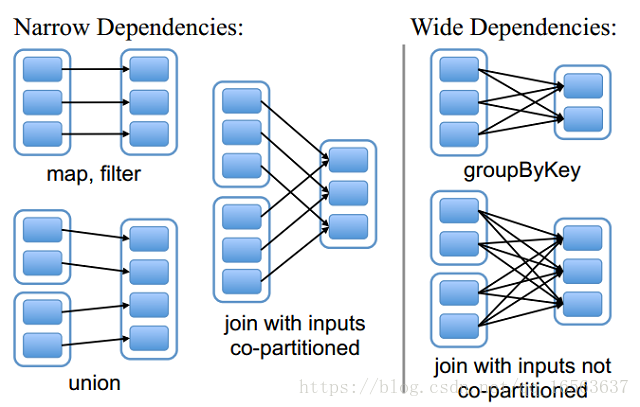
窄依賴:父分割槽的資料只給一個子分割槽
寬依賴:父分割槽的資料給多個子分割槽
恢復的時候得根據依賴關係恢復(checkPoint)
窄依賴:父分割槽的資料只給一個子分割槽
寬依賴:父分割槽的資料給多個子分割槽
相關推薦
spark任務提交流程與管依賴和窄依賴
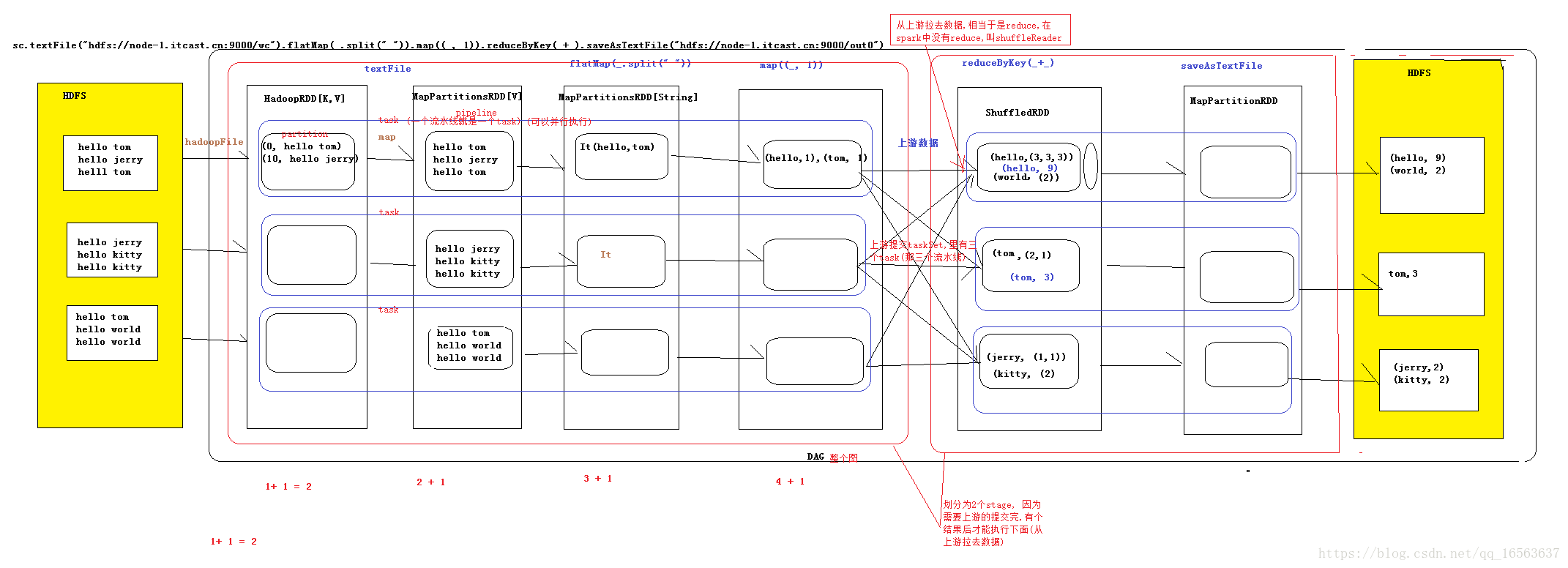
spark核心執行流程圖 代表4個階段 1構建RDD,進行join,groupBy,filter操作,形成DAG有向無環圖(有方向,沒有閉環),在最後一個action時完成DAG圖,代表著資料流向 2提交DAG為DAGScheduler,DAG排程器,主要是將
Spark核心原始碼深度剖析(1) - Spark整體流程 和寬依賴和窄依賴
1 Spark 整體流程 2 寬依賴和窄依賴 2.1 窄依賴 Narrow Dependency,一個RDD對它的父RDD,只有簡單的一對一的依賴關係。即RDD的每個 partition僅僅依賴於父RDD中的一個 partition。父RDD和子RDD的
spark任務提交流程(standalone)
spark程式使用spark-submit方式提交,如果是standalone叢集的話,會在提交任務的節點啟動一個driver程序; dirver程序啟動以後,首先是構建sparkcontext,sparkcontext主要包含兩部分:DAGScheduler
spark-寬依賴和窄依賴
交互 本質 pen alt png spark img 出現 技術分享 一、窄依賴(Narrow Dependency,) 即一個RDD,對它的父RDD,只有簡單的一對一的依賴關系。也就是說, RDD的每個partition ,僅僅依賴於父RDD中的一個partit
Spark 中的寬依賴和窄依賴
Spark中RDD的高效與DAG圖有著莫大的關係,在DAG排程中需要對計算過程劃分stage,而劃分依據就是RDD之間的依賴關係。針對不同的轉換函式,RDD之間的依賴關係分類窄依賴(narrow dependency)和寬依賴(wide dependency, 也稱 shuf
spark學習筆記之二:寬依賴和窄依賴
1.如果父RDD裡的一個partition只去向一個子RDD裡的partition為窄依賴,否則為寬依賴(只要是shuffle操作)。 2.spark根據運算元判斷寬窄依賴: 窄依賴:map
RDD理解及寬依賴和窄依賴
1)RDD概念:Resilient Distributed Datasets 彈性分散式資料集,是一個容錯的、並行的資料結構,可以讓使用者顯式地將資料儲存到磁碟和記憶體中,並能控制資料的分割槽。同時,RDD還提供了一組豐富的操作來操作這些資料。RDD是隻讀的記錄分割槽的
Spark(六)Spark任務提交方式和執行流程
sla handles 解析 nod 就會 clust 它的 管理機 nag 一、Spark中的基本概念 (1)Application:表示你的應用程序 (2)Driver:表示main()函數,創建SparkContext。由SparkContext負責與Cluste
第二天 -- Spark叢集啟動流程 -- 任務提交流程 -- RDD依賴關係 -- RDD快取 -- 兩個案例
第二天 – Spark叢集啟動流程 – 任務提交流程 – RDD依賴關係 – RDD快取 – 兩個案例 文章目錄 第二天 -- Spark叢集啟動流程 -- 任務提交流程 -- RDD依賴關係 -- RDD快取 -- 兩個案例 一、Spa
Spark任務提交方式和執行流程
ref www. ack app cnblogs driver tex src tor 轉自:http://www.cnblogs.com/frankdeng/p/9301485.html 一、Spark中的基本概念 (1)Application:表示你的應用程序 (
Spark任務提交執行全流程詳解
** Spark任務提交執行流程 ** Spark任務的本質是對我們編寫的RDD的依賴關係切分成一個個Stage,將Stage按照分割槽分批次的生成TaskSet傳送到Executor進行任務的執行 Spark任務分兩種: 1、shuffleMapTask:shuffle
【資源排程總綱】Yarn原始碼剖析(零) --- spark任務提交到yarn的流程
前言 本系列的目的在於試圖剖析spark任務提交至hadoop yarn上的整個過程,從yarn的啟動,以及spark-submit提交任務到yarn上,和在yarn中啟動任務包括yarn元件之間的通訊,用以提升自身知識儲備,記錄學習的過程為目的,由於個人能力有限文章中或許
Spark任務提交 yarn-cluster模式 解決jvm記憶體溢位問題 以及簡單概述jdk7方法區和jdk8元空間
yarn-cluster 提價任務流程 1、提交方式 ./spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../lib/spark-exampl
Spark任務提交jar包依賴解決方案
通常我們將spark任務編寫後打包成jar包,使用spark-submit進行提交,因為spark是分散式任務,如果執行機器上沒有對應的依賴jar檔案就會報ClassNotFound的錯誤。 下面有三個解決方法: 方法一:spark-submit –ja
大資料基礎之Spark(1)Spark Submit即Spark任務提交過程
Spark版本2.1.1 一 Spark Submit本地解析 1.1 現象 提交命令: spark-submit --master local[10] --driver-memory 30g --class app.package.AppClass app-1
YARN的任務提交流程簡述及圖解
#YARN的任務提交流程簡述及圖解 1,Client向ResourceManager發出請求,提交程式,(ResourceManager中有Scheduler排程器和ApplicationsManager應用程式管理器 2,ResourceManager向Scheduler返回一個A
Spark任務執行流程
這是Spark官方給的圖,大致意思就是: 四個步驟 1.構建DAG(有向無環圖)(呼叫RDD上的方法) 2.DAGScheduler將DAG切分Stage(切分的依據是Shuffle),將Stage中生成的Task以TaskSet的形式給TaskSchedul
storm(06)——storm原理(任務提交流程)
Storm 任務提交的過程 client: 1.client提交topology 到Nimbus; Nimbus: 2.提交的jar包會被上傳到nimbus伺服器的nimbus/inbox目錄下; 3.submitTopology方法對這個topology進行
Spark2.x原始碼分析---spark-submit提交流程
本文以spark on yarn的yarn-cluster模式進行原始碼解析,如有不妥之處,歡迎吐槽。 步驟1.spark-submit提交任務指令碼 spark-submit --class 主類路徑 \ --master yarn \ --deploy-mode c
Spark-任務執行流程
目錄 Application在叢集中執行的大概流程 Application提交的方式 Application提交的叢集 Application在叢集中執行的大概流程 流程: 1.Driver分發task到資料所在的節點上執行。