論文筆記 "PFDet: 2nd Place Solution to Open Images Challenge 2018 Object Detection Track"
仔細一看是iwi神的文章.嚇死了.
#概要
PFDet獲得了Google AI Open Images Object Detection Track 2018 on Kaggle的第二名.
本文有三個貢獻.
-
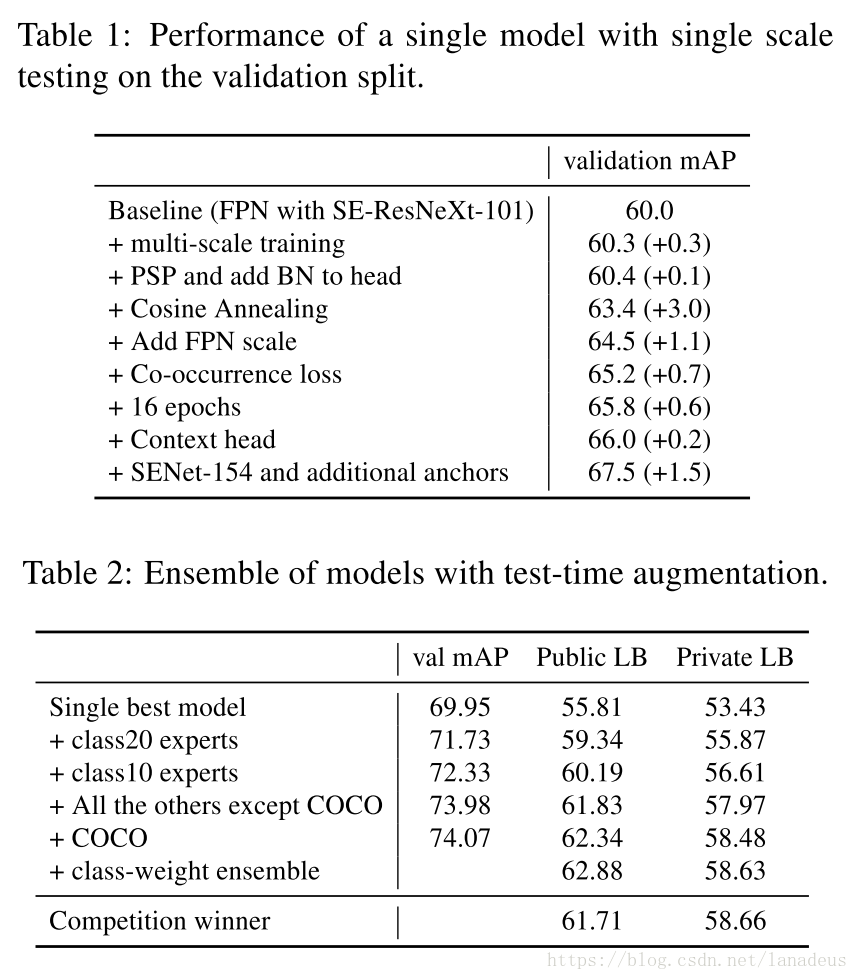
規模可變訓練(Training at Scale): 展示了使用batchsize=512,使用ChanerMN,在512個GPU上訓練物體檢測器(object detctor)的可行性.
-
共現loss(Co-occurrence Loss):
提出了同現loss來忽略被錯誤標註為假陰性(false negative)的物體例項(instances). 同現loss使用了預先提取的類內(class-wise)關係. -
專家模型(Expert Models):
展示了使用專家模型的有效性. 這對資料集裡的一些罕見類別特別有效.
#方法
##基本架構
-
基於2-stage的Faster R-CNN框架.
-
使用SE-ResNeXt / SENet作為backbone feature extractor.
-
為了更好地利用global context information, 使用了FPN(Feature Pyramid Networks) 和 PSP(Pyramid Spatial Pooling)模組.
-
為了增強context information,在把RoI放大為兩倍然後提取特徵,並在全連線層之前與原始RoI的特徵concat.
-
將原始FPN的4種scale增加至5種,以更好地聚合global context information
(***筆者吐槽: FPN的原始paper裡面明明就是5種scale,fpn2~fpn6,fpn6的scale最小,由fpn5下采樣而來. Detectron裡也是這麼實現的啊. 弟弟,你怎麼回事!***). -
BN (Batch normalization) 來加速網路收斂. 加在head和backbone之類的地方.
除此之外,為了增強BN效果,我們在FPN的top-down path中也加了BN層.
(筆者的貼心註釋:head指除了backbone的網路部分,比如faster head,fast head…) -
我們首先泛化一下ground truth標籤, 然後訓練CNN. 泛化(expand)的方法是,將某個類別看做是OID中的semantic hierarchy(語義層級)上的所有ancestor(祖先)類.
接著,我們把這個資料集看成是multi-label(多標籤)的, 對每一個類都用sigmoid交叉熵來搞搞.
當ground truth的類不是semantic hierarchy的葉子節點,我們就不用計算它的後代節點的sigmoid交叉熵loss了.
(筆者的腦補:sementic hierachy其實就是一個語義樹,類似wordnet/imagenet. 所有祖先類指的是某一個節點的所有祖先節點.比如交通工具其實就是汽車的祖先節點.) -
在測試時使用non-maximum weighted (NMW) suppression以去除重複的框. (筆者的幻想:就是nms的帶權版)
##同現loss
在OID資料集中, 標註比較隨意.雖然標註都是正確的,但是隻有"verified"的instances會被標註.
也就是說:有很多陽性樣本沒有被標註出來!
看下圖.

右邊的那個人沒有被標註身體部位,儘管"身體部位"存在於圖片中.
這就會帶來一個問題: 這個人的身體部位就會在訓練時被當成人臉的負樣本,這種標註的矛盾會造成模型的混亂,起碼會使得效能下降.
為了減輕這個問題,文章引入了同現loss.
這個loss的主要思想是: 對於類A, 若它和類B的關係已經非常(由很強的先驗知識)確定了,那麼我們就可以簡單地在訓練中忽略這些負樣本.
舉個例子.
如果我們有一個ground truth的bbox,類別是人,那麼我們有很強的自信說這個bbox裡面有人臉(筆者的註釋:原文如此.我覺得是起碼有人頭吧.)
這個神奇的loss要如何實現呢?
我們需要找到一些兩兩成對的類別,使得這些類別對滿足:
“在類別為X的ground truth bbox內部,可以忽略所有Y類的陰性proposal”.
如果一個類Y往往作為X類instances的附屬物存在,我們就可以考慮選擇這樣的類別對.
比如(視覺上來看): 輪胎是汽車的一部分, 牛仔褲往往是人的一部分.
##專家模型
OID中,類別極為不均衡. 這提高了模型學習一些罕見類的難度.
比如, 有238個類的標註少於1000張圖片. 然而, 最常見的類,也就是人,有807k張標註過的圖片. 我們fine-tune(微調)已在整個資料集上訓練過的模型來得到專家模型. 每個專家模型都是在所有類別的一個很小的子集上微調的.
##整合
最後的提交中,使用了在500個類上訓練的模型以及專家模型.我們取了所有模型輸出的並集然後再進行suppression.
各個模型各有擅長,我們根據驗證集的分數來分配各個模型在整合時的權重.
對每個模型 和類別 ,我們計算驗證集上 對 這個類的分數,據此計算模型的權重 .這個權重是用來乘上這個模型的分數輸出以得到加權輸出.
設所有模型在 類的平均得分為 .
,若模型
在
上的得分低於
;
否則,我們在
和1之間進行線性插值.
也就是說,
,其中
是模型
對類別
在驗證集上得分,
是所有模型中最高的
類得分.
#結果