Stanford機器學習-Neural Networks : learning
一、代價函式

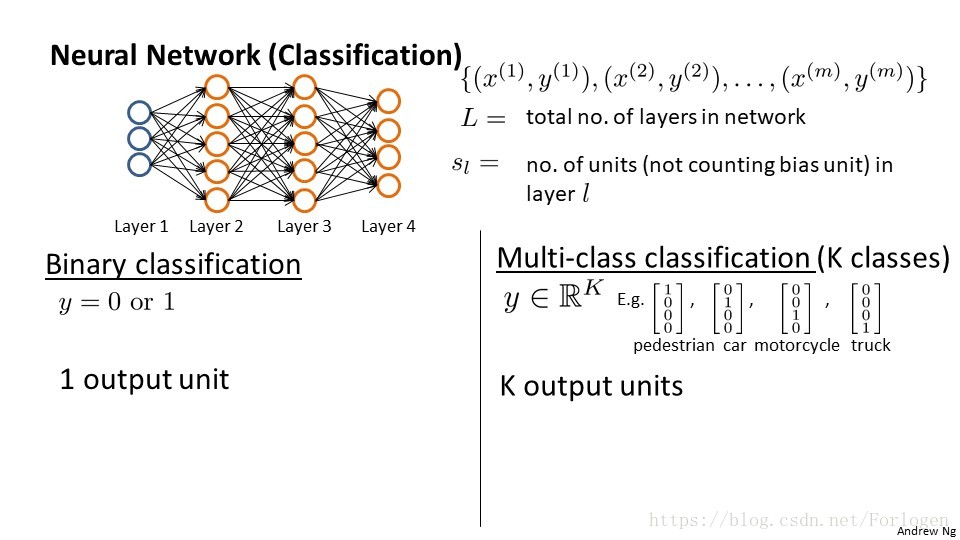
在分類問題中,我們可以粗略的分為兩類
1. 二分類問題
在輸出單元我們可以用1表示正例,0表示負例,或者相反;
2. 多分類問題
在多分類問題中,我們不用單個的不同數字表示不同的類別,而是採用不同向量的方式,K的類別我們就是用K個向量區分

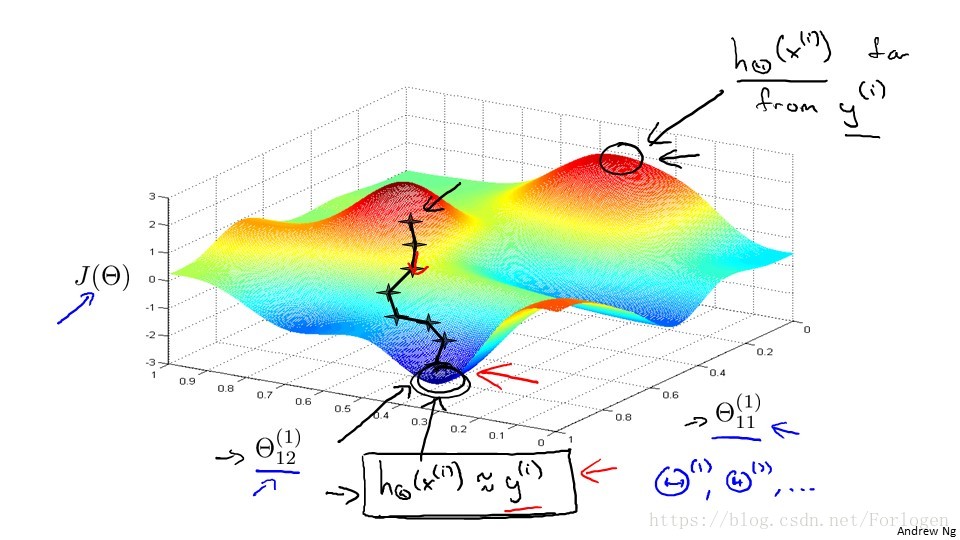
在前面的Logistic迴歸中,我們的代價函式J(θ)如圖所示,我們需要輸出變數可以分開類別,所以輸出變數只有一個y,而在神經網路中 我們的輸出問題可能會有K個類別,因此我們的輸出單元需要K維的向量,那麼我們的代價函式就如上圖所示。
複雜的結構背後的思想和前面的仍然一樣,我們希望通過計算代價來看一下預測的值和真實的值的誤差,選擇誤差最小的那一個。 但在多分類問題中,我們通常會給出K個預測的輸出,我們利用迴圈對每一個特徵都預測k個不同的結果,然後在迴圈中選擇K個預測中 可能性最高的那一個,再與真實的值進行比較。
二、後向傳播演算法


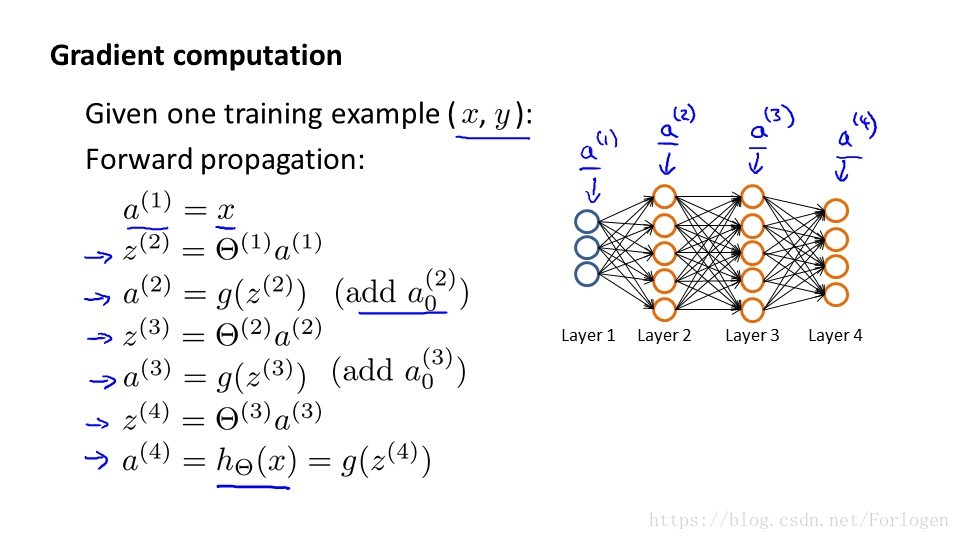
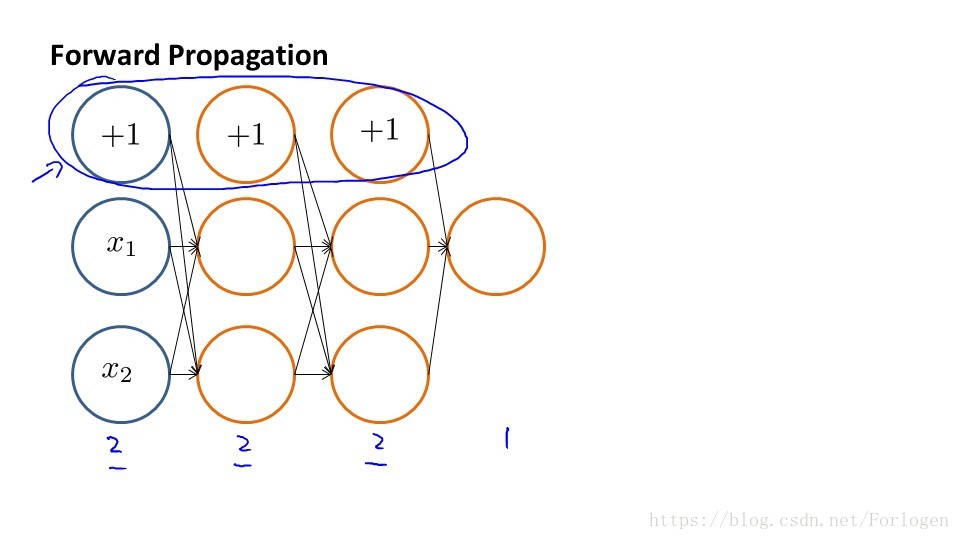
前向傳播演算法如上圖所示,假設訓練集只有一個例項(x1,y1),我們的神經網路有四層,輸出層有四個神經單元,具體的計算過程如圖所示。
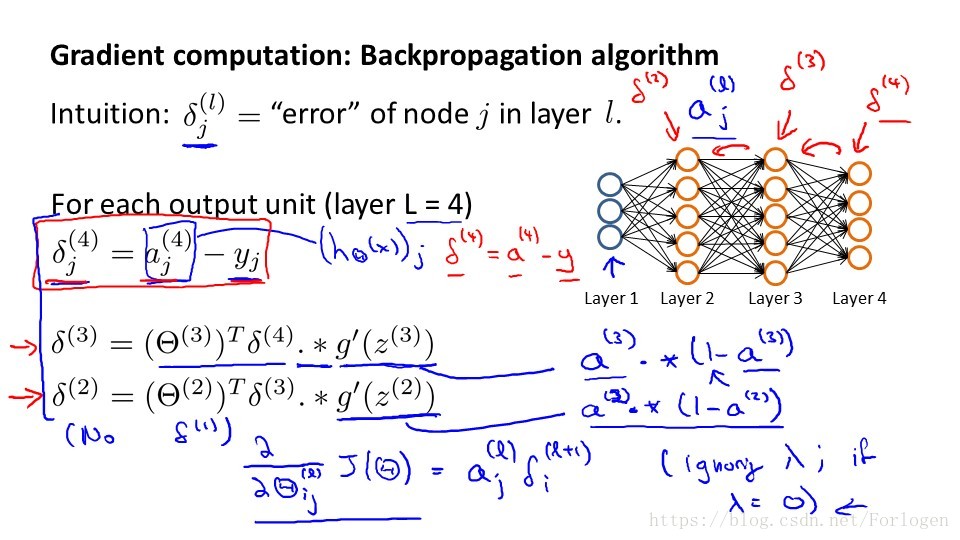
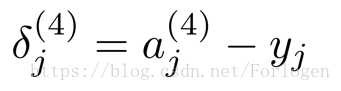
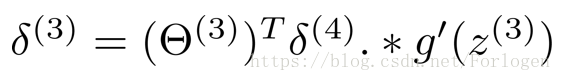
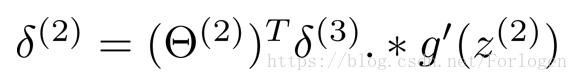
因為第一層就是我們的輸入層,沒有誤差這一說,所以不必計算。當我們將所有的誤差都計算出來後,便可以計算代價函式的偏導數, 假設我們不做歸一化處理,計算公式如下:
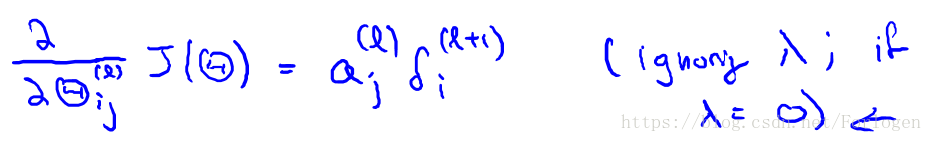
一般情況下,我們需要計算每一層的誤差單元,同樣我們需要為整個訓練集計算誤差單元,此時誤差單元也是矩陣,用
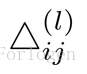
表示第l層的第i的神經單元受到第j個引數而導致的誤差,演算法虛擬碼如下:

三、Backpropagation intuition

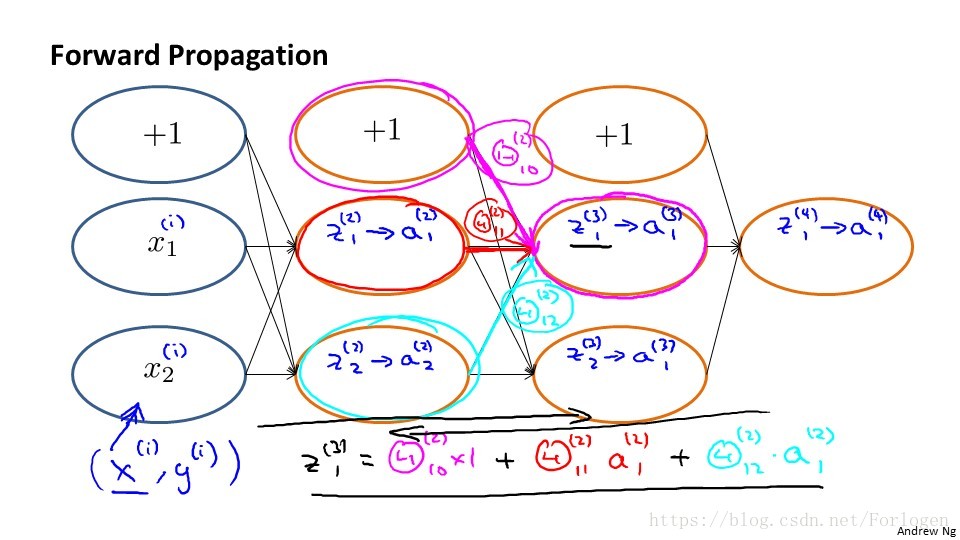




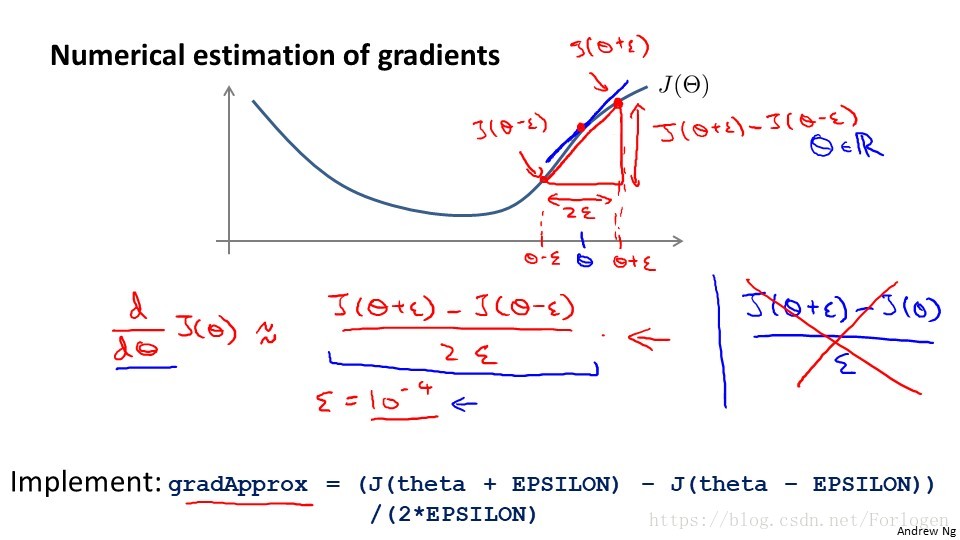
在神經網路等模型中使用梯度下降演算法計算時,如果在計算過程中出現了一些小的錯誤,雖然整體下降的趨勢不會改變,但是最後的結果卻不是最優解了。 為了解決這個問題,我們使用一種叫梯度檢驗的方法,它通過估計梯度值來檢驗我們計算的導數值 是不是我們需要的來實現。
四、梯度檢測


五、引數的初始化
隨機初始化,任何優化演算法的引數都需要一定的初始值,如果我們都設定為0或是相同的非零數,那麼下一層神經單元的計算值都將一樣,顯然是不可行的。 我們通常初始化為一個很小的範圍之間的隨機值。



六、總結
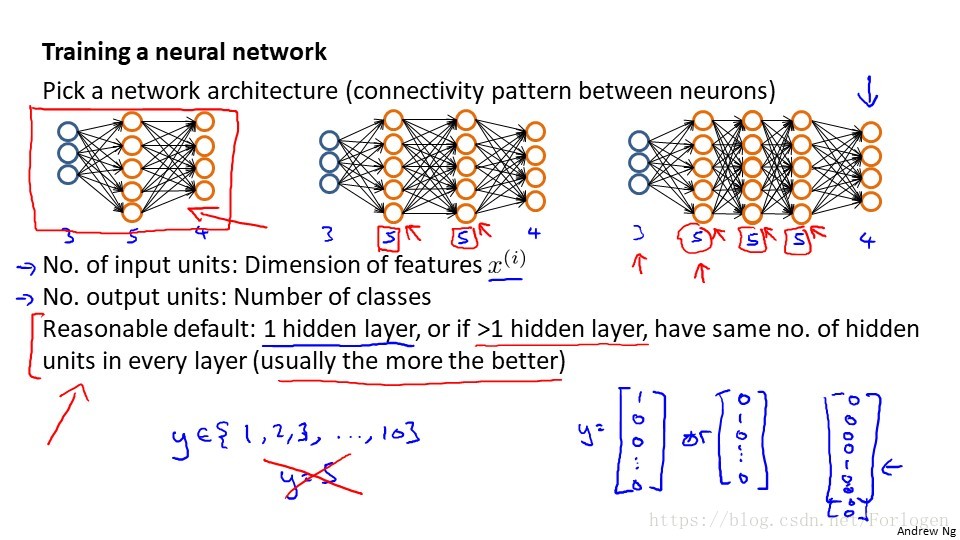
我們需要決定隱藏層的單元個數和每個中間層的單元數。

訓練神經網路的步驟如下: 1. 引數的隨機初始化 2. 利用正想傳播演算法計算所有的hθ(x) 3. 編寫計算代價函式的程式碼 4. 利用反向傳播演算法計算所有的偏導數 5. 利用數值檢驗方法檢驗這些偏導數 6. 使用優化演算法來最小化代價函式