
Fully Convolutional Networks for Semantic Segmentation論文閱讀
FCN: Fully Convolutional Networks for Semantic Segmentation
作者:Jonathan Long, Evan Shelhamer ,Trevor Darrell
UC Berkeley
[pdf]—CVPR2015Best Paper
0. 簡介
本文將經典網路結構(AlexNet,VGG等)改為全卷積神經網路,通過有監督預訓練的方法端到端的完成image semantic segmentation這種畫素級任務,取得了 state- of-the-art segmentation of PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012)。文中利用skip connection結合深淺層資訊,使得分割結果更加精細,即解決semantics and location之間的矛盾。
a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations.
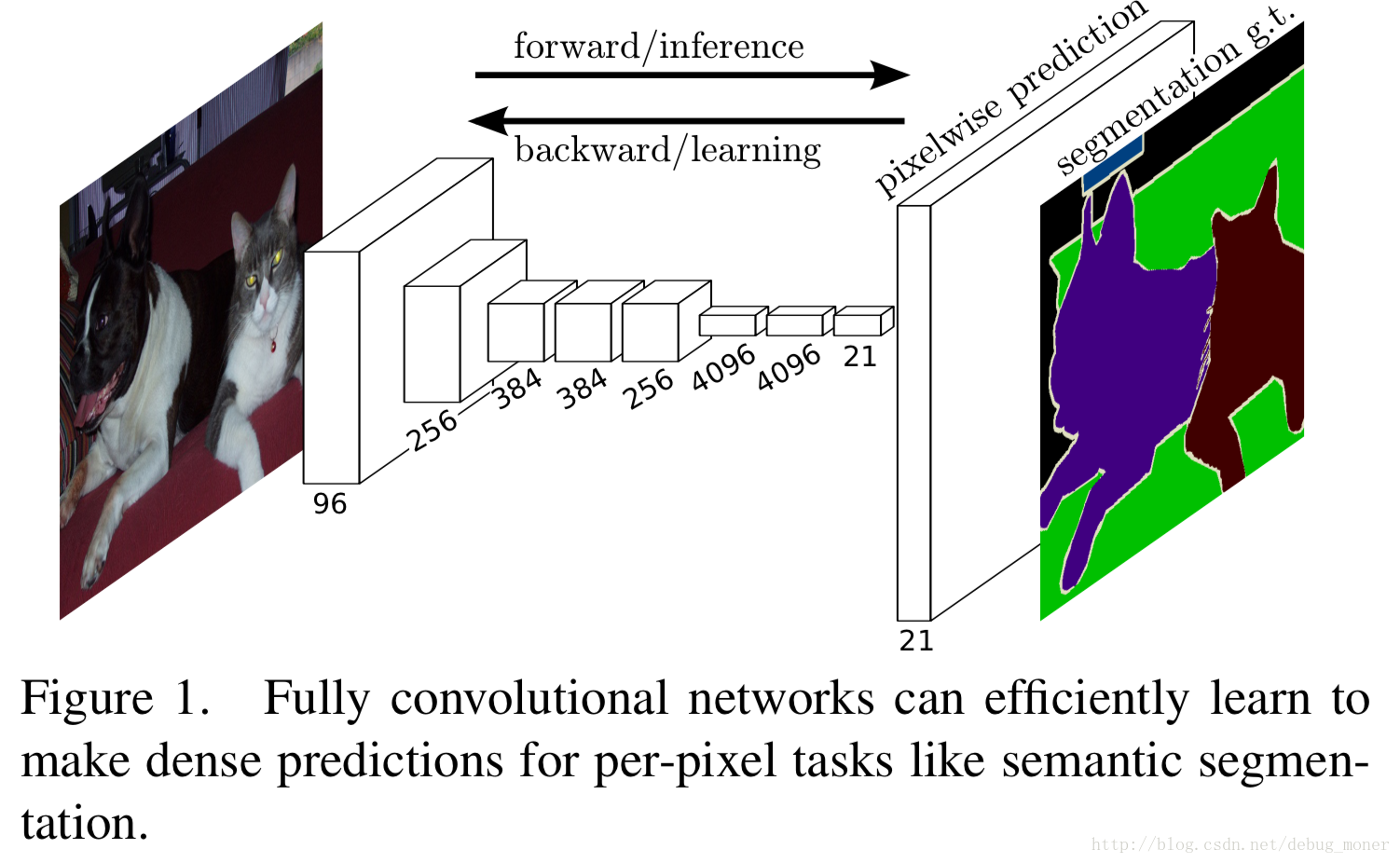
1.Fully convolutional networks定義
卷積神經網路中的常見層(卷積,池化,啟用函式)都是隻依賴於相對空間座標,記:
那麼
k是kernel size,s是stride,f決定層的型別。若上式中的函式形式經複合後保持相同的形式,且其kernel size和stride滿足下式如下變換規則:
這樣的網路叫做全卷積神經網路。全卷積網路(FCN)可以處理任意大小的輸入,併產生對應大小的輸出。計算損失函式時也與patchwise處理具有相同作用,如果損失函式是對最後一層所有空間維度損失函式的和,即:
3. Adapting classifiers for dense prediction
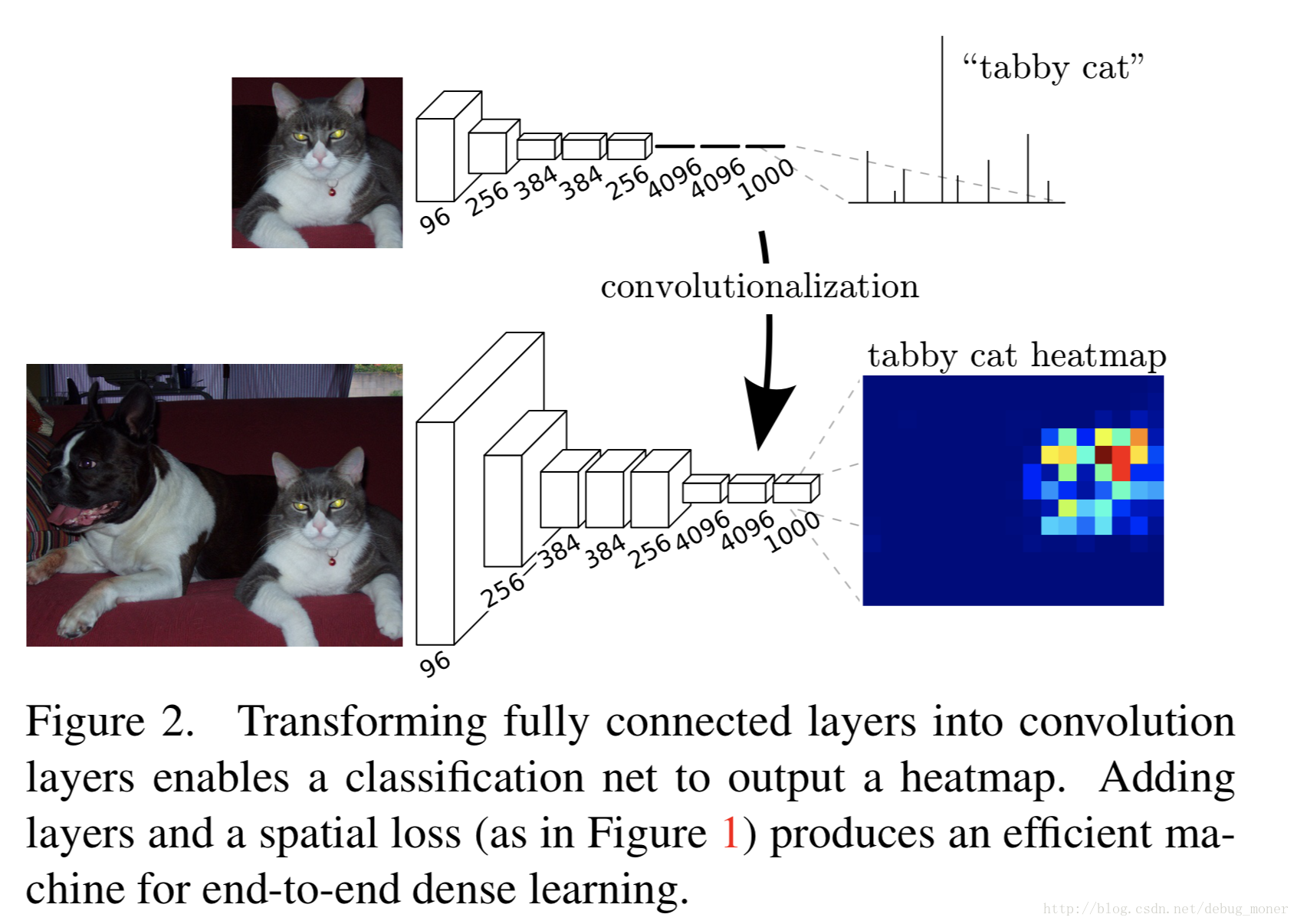
帶有全聯接層的網路結構要求input size是固定的,可以利用kernel size 定義為 feature map size大小的卷積來代替全連線網路,如上圖,第一個全連線改為4096個(6*6)的卷積,之後兩層定義為若干個1*1的卷積。這樣對於任意尺寸的輸入影象,都可以通過改變的網路計算得到相應的heatmap。
4.Upsampling is backwards strided convolution
為了完成從高層語義特徵到畫素類別的對映,作者應用了 deconvolution,文中作者提到了Decreasing subsampling 和shift-and-stitch trick方法,但是應用到網路中都是不同組成件的trade-off。其實插值法是deconvolution中的一個特例,文中指出反捲積中的引數不需要固定,引數也隨著訓練更新。
5. Segmentation Architecture
We decapitate each net by discarding the final classifier layer, and convert all fully connected layers to convolutions. We append a 1 × 1 convolution with channel dimension 21 to predict scores for each of the PASCAL classes (including background) at each of the coarse output locations, followed by a deconvolution layer to bilinearly upsample the coarse outputs to pixel-dense outputs.
作者實驗了幾種網路結構,實驗結果如下:
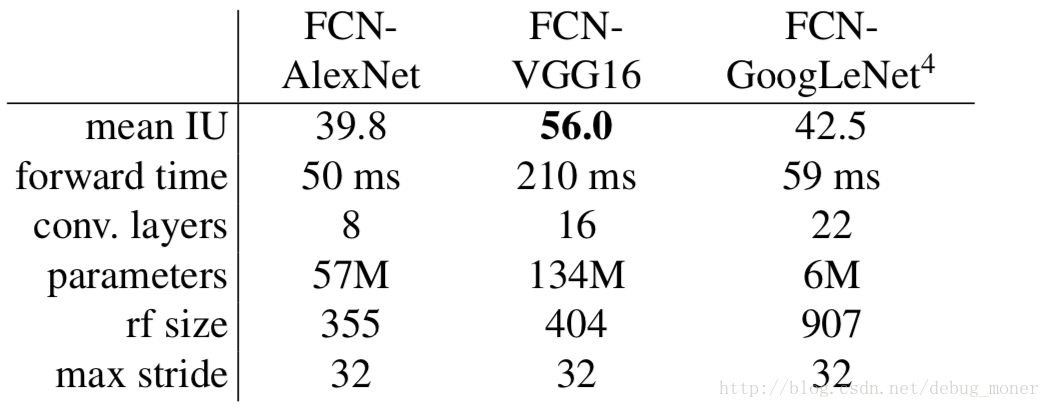
最終實驗網路為VGG-16。

FCN-32s直接將conv7的輸出進行反捲積上取樣到與輸入尺寸相同,最終得到的分割結果比較粗糙,作者提出要將高層語義資訊於淺層位置資訊結合的方法,得到FCN-16s,FCN-8s。FCN-16s將conv7進行上取樣2倍至pool4大小,然後將其進行相加,接著再上取樣16倍至輸入圖片大小;FCN-8s綜合了conv7,pool4,poo3的輸出,實驗證明這種結構效果最好。
實驗結果
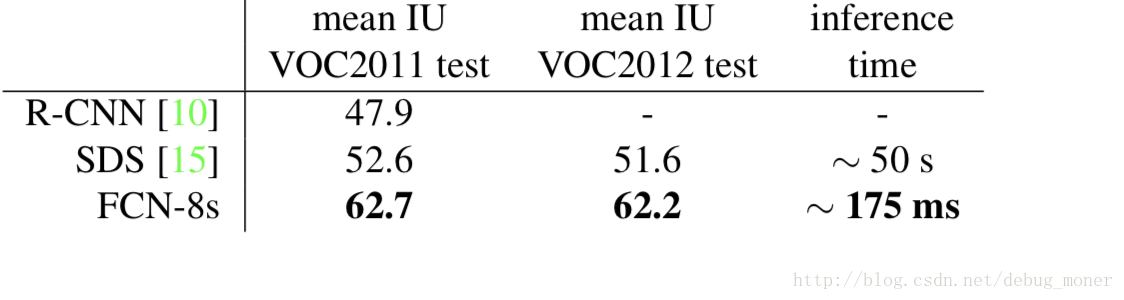
與其他方法對比,大幅度領先。
