
Fully Convolutional Instance-aware Semantic Segmentation論文解讀
進入2017年之後,深度學習計算機視覺領域有了新的發展。在以往的研究中,深度神經網路往往是單任務的,比如影象分類(AlexNet, VGG16等等),影象分割(以FCN為代表的一眾論文),目標檢測(R-CNN,Fast R-CNN和Fatser R-CNN,以及後來的YOLO和SSD,目標檢測領域已經實現多工)。而在最新的研究中,上述的任務往往被集成了,通過一個框架完成,代表就是例項分割。先來看看例項分割的例子:
第一個是戶外的測試結果:

第二個是檢測的泰迪熊:

大家可以看到,例項分割的效果一共有三點:
1. 將物體從背景中分離(測試結果上只是沒有畫出目標框),即目標檢測。
2. 對檢測到的物體進行逐畫素提取,即影象分割。
3. 對檢測到的物體進行類別劃分,即影象分類。
因此,例項分割是一個很綜合的問題,融合了目標檢測,影象分割與影象分類。例項分割的結果包含的資訊相當豐富,代表作包括Mask R-CNN與本文介紹的FCIS,前者是Facebook團隊貢獻的(Mask R-CNN的一作何凱明之前也供職於微軟),後者是是微軟的團隊貢獻的,下面,筆者就來分析一下FCIS。
首先,要達到“例項分割”效果,我們先來看一下以FCN為代表的傳統影象分割演算法有什麼問題:

上面的圖片是一張DeepLab論文中的效果圖,圖中的白色框和黃色框是筆者自己加上的。大家可以看到,如果是例項分割,在白色框的內部某些畫素會被分類成“person”,屬於前景,而剩餘的畫素則是背景。同樣地,在黃色框內,某些畫素會被劃分為"motorcycle",而其餘的畫素會被劃分為背景。那麼,在白色框與黃色框重複的區域,有些畫素的語義就出現了差池,如在白色框中是背景,在黃色框中是前景。對於這個問題,由於傳統的影象分割網路採用交叉熵,結合影象標籤端到端訓練,在標籤中,對於一個畫素點,語義類別是固定的,一個畫素點只能對應一種固定的語義,由於卷積的平移不變性,一個畫素點只能對應一種語義,因此沒有辦法達到例項分割的效果。
對於這個問題,論文中的闡述是:
However, conventional FCNs do not work for the instance-aware semantic segmentation task, which requires the detection and segmentation of individual object instances. The limitation is inherent. Because convolution is translation invariant, the same image pixel receives the same responses (thus classification scores) irrespective to its relative position in the context. However, instance-aware semantic segmentation needs to operate on region level, and the same pixel can have different semantics in different regions. This behavior cannot be modeled by a single FCN on the whole image.
那麼,現存的例項分割領域的方法是如何解決上面的問題呢?主要是通過多工網路來解決(Multi-task Network),筆者以Instance-aware Semantic Segmentation via Multi-task Network Cascades這篇代表作舉例(值得一提的是,這篇文章也是微軟團隊貢獻的,何凱明位居二作,發表於CVPR 2016)。多工網路是這樣做的:首先,通過卷積神經網路先提取初級特徵,並提出ROI(region of interest)。然後,對於每個ROI區域,通過ROI Warping和ROI Pooling提取出對應的特徵。接著,使用全連線層(FC layer)進行前景與背景的劃分(Mask Predictoin)。最後,再針對每一個ROI,使用全連線層(FC layer)進行影象分類。示意圖如下(該示意圖來自論文):

然後,我們來看一看上述的多工網路方法有什麼問題:
問題1:由於全連線層的輸入要求,所有ROI區域都要被轉化為相同的尺度,這對於不同尺度的目標(尤其是面積比較大的目標)來說,細節資訊損失巨大。大家都知道,全連線層的本質是矩陣乘法,因此需要相同尺度的輸入,才能和固定尺度的引數進行矩陣相乘得出結果。那麼,所有目標區域(ROI)都要被放大或者縮小成一樣的尺度(這個被稱為ROI-Pooling技術被Fast R-CNN提出,該論文發表於ICCV 2015,值得一提的是這也是微軟團隊的工作)。那麼,在前景與背景分離這個問題上面,對於面積大的目標區域,是將其縮小之後再進行分離,然後將得到的結果(Mask)放大到原來的尺度作為前景,這樣對ROI區域的操作非常容易損失掉目標的細節資訊(比如說,車子的輪子在縮小的過程中就沒了,再放大之後也不會再有)。
對於問題1,論文做出瞭如下表述:
First, the ROI pooling step losses spatial details due to feature warping and resizing, which however, is necessary to obtain a fixed-size representation for fc layers. Such distortion and fixed-size representation degrades the segmentation accuracy, especially for large objects.
問題2:全連線層引數規模龐大,這種尾大不掉的架構很有可能發生過擬合。從筆者的caffemodel解析這一篇博文中提到了,將一個簡單的LeNet模型的可訓練引數提取出來,最後兩個全連線的引數竟然達到了網路引數規模的90%以上。由於這個問題,訓練與測試的代價也會增多。
對於問題2,論文做出瞭如下表述:
Second, the fc layers over-parametrize the task, without using regularization of local weight sharing.
問題3:在ROI區域提出後,影象分割的子任務與影象分類的子任務之間沒有共享引數。大家從上圖可以看到,在圖示區域提出後,影象分割任務與影象分類任務都是各自訓練不同的全連線層,這樣使得架構的效率異常低下。
對於問題3,論文做出瞭如下表述:
Last, the per-ROI network computation in the last step is not shared among ROIs. As observed empirically, a considerably complex sub-network in the last step is necessary to obtain good accuracy. It is therefore slow for a large number of ROIs (typically hundreds or thousands of region proposals).
針對以上3個問題,我們來看看FCIS是怎麼解決的。
首先針對問題1,ROI-Pooling被取消了,取而代之的是對ROI區域的聚合,實質就是複製貼上。
然後針對問題2,全連線層(FC layer)被取消了,取而代之的是分類器(softmax)。
最後,針對問題3,影象分割與影象分類使用的是相同的特徵圖。
下面詳細講述一下FCIS的解決方案。
對於卷積層的平移不變性,本文采用的方法是生成若干組特徵圖(k×k組),但這個方法並不是FCIS的首創,而是在論文Instance-sensitive fully convolutional networks中提出,該篇論文發表於ECCV 2016。值得一提的是,這篇論文依然是微軟團隊的作品,何凱明依然是二作。該篇論文提出的方案採用瞭如下的做法:

對於每一張輸入圖片,生成k×k組特徵圖(在上圖的例子中k為3),每一組特徵圖,稱為score map。每一組score map,表示的是輸入影象中每一個ROI的不同位置的分數(score)。比如,左上角的一張score map,代表的就是輸入影象中每一個ROI中的左上角部分(標誌為1的小框內部)的score,其他的類推。score代表的含義是某個特定位置(小窗)的畫素點屬於ROI中的前景的分數。
那麼,這麼做有什麼好處呢?這樣做解決了卷積的平移不變性帶來的問題,使得不同ROI中的重疊區域在不同ROI中的score是不一樣的。見下圖所示:
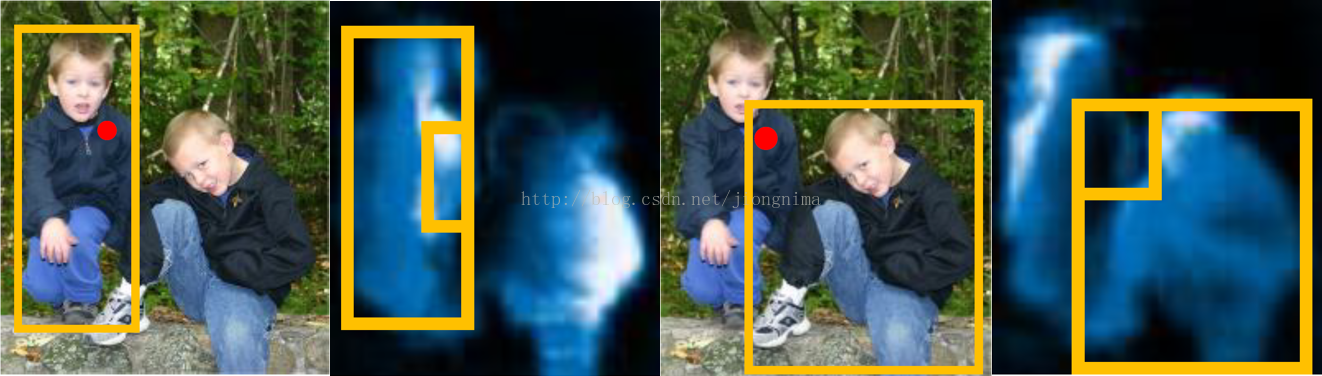
大家可以看到,輸入影象中的紅點區域被不同ROI共享,那麼,在不同的score map中,該區域對應的score完全不同。這就很好的實現了,相同區域,不同語義的問題。
那麼,這樣做可以解決影象分割這個子問題。可是,沒法解決影象分類的問題。對於影象分類的問題,目前的方案往往是採用一個後續的網路進行,也就是說,影象分割和影象分類的子任務還是串聯方式完成的,並沒有並聯。
針對上述的問題,FCIS是怎麼實現影象分類與影象分割的並聯呢?答案是通過兩類score map解決,一類叫inside score map,一類叫outside score map。inside score map表徵了畫素點在ROI區域內部中前景的分數,如果一個畫素點是位於一個ROI區域內部並且是目標(前景),那麼在inside score map中就應該有較高的分數,而在outside score map中就應該有較低的分數。反之亦然,如果一個畫素點是位於一個ROI區域內部並且是背景,那麼在inside score map中就應該有較低的分數,而在outside score map中就應該有較高的分數。針對影象分割,使用兩類score map,通過一個分類器就可以分出前景與背景。針對影象分類,將兩類score map結合起來,可以實現分類問題。
這樣做還有一個好處,通過兩類score map的結合,可以甄別出ROI檢測失誤的區域。

對於上面的描述,論文中的原句是:
For each pixel in a ROI, there are two tasks: 1) detection: whether it belongs to an object bounding box at a relative position (detection+) or not (detection-); 2) segmentation: whether it is inside an object instance’s boundary (segmentation+) or not (segmentation-).
大家可以看到,上圖中的left/right: position-sensitive inside/outside score maps,分別表示了所有ROI中的不同區域的inside/outside scores。為啥是所有ROI呢?因為這一系列score map是所有ROI共享的,大家可以留心上圖中從上到下三組inside/outside score maps(每組18張)都是相同的。
針對影象分割任務和影象分類任務的並行,FCIS這樣處理:
首先,對於每個ROI區域,將inside score maps和outside score maps中的小塊特徵圖複製出來,拼接成為了ROI inside map和ROI outside map。針對影象分割任務,直接對上述兩類map通過softmax分類器分類,得到ROI中的目標前景區域(Mask)。針對影象分類任務,將兩類map中的score逐畫素取最大值,得到一個map,然後再通過一個softmax分類器,得到該ROI區域對應的影象類別。在完成影象分類的同時,還順便驗證了ROI區域檢測是否合理,具體做法是求取最大值得到的map的所有值的平均數,如果該平均數大於某個閾值,則該ROI檢測是合理的。
針對輸入影象上的每一個畫素點,有三種情況:第一種情況是inside score高,outside score低;則該畫素點位於ROI中的目標部分。第二種情況是inside score低,outside score高,則該畫素點位於ROI中的背景部分。第三種情況是inside score和outside score都很低,那麼該畫素點不在任何一個ROI裡面。因此,我們在上一段中描述的,針對ROI inside map和ROI outside map中逐畫素點取最大值得到的影象:如果求平均後分數還是很低,那麼,我們可以斷定這個檢測區域是不合理的。如果求平均後分數超過了某個閾值,我們就通過softmax分類器求ROI的影象類別,再通過softmax分類器求前景與背景。
對於上面的闡述,論文中的原句如下:
Our joint formulation fuses the two answers into two scores: inside and outside. There are three cases: 1) high inside score and low outside score: detection+, segmentation+; 2) low inside score and high outside score: detection+, segmentation-; 3) both scores are low: detection-, segmentation-. The two scores answer the two questions jointly via softmax and max operations. For detection, we use max to differentiate cases 1)-2) (detection+) from case 3) (detection-). The detection score of the whole ROI is then obtained via average pooling over all pixels’ likelihoods (followed by a softmax operator across all the categories). For segmentation, we use softmax to differentiate cases 1) (segmentation+) from 2) (segmentation-), at each pixel. The foreground mask (in probabilities) of the ROI is the union of the per-pixel segmentation scores (for each category).
FCIS的架構如下所示:

影象輸入進來,經過卷積層提取初步特徵,然後利用這些特徵,一邊經過RPN(Region Proposal Network)網路提取ROI區域,一邊再經過一些卷積層生成2×(C+1)×k×k個特徵圖。2代表inside和outside兩類;C+1代表影象類別一共C類,再加上背景(未知的)1類;k×k代表每一類score map中各有k個(上圖的例子中k就為3)。在經過assembling之後(其實就是複製貼上),對於每一個ROI,k×k個position-sensitive score map被綜合成了一個,然後放小了16倍(長寬各變成1/4),得到2×(C+1)個特徵圖。然後開始並行操作,第一條線:對於每一類的ROI inside map和ROI outside map逐畫素取最大值,得到了C+1個特徵圖,對這C+1個特徵圖逐個求平均值,將平均值同閾值比較,若大於閾值,則判定該ROI合理,則直接送入softmax分類器進行分類,得到影象類別。若小於閾值,則不進行任何操作。第二條線:做C+1次softmax分類,對每一個類別得到前景與背景,然後根據第一條並行線的分類結果,選擇出對應類別的前景與背景劃分結果。
對於訓練過程,對於每一個ROI,loss由三部分組成,如下表述:
1. 在C+1類上面的分類loss(softmax loss)。
2. 對於positive ROI,有一個前景與背景的分類loss(softmax loss)。
3. 對於positive ROI,有一個包圍框迴歸的loss(L1 loss)(由Fast R-CNN提出)
positive ROI指的是,這個ROI與Ground Truth上面與其最近的目標包圍框重疊區域佔比在0.5以上。
論文中的表述如下:
Training: An ROI is positive if its box IoU with respect to the nearest ground truth object is larger than 0:5, otherwise it is negative. Each ROI has three loss terms in equal weights: a softmax detection loss over C + 1 categories, a softmax segmentation loss over the foreground mask of the ground-truth category only, and a bbox regression loss as in. The latter two loss terms are effective only on the positive ROIs.
看到這裡,大家千萬不要以為loss就此結束了,loss部分還缺了一大塊,這一大塊就是RPN,RPN在Faster R-CNN中被提出,主要目的是提出檢測區域。RPN的loss分成兩大部分,即
4. 分類loss(softmax loss),區分提出的ROI到底是前景還是背景。
5. 包圍框迴歸loss(L1 loss),目的是在粗糙程度上提出最合理的ROI。
對於RPN的表述,詳情請參考Faster R-CNN,本篇博文不再敘述。最後的總的目標函式分成五大部分,由於論文中沒有提到RPN的訓練,筆者特地去作者公開的程式碼中求證了一下,發現確實是直接繼承的Faster R-CNN的RPN。

訓練的細節上面,首先是使用了孔洞卷積(atrous convolution),並且使用SGD優化器端到端訓練。值得一提的是,使用了8塊GPU(K40)聯合訓練,每一塊GPU只能執行一個mini batch,由此來看,訓練成本還是比較高的。
實驗也體現出了比較好的效果,針對目前的現行的例項分割的方法,都有比較大的提升。


最後,給FCIS做個總結。
1.Techniques come and go, RPN stays eternal. 就是說,無論創新是怎麼樣的,RPN總是必須的。因為如果沒法提出ROI,之後的影象分割與影象分類的子任務就沒法進行。個人認為這也是微軟團隊引以為傲的地方,在Faster R-CNN中提出的RPN顛覆了以往的計算架構。
2.fully shared score maps for the object segmentation and detection sub-tasks 本方法使用的score maps,是針對影象分割與影象分類兩個子任務共享的,並且完全拋棄了全連線層,使得網路更加輕量,並且從整合的score map到最後的結果,沒有可訓練引數存在,存在的只是分類器。
3.inside/outside score maps 這樣的架構,使得影象分割與影象分類完全可以共享特徵圖。
博文到這裡,FCIS的解析就接近尾聲了,筆者想再說一些自己的思考:
深度學習發展到2017年,浪潮歷經5年時間。從最開始的小網路,單任務架構,發展到了整合模組,多工架構。這不僅得益於計算平臺的高速發展,同時也彰顯演算法發展速度迅猛。在這個過程中,團隊的力量尤其令人矚目,以目標檢測-例項分割為例,該領域已經幾乎被微軟團隊主宰。從早期的R-CNN,SSP,再到後來的Fast R-CNN,Faster R-CNN,FCIS,Mask R-CNN(前微軟)等,無一不體現出微軟團隊的強大實力。具體體現在演算法思想高明,計算框架科學,程式設計實現規範並且迅速(具體參閱這幾篇文章的微軟開原始碼)。因此,人工智慧時期還是以人為本的時期,團隊的力量尤其重要,在此再次向微軟深度學習團隊致敬,感謝他們引領了一個時代。