
Kafka學習筆記 --- Topic 與 offset
我們知道流處理平臺有以下三種特性:
* 可以讓你釋出和訂閱流式的記錄。這一方面與訊息佇列或者企業訊息系統類似。
* 可以儲存流式的記錄,並且有較好的容錯性。
* 可以在流式記錄產生時就進行處理。
Kafka適合什麼樣的場景?
它可以用於兩大類別的應用:
* 構造實時流資料管道,它可以在系統或應用之間可靠地獲取資料。 (相當於message queue)
* 構建實時流式應用程式,對這些流資料進行轉換或者影響。 (就是流處理,通過kafka stream topic和topic之間內部進行變化)
首先是一些概念:
Kafka作為一個叢集,執行在一臺或者多臺伺服器上.
Kafka 通過 topic 對儲存的流資料進行分類。
每條記錄中包含一個key,一個value和一個timestamp(時間戳)。
Kafka有四個核心的API:
The Producer API 允許一個應用程式釋出一串流式的資料到一個或者多個Kafka topic。
The Consumer API 允許一個應用程式訂閱一個或多個 topic ,並且對釋出給他們的流式資料進行處理。
The Streams API 允許一個應用程式作為一個流處理器,消費一個或者多個topic產生的輸入流,然後生產一個輸出流到一個或多個topic中去,在輸入輸出流中進行有效的轉換。
The Connector API 允許構建並執行可重用的生產者或者消費者,將Kafka topics連線到已存在的應用程式或者資料系統。比如,連線到一個關係型資料庫,捕捉表(table)的所有變更內容。
1.Topics和日誌
讓我們首先深入瞭解下Kafka的核心概念:提供一串流式的記錄—topic 。
Topic 就是資料主題,是資料記錄釋出的地方,可以用來區分業務系統。
Kafka中的Topics總是多訂閱者模式,一個topic可以擁有一個或者多個消費者來訂閱它的資料。
對於每一個topic, Kafka叢集都會維持一個分割槽日誌,如下所示:
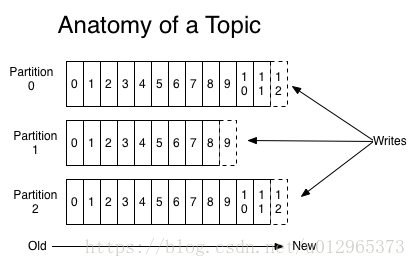
每個分割槽都是有序且順序不可變的記錄集,並且不斷地追加到結構化的commit log檔案。分割槽中的每一個記錄都會分配一個id號來表示順序,我們稱之為offset,offset用來唯一的標識分割槽中每一條記錄。
Kafka 叢集保留所有釋出的記錄—無論他們是否已被消費—並通過一個可配置的引數——保留期限來控制. 舉個例子, 如果保留策略設定為2天,一條記錄釋出後兩天內,可以隨時被消費,兩天過後這條記錄會被拋棄並釋放磁碟空間。Kafka的效能和資料大小無關,所以長時間儲存資料沒有什麼問題.
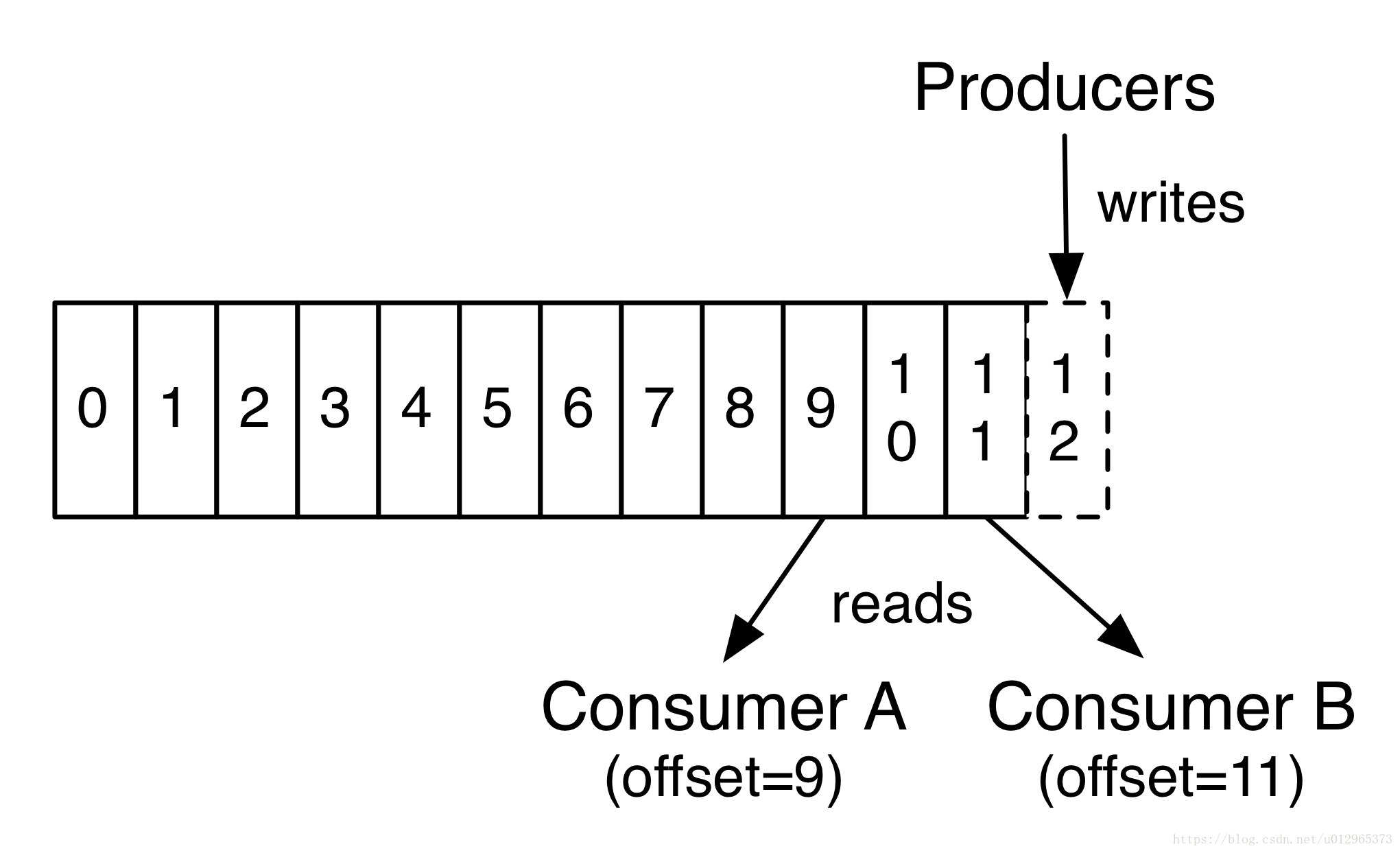
事實上,在每一個消費者中唯一儲存的元資料是offset(偏移量)即消費在log中的位置.偏移量由消費者所控制:通常在讀取記錄後,消費者會以線性的方式增加偏移量,但是實際上,由於這個位置由消費者控制,所以消費者可以採用任何順序來消費記錄。例如,一個消費者可以重置到一箇舊的偏移量,從而重新處理過去的資料;也可以跳過最近的記錄,從"現在"開始消費。
日誌中的 partition(分割槽)有以下幾個用途。第一,當日志大小超過了單臺伺服器的限制,允許日誌進行擴充套件。每個單獨的分割槽都必須受限於主機的檔案限制,不過一個主題可能有多個分割槽,因此可以處理無限量的資料。第二,可以作為並行的單元集—關於這一點,更多細節如下