
基於全卷積的影象語義分割—《Fully Convolutional Networks for Semantic Segmentation》
兩年前,我曾想做一個自動摳“人”的系統,目標是去除路人甲或者自動合成照片。當時“井底之蛙”般搞了一個混合高斯模型,通過畫素聚類的方式來摳“人”。這個模型,每跑一張小圖片需要幾分鐘,摳出來的前景“噪音”很嚴重,完全沒辦法使用。最後這個通過“摳人”去除路人甲的專案告吹。
兩年後的今天,這種“去除路人甲”的軟體好像早已經有了,並且笨妞也發現,換成現在的我,做一個效果好的“摳人”神器太容易了。下載deeplab最新的影象語義分割開源專案,並下載預訓練的模型,效果簡直不要太好。而是deeplab早期版本16年之前早就出來了,只是當時太無知(實際上,現在也很無知)。所以,科技在進步,我們這些底層的搬磚工還是得關注金字塔上層在搞什麼事情哦。
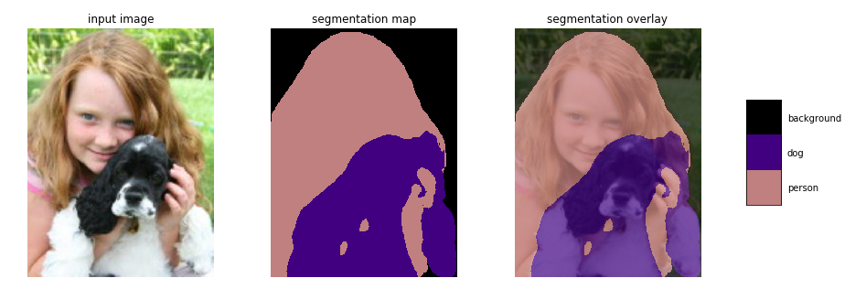
(圖1. deeplab v3+的影象語義分割效果)
好了,說了這麼多,回到今天的主題吧。今天不玩deeplab最新語義分割專案。今天學習基礎的語義分割——全卷積。
影象分割比較熱門的是語義分割和例項分割。語義分割的重點也是挑戰點有兩個方面——語義、位置,也就是分割出來的結果包含兩點:分割出了什麼(what),他們分別在影象中的具體位置(where),位置是畫素級別的。例項分割笨妞完全不瞭解,貌似比語義分割更進一步,除了what,where,貌似還得分清影象種每一類what各有幾個,分別在哪兒。



(圖2:分割原圖; 圖3:語義分割結果; 圖4: 例項分割結果)
笨妞瞭解語義影象分割從論文《Fully Convolutional Networks for Semantic Segmentation》入手,可能也止於這篇論文,畢竟不是做機器視覺的。原論文在
一、論文理解
從這篇論文中學到了兩點:1. .卷積神經網路從影象分類到影象分割的轉化過程; 2. 卷積轉置(反捲積)過程,淺層與深層的跳躍式組合結構。
1. 影象分類和影象分割的區別
影象分類是“影象與類別”的關係對映。輸入影象經過卷積神經網路層層深入,提取特徵,然後,這些特徵被全連線網路展平,通過softmax對映成各類別的概率,計算出影象的類別。

(圖5. 影象分類和影象分割的網路差別)
影象分割是“影象與影象”的關係對映,也可以理解為“畫素與畫素”的關係對映,要達成“畫素與畫素的對映”,目標的尺寸和輸入影象的尺寸就是一致的。但是,在卷積過程中,通常特徵圖的數量越來越多,但尺寸卻越來越小。於是,有了卷積的“逆向”過程。
2. 從影象分類到影象分割的過渡
卷積的逆轉要怎麼實現呢?卷積逆轉的目的是把卷積中池化變小的特徵圖再變大回來。卷積中,特徵圖變小主要是通過stride > 1的池化過程完成的,這種稱為下池化,也稱為池化過程下采樣。那麼問題來了,在卷積過程中,不做下采樣的池化不就可以了。然後,下采樣池化能夠帶來更好的泛化能力,不做下采樣,CNN的效果就沒那麼好了。不能不做下采樣,只能把下采樣變小的影象,再上取樣回來,個人理解,無論下采樣池化還是上取樣池化都能提高網路的泛化能力。
所以,卷積的逆轉重點在於上取樣池化。
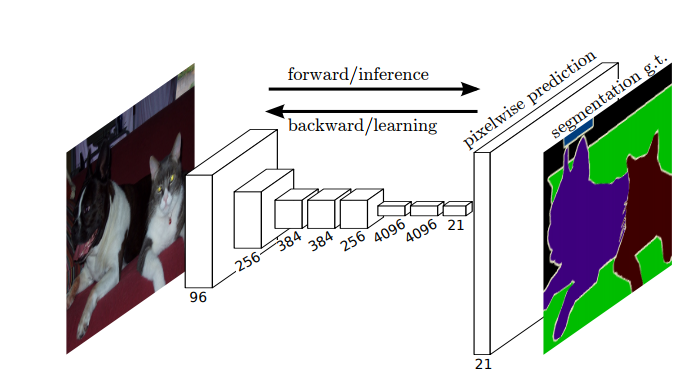
(圖7: 影象分割全卷積網路)
嘿嘿,作為資深模仿和調參黨,笨妞之前嘗試影象分類,基本都是運用vgg19、inception v3等現成的網路結構,然後載入imagenet預訓練後的模型(no-top),然後用自己的資料集再微調引數。畢竟,自己的資料集有限,計算力更有限,載入預訓練模型確實能更快滿足需求。
那麼,在FCN上,我們也是希望可以借用預訓練模型的引數的,怎麼借用呢?像VGGnet, 有3個全連線層呢,即便是no-top模型,依然還有兩個全連線層。通常有兩種辦法,以Vvgg16為例:A. 自己設計模型,5個CNN block和vgg16一樣,並逐層借用vgg16的引數,後面的就自己搞定了; B. 把n維的全連線層看做是尺寸為(1,n)的卷積核, 這樣,模型的前半段CNN過程,依然是5個CNN block和2個(1,n)卷積核的卷積層,整個vgg16的模型引數可以一起載入進模型。
3. 跳躍式結構
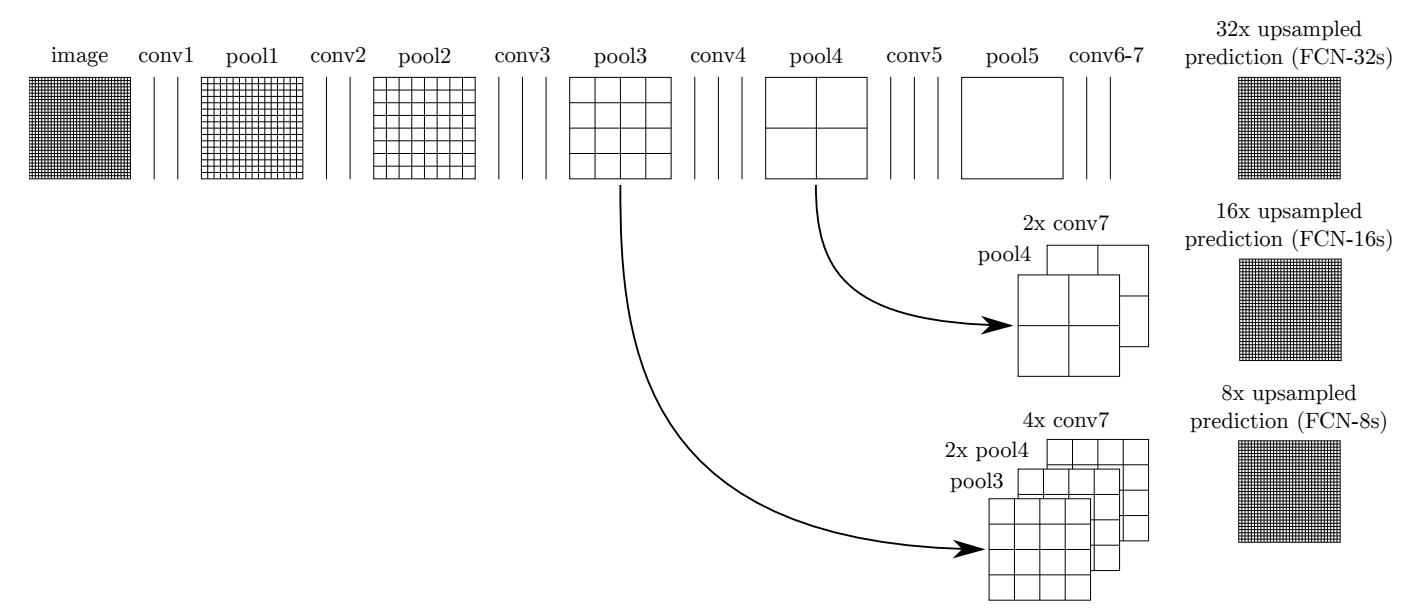
(圖8: 跳躍式結構)
個人對CNN的理解,層次越深時,特徵圖關注的點越區域性。論文作者設計這樣的結構目的就是將淺層的特徵和深層的特徵融合起來,達到特徵圖多尺度的目的,從而使“映射回影象”時,既關注細粒度的特徵嗎,也留住粗粒度的特徵。
vgg16 網路中,5個cnn block的特徵圖的下采樣尺寸是這樣2->4->8->16->32. 作者做了3個實驗,對比效果,第一種是“single-stream”,就是把前半段卷積的結果一次性上取樣回去,即32倍上取樣,作者把這種方式稱為FCN-32S。第二種是“two-stream”,將第4個CNN block的池化結果加入進來,第4個block的輸出需要16倍的上取樣,將16倍上取樣的結果和"single-stream”的結果融合,稱之為FCN-16S。第三種是“three-stream”,將第3個block的池化結果通過8倍上取樣,結果與“two-stram”的結果融合。
3種方式的結果是這樣的:
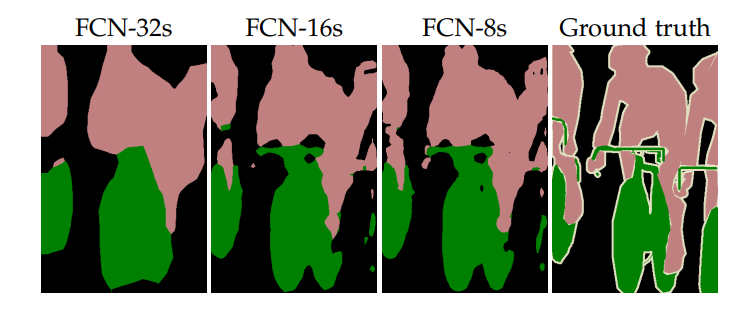
這種跳躍式結構比一次性暴力上取樣回去,效果好了很多。但是,比deeplvb最新的語義分割架構deeplab v3+還是要差很多。
二、 跑程式收穫
在讀完論文之後,笨妞一直以為影象分割就是輸入一張影象,然後輸出和ground truth影象直接作損失,然後,反向調節引數。在看了實現程式之後才明白,二分類的影象分割確實是這樣,但像PASCAL VOC這樣的資料集,有20類事物,實際上是1張輸入影象,對應ground truth生成的21張label圖。這樣一來,感覺影象分割還是有點分類的味道。
下面是程式和解析:
from keras.layers import merge, Input
from keras.layers.core import Activation
from keras.layers.convolutional import Convolution2D, Deconvolution2D, Cropping2D
from keras.models import Model
from keras.engine.topology import Layer
from keras.utils import np_utils, generic_utils
from keras import backend as K
from keras.applications.vgg16 import VGG16, preprocess_input,decode_predictions
from keras.utils.vis_utils import model_to_dot, plot_model
from keras.preprocessing import image
from keras.optimizers import Adam
from keras import backend as K
import cv2
import numpy as np
from PIL import Image
import h5py
class Softmax2D(Layer):
def __init__(self, **kwargs):
super(Softmax2D, self).__init__(**kwargs)
def build(self, input_shape):
pass
def call(self, x, mask=None):
e = K.exp(x - K.max(x, axis=1, keepdims=True))
s = K.sum(e, axis=1, keepdims=True)
return K.clip(e/s, 1e-7, 1)
def get_output_shape_for(self, input_shape):
return (input_shape)
class FullyConvolutionalNetwork():
def __init__(self, batchsize=1, img_height=224, img_width=224, FCN_CLASSES=21):
self.batchsize = batchsize
self.img_height = img_height
self.img_width = img_width
self.FCN_CLASSES = FCN_CLASSES
self.vgg16 = VGG16(include_top=False,
weights='imagenet',
input_tensor=None,
input_shape=(self.img_height, self.img_width, 3))
def create_model(self, train_flag=True):
#(samples, channels, rows, cols)
ip = Input(shape=(self.img_height, self.img_width, 3))
h = self.vgg16.layers[1](ip)
h = self.vgg16.layers[2](h)
h = self.vgg16.layers[3](h)
h = self.vgg16.layers[4](h)
h = self.vgg16.layers[5](h)
h = self.vgg16.layers[6](h)
h = self.vgg16.layers[7](h)
h = self.vgg16.layers[8](h)
h = self.vgg16.layers[9](h)
h = self.vgg16.layers[10](h)
# split layer
p3 = h
h = self.vgg16.layers[11](h)
h = self.vgg16.layers[12](h)
h = self.vgg16.layers[13](h)
h = self.vgg16.layers[14](h)
# split layer
p4 = h
h = self.vgg16.layers[15](h)
h = self.vgg16.layers[16](h)
h = self.vgg16.layers[17](h)
h = self.vgg16.layers[18](h)
p5 = h
#以上所有層都來自vgg16,初始化引數也來自imagenet預訓練的vgg16模型。
# get scores
#將第3個池化層的輸出拿出來,做卷積
p3 = Convolution2D(self.FCN_CLASSES, 1, 1, activation='relu', border_mode='valid')(p3)
#將第4個池化層的輸出拿出來,做卷積
p4 = Convolution2D(self.FCN_CLASSES, 1, 1, activation='relu')(p4)
#p4做2倍上取樣
p4 = Deconvolution2D(self.FCN_CLASSES, 4, 4,
output_shape=(self.batchsize, 30, 30, self.FCN_CLASSES),
subsample=(2, 2),
border_mode='valid')(p4)
#裁剪影象
p4 = Cropping2D(((1, 1), (1, 1)))(p4)
#將第5個池化層的輸出拿出來,做卷積
p5 = Convolution2D(self.FCN_CLASSES, 1, 1, activation='relu')(p5)
#p5做4倍上取樣
p5 = Deconvolution2D(self.FCN_CLASSES, 8, 8,
output_shape=(self.batchsize, 32, 32, self.FCN_CLASSES),
subsample=(4, 4),
border_mode='valid')(p5)
p5 = Cropping2D(((2, 2), (2, 2)))(p5)
# merge scores
#p3、p4、p5合併
h = merge([p3, p4, p5], mode="sum")
合併後做8倍上取樣。
h = Deconvolution2D(self.FCN_CLASSES, 16, 16,
output_shape=(self.batchsize, 232, 232, self.FCN_CLASSES),
subsample=(8, 8),
border_mode='valid')(h)
h = Cropping2D(((4, 4), (4, 4)))(h)
#2維softmax,生成21張二維影象
h = Softmax2D()(h)
return Model(ip, h)
#binarylab將ground truth按照內部的畫素值生成21張二值圖。
#這21張二值圖中,第一張為背景圖,背景的取值為1(白),前景取值為0(黑).
#後面的20張圖中,每種類別佔一張二值圖,如果groung truth中有該類別的區域,則在該張二值圖中,該區域為1,其他為0.
#如果ground truth中不包含該種類別,那麼對應的二值圖全為0(全黑)
def binarylab(labels, size, nb_class):
y = np.zeros((size,size,nb_class))
for i in range(size):
for j in range(size):
y[i, j,labels[i][j]] = 1
return y
def load_data(path, size=224, mode=None):
img = Image.open(path)
w,h = img.size
if w < h:
if w < size:
img = img.resize((size, size*h//w))
w, h = img.size
else:
if h < size:
img = img.resize((size*w//h, size))
w, h = img.size
img = img.crop((int((w-size)*0.5), int((h-size)*0.5), int((w+size)*0.5), int((h+size)*0.5)))
if mode=="original":
return img
if mode=="label":
y = np.array(img, dtype=np.int32)
mask = y == 255
y[mask] = 0
y = binarylab(y, size, 21)
y = np.expand_dims(y, axis=0)
return y
if mode=="data":
X = image.img_to_array(img)
X = np.expand_dims(X, axis=0)
X = preprocess_input(X)
return X
def generate_arrays_from_file(names, path_to_train, path_to_target, img_size, nb_class):
while True:
for name in names:
Xpath = path_to_train + "{}.jpg".format(name)
ypath = path_to_target + "{}.png".format(name)
X = load_data(Xpath, img_size, mode="data")
y = load_data(ypath, img_size, mode="label")
yield (X, y)
def crossentropy(y_true, y_pred):
return -K.sum(y_true*K.log(y_pred))
import argparse
parser = argparse.ArgumentParser(description='FCN via Keras')
parser.add_argument('--train_dataset', '-tr', default='dataset', type=str)
parser.add_argument('--target_dataset', '-ta', default='dataset', type=str)
parser.add_argument('--txtfile', '-t', type=str, required=True)
parser.add_argument('--weight', '-w', default="", type=str)
parser.add_argument('--epoch', '-e', default=100, type=int)
parser.add_argument('--classes', '-c', default=21, type=int)
parser.add_argument('--batchsize', '-b', default=32, type=int)
parser.add_argument('--lr', '-l', default=1e-4, type=float)
parser.add_argument('--image_size', default=224, type=int)
args = parser.parse_args(['--epoch', '5',
'--train_dataset', 'image/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/JPEGImages/',
'--txtfile', 'image/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/ImageSets/Segmentation/train.txt',
'--target_dataset', 'image/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/SegmentationClass/'])
img_size = args.image_size
nb_class = args.classes
path_to_train = args.train_dataset
path_to_target = args.target_dataset
path_to_txt = args.txtfile
batch_size = args.batchsize
with open(path_to_txt,"r") as f:
ls = f.readlines()
names = [l.rstrip('\n') for l in ls]
nb_data = len(names)
FCN = FullyConvolutionalNetwork(img_height=img_size, img_width=img_size, FCN_CLASSES=nb_class)
adam = Adam(lr=args.lr)
train_model = FCN.create_model(train_flag=True)
train_model.compile(loss=crossentropy, optimizer='adam')
if len(args.weight):
model.load_weights(args.weight, model)
print("Num data: {}".format(nb_data))
train_model.fit_generator(generate_arrays_from_file(names,path_to_train,path_to_target,img_size, nb_class),
samples_per_epoch=nb_data,
nb_epoch=args.epoch)
if not os.path.exists("weights"):
os.makedirs("weights")
train_model.save_weights("weights/temp", overwrite=True)
f = h5py.File("weights/temp")
layer_names = [name for name in f.attrs['layer_names']]
fcn = FCN.create_model(train_flag=False)
for i, layer in enumerate(fcn.layers):
g = f[layer_names[i]]
weights = [g[name] for name in g.attrs['weight_names']]
layer.set_weights(weights)
fcn.save_weights("weights/fcn_params", overwrite=True)
f.close()
os.remove("weights/temp")
print("Saved weights")不知道是怎麼搞得,我跑這個網路的時候,loss一直不下降。從網上搜了下,有很多這樣的情況,笨妞按照他們的方法修改了,但是,loss還是不動,就像網路根本沒有被訓練一樣。暫時只能不糾結這個問題了。後面有機會再看看吧。