
軟體工程作業.md
Word Count作業
二.專案簡介
該專案主要是模擬Linux上面的wc命令,基本要求如下:
命令格式:
wc.exe [para] <filename> [para] <filename> ... -o <filename>
功能:
wc.exe -c file.c:返回檔案file.c的字元數
wc.exe -w file.c:返回檔案file.c的單詞總數
wc.exe -l file.c:返回檔案file.c的總行數
wc.exe -o outputFile.txt:將結果輸出到指定檔案
要求:
-o後面必須跟一個檔案
-c -w -l可以同時出現
-c -w -l可以合併成-wcl,即命令可以連寫如果不指定輸出檔案,則將結果預設儲存在result.txt裡面
三.PSP2.1表格
| PSP2.1 | PSP階段 | 預估耗時(分鐘) | 實際耗時(分鐘) |
|---|---|---|---|
| Planning | 計劃 | 5 | 5 |
| · Estimate | · 估計這個任務需要多少時間 | 5 | 5 |
| Development | 開發 | 340 | 635 |
| · Analysis | · 需求分析(包括學習新技術) | 20 | 30 |
| · Design Spec | · 生成設計文件 | 30 | 30 |
| · Design Review | · 設計複審(和同事稽核設計文件) | 10 | 15 |
| · Coding Standard | · 程式碼規範(為目前的開發制定合適的規範) | 5 | 5 |
| · Design | · 具體設計 | 15 | 20 |
| · Coding | · 具體編碼 | 200 | 400 |
| · Code Review | · 程式碼複審 | 40 | 30 |
| · Test | · 測試(自我測試,修改程式碼,提交修改) | 20 | 30 |
| Reporting | 報告 | 60 | 50 |
| · Test Report | · 測試報告 | 20 | 15 |
| · Size Measurement | · 計算工作量 | 10 | 5 |
| · Postmortem & Process improvement Plan | · 事後總結,並提出過程改進計劃 | 30 | 30 |
| 合計 | 405 | 690 |
四.解題思路
由於自己對C語言比較熟悉(主要是C語言編譯過後就是exe,其他語言還要打包,就直接用C語言寫了),因此選擇用C語言來實現這個專案。剛拿到題的時候仔細分析了一下,發現在功能上的要求不高,甚至不用校驗單詞的有效性,凡是以空格和逗號隔開的都算是單詞,因此第一次作業的難點應該在於命令列引數的解析上面。
接下來我用C語言寫了一個簡單的demo,嘗試著梳理一下程式構建思路,應該如何設計,模組怎樣劃分。demo中所有的功能都在main函式裡面,沒有上傳到碼雲。
寫好demo後,大致整理了一下解題思路:
1.程式執行流程分析
根據專案的要求,該程式執行的大體流程為:首先使用者執行程式並附帶各種引數,程式首先要分析處理各種選項,校驗選項的有效性,並將各種引數和對應的檔案聯絡在一起,然後對不同的檔案執行該檔案對用的各種操作,然後將最終的結果一併儲存在輸出檔案中。
2.資料結構設計
根據對程式執行流程的分析,由於不同的檔案對應著不同的操作,因此需要將檔名和其對應的操作繫結在一起,由此想到了用結構體儲存一個檔案的相關資訊,然後使用連結串列將各個檔案連起來。待命令處理完畢後,只需遍歷連結串列,即可對各個檔案執行相應的操作。檔案的結構體如下:
struct Node
{
bool _c; // 是否統計字元個數
bool _w; // 是否統計單詞個數
bool _l; // 是否統計行數
bool _hasFile; //是否有正確的輸入檔案
char inFile[100]; //輸入檔案的路徑
int row; //行數
int character; // 字元數
int words; // 單詞數
struct Node *next;
};
3.模組劃分
根據程式的執行流程,可以將程式劃分為以下幾個模組:
(1).主函式
主函式中主要是一些基本的處理和一些簡單的邏輯的處理,負責呼叫其他函式
(2).命令處理模組
對於使用者輸入的命令的處理,有很多種辦法,其中最常用的就是遍歷陣列,或者將輸入的命令程式設計字串,然後解析字串,我選擇的是將使用者輸入的各種選項和命令拼接成一個字串,然後遍歷整個字串,並做相應的分析。
####(3).統計模組
統計模組主要就是對每個檔案做相應的統計操作,包括對行數的統計,對單詞數的統計,對字元數的統計,每個功能寫在一個單獨的函式裡面。統計完字元後順便將資料寫入檔案。
五.關鍵程式碼分析
1.命令處理函式
// 對使用者輸入的命令進行分析
// 傳入的使用者輸入的命令的字串,中間用空格隔開
// 如果是-開頭的,則認為是選項
// 如果檢測到-o,就立即讀取後面緊跟的輸出檔案
// 如果不是-開頭的,就認為是輸入檔案
// 第二個引數是一串檔案的頭結點
void analyseCommand(char commandStr[], struct Node *Head)
{
// 遍歷整個字串
initFileNode(Head);
struct Node *cur;
cur = Head;
for (int i = 0;; i++)
{
// 讀出當前字元
char c = commandStr[i];
// 如果遍歷到了\0,說明字串結束,則退出函式
if (c == 0)
return;
// 如果c是-,則應該是一個選項
if (c == '-')
{
i++;
// 讀取出-後面的字元,並做判斷
read:
c = commandStr[i];
// 如果-後面是c,就將_c置為true
if (c == 'c')
{
cur->_c = true;
if (commandStr[++i] != ' ')
{
goto read;
}
continue;
}
// 如果-後面是w,就將_w置為true
else if (c == 'w')
{
cur->_w = true;
if (commandStr[++i] != ' ')
{
goto read;
}
continue;
}
// 如果-後面是l,就將_l置為true
else if (c == 'l')
{
cur->_l = true;
if (commandStr[++i] != ' ')
{
goto read;
}
continue;
}
// 如果-後面是o,則後面緊跟的一個引數一定是filePath
// 首先判斷後面是否有檔案,如果有,就新增
// 如果沒有,就報錯
// 此時i的index是在選項上的
else if (c == 'o')
{
i += 2; // 將i移動到
char next = commandStr[i];
if (next == '-' || next == '0')
{
printf("after -o must a para");
exit(-1);
}
char path[100] = ""; // 用來存放輸出路徑
for (int j = 0;; j++)
{
// 讀取出命令中的檔名中的每一個字元
char ch = commandStr[i++];
// 如果讀取到了0,就說明檔名讀取結束,就退出
if (ch == ' ')
{
break;
}
path[j] = ch;
}
memset(outFile, 0, sizeof(outFile));
strcpy(outFile, path);
}
else
{
// 如果-後面什麼都沒有,就判定為錯誤
printf("after - must a para");
exit(-1);
}
}
else
{
// 如果不是-,則判定為輸入檔案
// 此時i定位在輸入檔案的第一個字元上
char path[100] = "";
for (int j = 0;; j++)
{
char ch = commandStr[i++];
if (ch == ' ')
{
break;
}
path[j] = ch;
}
strcpy(cur->inFile, path);
cur->_hasFile = true;
struct Node *fileNode;
fileNode = (struct Node *)malloc(sizeof(struct Node));
initFileNode(fileNode);
cur->next = fileNode;
cur = fileNode;
i--;
}
}
// 檢測是否有輸入檔案
// if (strlen(cur->inFile) == 0)
// {
// printf("you do not have input file");
// exit(-1);
// }
}
程式碼分析:該函式是這次作業中最重要的一個函式,因此單獨拿出來說一下。
要點說明:
1.使用for迴圈遍歷整個字串
2.遇到-之後就認為是一個選項,就緊接著讀取他的後一個字元,如果是有效引數,就記錄在當前檔案的結構體中,否則報錯
3.如果是-o,則認為後面緊跟著一個輸出檔案,不做檔名有效性檢驗,不做許可權檢查
4.如果是普通字元開頭,則認為是輸入檔案,不做檔名有效性檢查,不做許可權檢查
5.根據規則,輸出檔案應該放在該檔案對應引數的後面
6.遍歷完畢之後,就將相關資料都儲存在了檔案的結構體中,並連線成了連結串列,返回後可進行後期相關操作。
六.測試設計
根據要求,根據如下條件設計測試:
是否有輸入
是否輸入-
-後是否有引數
是否統計行數
是否統計字元數
是否統計單詞數
是否支援命令連寫
是否支援多檔案統計
是否有-o
-o後是否跟檔案
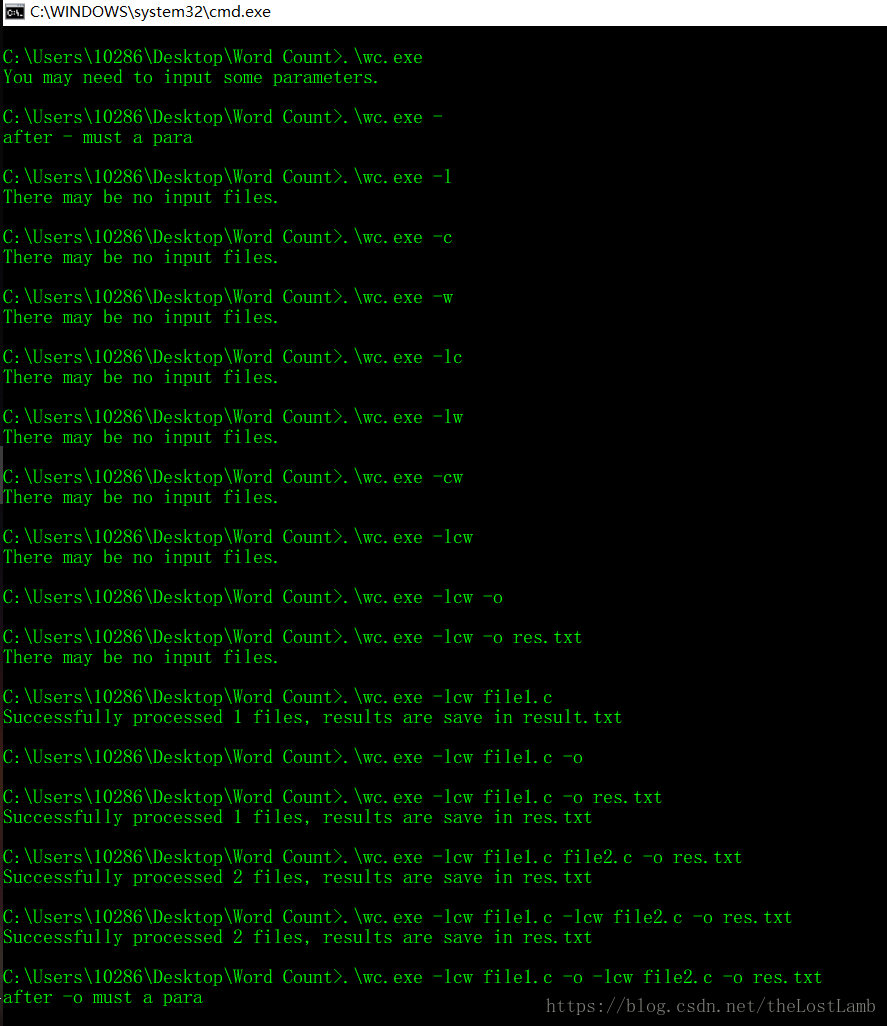
根據以上條件,設計瞭如下批處理檔案:
.\wc.exe
.\wc.exe -
.\wc.exe -l
.\wc.exe -c
.\wc.exe -w
.\wc.exe -lc
.\wc.exe -lw
.\wc.exe -cw
.\wc.exe -lcw
.\wc.exe -lcw -o
.\wc.exe -lcw -o res.txt
.\wc.exe -lcw file1.c
.\wc.exe -lcw file1.c -o
.\wc.exe -lcw file1.c -o res.txt
.\wc.exe -lcw file1.c file2.c -o res.txt
.\wc.exe -lcw file1.c -lcw file2.c -o res.txt
.\wc.exe -lcw file1.c -o -lcw file2.c -o res.txt
PAUSE
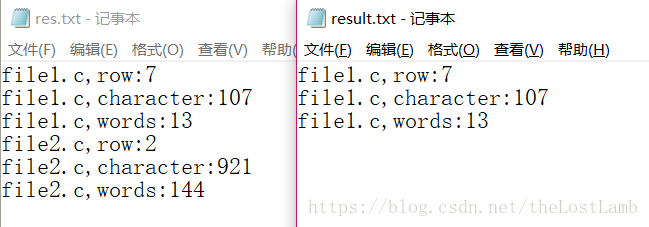
測試結果如下:
七.參考文獻
《構建之法–現代軟體工程》 --鄒新 [第三版]