
基於TensorFlow的車牌識別系統 (附程式碼)
1、簡介
過去幾周我一直在涉足深度學習領域,尤其是卷積神經網路模型。最近,谷歌圍繞街景多位數字識別技術釋出了一篇不錯的paper。該文章描述了一個用於提取街景門牌號的單個端到端神經網路系統。然後,作者闡述了基於同樣的網路結構如何來突破谷歌驗證碼識別系統的準確率。 為了親身體驗神經網路的實現,我決定嘗試設計一個可以解決類似問題的系統:車牌號自動識別系統。設計這樣一個系統的原因有3點:
- 我應該能夠參照谷歌那篇paper搭建一個同樣的或者類似的網路架構:谷歌提供的那個網路架構在驗證碼識別上相當不錯,那麼講道理的話,用它來識別車牌號應該也會很給力。擁有一個知名的網路架構將會大大地簡化我學習CNNs的步驟。
- 我可以很容易地生成訓練資料。訓練神經網路存在一個很大的問題就是需要大量的標籤樣本。通常要訓練好一個網路就需要幾十萬張標記過的圖片。僥倖的是,由於UK車牌號相對一致,所以我可以合成訓練資料。
- 好奇心。傳統的車牌號自動識別系統依賴於自己編寫演算法來實現車牌定位,標準化,分割和字元識別等功能。照這樣的話,實現這些系統的程式碼可能達到上千行。然而,我比較感興趣的是,如何使用相對較少的程式碼和最少的專業領域知識來開發一個不錯的系統。
2、輸入,輸出和滑窗
為了簡化生成的訓練圖片,減少計算量,我決定該網路可操作的輸入圖片為128*64的灰度圖。
選用128*64解析度的圖片作為輸入,對於基於適當的資源和合理的時間訓練來說足夠小,對於車牌號讀取來說也足夠大。

為了在更大的圖片中檢測車牌號,採用了一個多尺度的滑窗來解決。

右邊的圖片是神經網路的輸入圖片,大小為128*64,而左邊的圖片則展示了在原始輸入圖片的上下文中的滑窗。
對於每個滑窗,網路都會輸出:
- 輸入圖片中存在車牌的概率。(上邊動畫所顯示的綠框)
- 每個位置上的字元的概率,比如針對7個可能位置中的每一個位置,網路都應該返回一個貫穿36個可能的字元的概率分佈。(在這個專案中我假定車牌號恰好有7位字元,UK車牌號通常都這樣)
考慮一個車牌存在當且僅當:
- 車牌完全包含在圖片邊界內。
- 車牌的寬度小於圖片寬度的80%,且車牌的高度小於圖片高度的87.5%。
- 車牌的寬度大於圖片寬度的60%,或車牌的高度大於圖片高度的60%。
為了檢測這些號碼,我們可以利用一個滑窗,每次滑動8個畫素,而且在保證不丟失車牌的情況下提供一個縮放等級,縮放係數為2–√2,同時對於任何單個的車牌不會生成過量的匹配框。在後處理過程中會做一些複本(稍後解釋)。
3、合成圖片
為了訓練任何一個神經網路,必須提供一套擁有正確輸出的訓練資料。在這裡表現為一套擁有期望輸出的128*64大小的圖片。這裡給出一個本專案生成的訓練資料的例項:

期望輸出 HH41RFP 1

期望輸出 FB78PFD 1

期望輸出 JW01GAI 0(車牌部分截斷)

期望輸出 AM46KVG 0(車牌太小)

期望輸出 XG86KIO 0(車牌太大)

期望輸出 XH07NYO 0(車牌不存在)
期望輸出的第一部分表示網路應該輸出的號碼,第二部分表示網路應該輸出的“存在”值。對於標記過的資料不存在的情況我在括號裡作了解釋。
生成圖片的過程如下圖所示:
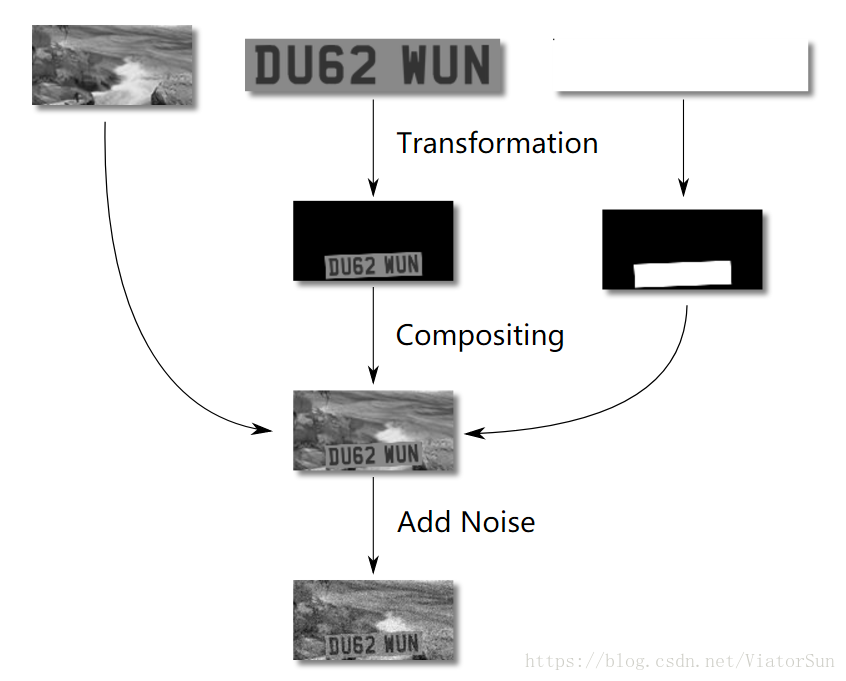
文字和車牌的顏色是隨機選擇的,但是文字顏色必須比車牌顏色更深一些。這是為了模擬真實場景的光線變化。最後再加入一些噪音,這樣不僅能夠解釋真實感測器的噪音,而且能夠避免過多依賴於銳化的輪廓邊界而看到的將會是離焦的輸入圖片。
擁有背景是很重要的,這意味著網路必須學習分辨沒有“欺騙”的車牌號邊界:使用一個黑色背景為例,網路可能會基於非黑色來學習分辨車牌的位置,這會導致分不清楚真實圖片裡的小汽車。
背景圖片來源於SUN database,裡面包含了超過10萬張圖片。重要的是大量的圖片可以避免網路“記住”背景圖片。
車牌變換採用了一種基於隨機滾轉、傾斜、偏轉、平移以及縮放的仿射變換。每個引數允許的範圍是車牌號可能被看到的所有情況的集合。比如,偏轉比滾轉允許變化更多(你更可能看到一輛汽車在拐彎而不是翻轉到一邊)。
生成圖片的程式碼相對較短(大約300行)。可以從gen.py裡讀取。
4、網路結構
使用的網路結構如下圖所示:
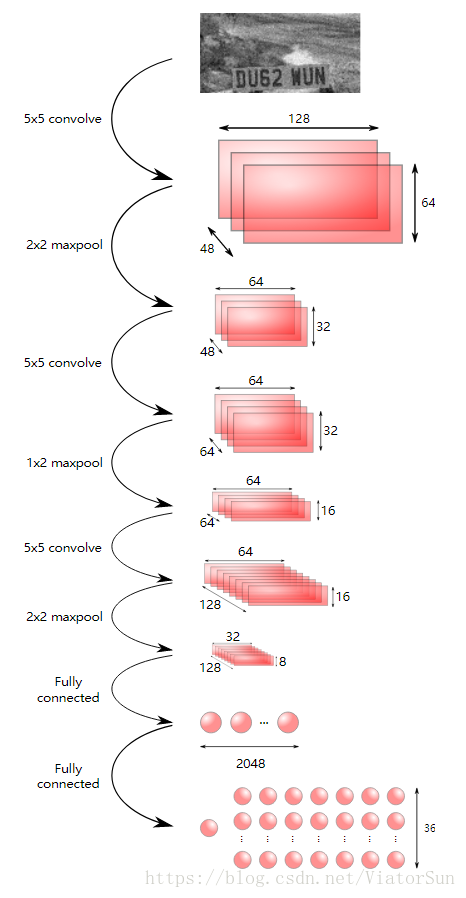
通過維基百科可以檢視CNN模組的介紹。上面的網路結構實際上是基於Stark的這篇paper,關於這個結構它比谷歌的那篇paper給出了更多的細節。
輸出層有一個節點(左邊)被用來作為車牌是否存在的指示器。剩下的節點用來編碼一個特定車牌號的概率:圖中的每一列與車牌號中的每一位號碼一致,每一個節點給出與存在的字元相符合的概率。例如,位於第2列第3行的節點給出車牌號中第二個號碼是字元c的概率。
除了輸出層使用ReLU啟用函式之外,所有層都採用深度神經網路的標準結構。指示存在的節點使用sigmoid啟用函式,典型地用於二值輸出。其他輸出節點使用softmax貫穿字元(結果是每一列的概率之和為1),是模型化離散概率分佈的標準方法。
定義網路結構的程式碼在model.py裡。
使用一塊nVidia GTX 970花費大約6小時來訓練(train.py),通過CPU的一個後臺程序來執行訓練資料的生成。
5、輸出處理
事實上為了從輸入圖片中檢測和識別車牌號,搭建了類似於上面的一個檢測網路,並採用了多位置和多尺度的128*64滑窗,這在滑窗那一節有所描述。
檢測網路和訓練網路的不同點在於最後兩層採用了卷積層而不是全連線層,這樣可以使檢測網路的輸入圖片大小不僅限於128*64。將一張完整的圖片以一種特定尺寸扔進網路中,然後返回一張每個“畫素”擁有一個存在/字元概率值的圖片。因為相鄰的滑窗會共享很多卷積特徵,所以將這些特定圖片捲進同一個網路可以避免多次計算同樣的特徵。
視覺化輸出的“存在”部分會返回如下所示的圖片:

圖上的邊界框是網路檢測存在車牌概率大於99%的區域。設定高閾值的原因是為了解釋訓練過程中引進的一個偏差:幾乎過半的訓練圖片都包含一個車牌,然而真實場景中有車牌的圖片很少見,所以如果設定閾值為50%的話,那麼檢測網路的假陽性就會偏高。
在檢測網路輸出之後,我們使用非極大值抑制(NMS)的方法來過濾掉冗餘的邊界框:

首先將重疊的矩形框分組,然後針對每一組輸出:
- 所有邊界框的交集
- 找出組中車牌存在概率最高的邊界框對應的車牌號
下圖所示文章最開始給出的那張車牌圖片的檢測結果:

哎呦,字元R被誤檢成了P。上圖中車牌存在概率最大的滑窗如下圖所示:

第一眼似乎以為這個對於檢測器來說是小菜一碟,然而事實證明這是過擬合的問題。下圖給出了生成訓練圖片時所用的車牌號中R的字型:

注意字元R腿的角度是如何不同於輸入圖片中字元R腿的角度。由於網路僅僅學習過上面的那種R字型,因此當遇到不同字型的R字元時就迷惑了。為了測試這種假設,我在GIMP中改進了圖片,使得其更接近於訓練時的字型:

改進之後,檢測得到了正確的輸出:

6、總結
我已經開源了一個擁有相對較短程式碼(大約800行)的系統,它不用匯入任何特定領域的庫以及不需要太多特定領域的知識,就能夠實現車牌號自動識別。此外,我還通過線上合成圖片的方法解決了上千張訓練圖片的需求問題(通常是在深度神經網路的情況下)。
另一方面,我的系統也存在一些缺點:
- 只適用於特定字型。
- 只適用於特定車牌號。尤其是,網路結構明確假定了輸出只有7個字元。
- 速度太慢。該系統執行一張適當尺寸的圖片要花費幾秒鐘。
為了解決第1個問題,谷歌團隊將他們的網路結構的高層拆分成了多個子網路,每一個子網路用於假定輸出號碼中的不同號碼位。還有一個並行的子網路來決定存在多少號碼。我覺得這種方法可以應用到這兒,但是我沒有在這個專案中實現。
關於第2點我在上面舉過例子,由於字型的稍微不同而導致字元R的誤檢。如果嘗試著檢測US車牌號的話,誤檢將會更加嚴重,因為US車牌號字型型別更多。一個可能的解決方案就是使得訓練資料有更多不同的字型型別可選擇,儘管還不清楚需要多少字型型別才能成功。
第3點提到的速度慢的問題是扼殺許多應用的cancer:在一個相當強大的GPU上處理一張適當尺寸的輸入圖片就要花費幾秒鐘。我認為不引進一種級聯式結構的檢測網路就想避開這個問題是不太可能的,比如Haar級聯,HOG檢測器,或者一個更簡單的神經網路。
我很有興趣去嘗試和其他機器學習方法的比較會怎樣,特別是姿態迴歸看起來有希望,最後可能會附加一個最基本的分類階段。如果使用了像scikit-learn這樣的機器學習庫,那麼應該同樣簡單。
總之,我使用單個CNN網路實現了一個車牌號檢測器/識別器,然而從效能方面來講,它還不能與傳統的手工(但更繁瑣的)管道線一較高下。