
Java 資料結構和演算法 - 檔案壓縮
Java 資料結構和演算法 - 檔案壓縮
假設你有一個檔案,只包含下列字元:a、e、i、s、t、空格(sp)和換行符(nl)。而且,檔案裡有10個a,15個e,12個i,3個s,4個t,13個空格和1個換行符。下圖所示,可以用157位代表該檔案-一共58個字元,每個字元3位。

實際的檔案可能很大。很多大檔案使用的最頻繁的字元和最少用的字元通常有很大的差異。例如,很多大的資料檔案有很多數字、空格和換行符,但是很少有q和x。
很多情況下,希望減小檔案的大小。減少資料的位數叫做壓縮,實際上可以分成兩個階段:編碼階段和解碼階段。下面要討論的辦法,可以節省一些大檔案的25%的空間,對於一些大的資料檔案,甚至能減少50%-60%的空間。
一般策略是允許編碼(code)的長度因字元而異-高頻使用的字元有短編碼。如果所有字元的使用頻率差不多,就節省不了多少空間。
prefix codes
前面的二進位制編碼可以用下面的二叉樹表示。字元都儲存在葉子節點,從根開始,沿著路徑可以找到任何葉子。如果左枝是0,右枝是1,s的編碼就是011。如果字元ci的深度是di,出現過fi次,編碼的成本(cost)是∑difi。

因為nl是唯一的孩子,上圖可以有更好的編碼。用nl節點替換它的父,得到下圖。新的成本是173,還有很大的優化空間。

上面的數是完全樹-所有的節點要不是葉子,要不就有兩個兒子。一個優化的成本有這樣的屬性。如果字元都放在葉子節點,任何位序列都能被明確地編碼。
比如,假設編碼串是0100111100010110001000111。上圖顯示,0和01不是字元編碼,而010代表i,所以第一個字元是i。然後011是s,11是nl。剩餘的編碼是a、sp、t、i、e和nl。
字元編碼可以有不同的長度,只要沒有一個字元編碼是另一個字元編碼的字首,這編碼就叫做字首碼。飯過來,如果字元位於非葉子節點,就不能被明確地編碼了。
這樣,我們的基本問題就是找到最小成本的完全二叉樹,其中所有的字元都在葉子上。下圖是一個優化。編碼只需要146位。通過交換孩子,有多種優化編碼。


哈夫曼演算法
編碼系統的演算法是Huffman在1952年提出的。它通過重複合併樹構造優化的字首碼,獲得整個樹。
假設字元的數量是C。在哈夫曼演算法裡我們維護一個樹的森林。一棵樹的weight是葉子次數的總和。C-1次,兩棵樹,T1和T2,選擇最小的weight,任意打破關係,由子樹T1和T2形成新樹。在演算法的開始,有C個單節點的樹,在演算法結束的時候,得到一個優化的哈夫曼樹。
下圖是一個初始森林,每棵樹的weight顯示在根的左上角。

然後合併weight最小的兩棵樹。新的根是T1。任意選擇左節點。新樹的weight就是舊樹的weight的和。
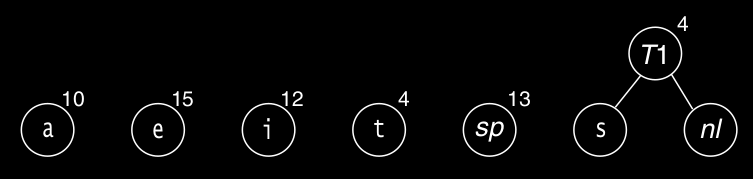
現在有六棵樹,我們再次選擇weight最小的兩棵樹,T1和t。合併成新樹T2,weight是8。

第三步合併T2和a,增加T3,weight是18。

現在weight最小的兩棵樹都是單節點的,i和sp。合併他倆。生成T4。

然後合併e和T3。

最後一步

實現
現在實現哈夫曼編碼演算法,不做任何重大優化,只想能解決問題。
先定義要使用的常量。我們要維護一個樹節點的優先佇列(priority queue)。
interface BitUtils {
public static final int BITS_PER_BYTES = 8;
public static final int DIFF_BYTES = 256;
public static final int EOF = 256;
}
除了標準I/O類,我們的程式由其他幾個類組成。因為我們需要執行bit-at-a-time I/O,我們要實現位輸入和位輸出流的包裝類。還要寫其他類維護字元數量,增加和返回哈夫曼編碼樹的資訊。最後,我們寫壓縮和解壓縮流的包裝類。總共寫這些類
- BitInputStream:包裝Inputstream,提供一個bit-at-a-time輸入
- BitOutputStream:包裝Outputstream,提供一個bit-at-a-time輸出
- CharCounter:維護字元數量
- HuffmanTree:操作哈夫曼編碼樹
- HZIPInputStream:解壓縮的包裝類
- HZIPOutputStream:壓縮的包裝類
位輸入和位輸出流類
BitInputStream和BitOutputStream類似,都包裝了一個流。流的引用儲存成一個私有的資料成員。
BitInputStream的每八個readBit能從底層流讀一個位元組。讀取的位元組儲存在buffer內,bufferPos指示還有多少未使用的buffer。
import java.io.IOException;
import java.io.InputStream;
public class BitInputStream {
private InputStream in;
private int buffer;
private int bufferPos;
public BitInputStream(InputStream is) {
in = is;
bufferPos = BitUtils.BITS_PER_BYTES;
}
//Read one bit as a 0 or 1
public int readBit() throws IOException {
////whether the bits in the buffer have already been used
if (bufferPos == BitUtils.BITS_PER_BYTES) {
//get 8 more bits
buffer = in.read();
if (buffer == -1)
return -1;
//reset the position indicator
bufferPos = 0;
}
return getBit(buffer, bufferPos++);
}
//Close underlying stream
public void close() throws IOException {
in.close();
}
private static int getBit(int pack, int pos) {
return (pack & (1 << pos)) != 0 ? 1 : 0;
}
}
BitOutputStream的每八個writeBit能向底層流寫一個位元組。它提供flush方法是因為一系列地呼叫writeBit以後,可能有資料還留在buffer內。
當呼叫writeBit填充buffer以後,或者呼叫close方法的時候,就呼叫flush方法。
import java.io.IOException;
import java.io.OutputStream;
public class BitOutputStream {
private OutputStream out;
private int buffer;
private int bufferPos;
public BitOutputStream(OutputStream os) {
bufferPos = 0;
buffer = 0;
out = os;
}
//Write one bit (0 or 1)
public void writeBit(int val) throws IOException {
buffer = setBit(buffer, bufferPos++, val);
if (bufferPos == BitUtils.BITS_PER_BYTES)
flush();
}
//Write array of bits
public void writeBits(int[] val) throws IOException {
for (int v : val)
writeBit(v);
}
//Flush buffered bits
public void flush() throws IOException {
if (bufferPos == 0)
return;
out.write(buffer);
bufferPos = 0;
buffer = 0;
}
//Close underlying stream
public void close() throws IOException {
flush();
out.close();
}
private int setBit(int pack, int pos, int val) {
if (val == 1)
pack |= (val << pos);
return pack;
}
}
字元計數類
獲取一個輸入流的字元數。另外,字元數量能被手動設定,以後再獲取(認為8位是一個字元)。
public class CharCounter {
private int[] theCounts = new int[BitUtils.DIFF_BYTES + 1];
public CharCounter() {
}
public CharCounter(InputStream input) throws IOException {
int ch;
while ((ch = input.read()) != -1)
theCounts[ch]++;
}
//Return # occurrences of ch
public int getCount(int ch) {
return theCounts[ch & 0xff];
}
//Set # occurrences of ch
public void setCount(int ch, int count) {
theCounts[ch & 0xff] = count;
}
}
哈夫曼樹類
樹是節點的集合。每個節點有它的左、右孩子和父的連線。
public class HuffNode implements Comparable<HuffNode> {
public int value;
public int weight;
public int compareTo(HuffNode rhs) {
return weight - rhs.weight;
}
HuffNode left;
HuffNode right;
HuffNode parent;
HuffNode(int v, int w, HuffNode lt, HuffNode rt, HuffNode pt) {
value = v;
weight = w;
left = lt;
right = rt;
parent = pt;
}
}
我們可以通過一個CharCounter物件增加HuffmanTree物件-立刻構造樹。也可以不用CharCounter增加HuffmanTree-等呼叫readEncodingTable的時候,讀取字元數,構造樹。
HuffmanTree類提供了writeEncodingTable方法,把樹寫到一個輸出流。
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import java.util.PriorityQueue;
public class HuffmanTree {
//can be used to initialize the tree nodes
private CharCounter theCounts;
//maps each character to the tree node that contains it
private HuffNode[] theNodes = new HuffNode[BitUtils.DIFF_BYTES + 1];
//the root node of the tree
private HuffNode root;
public static final int ERROR = -3;
public static final int INCOMPLETE_CODE = -2;
public static final int END = BitUtils.DIFF_BYTES;
public HuffmanTree() {
theCounts = new CharCounter();
root = null;
}
public HuffmanTree(CharCounter cc) {
theCounts = cc;
root = null;
createTree();
}
/**
* Return the code corresponding to character ch.
* (The parameter is an int to accomodate EOF).
* If code is not found, return an array of length 0.
*/
public int[] getCode(int ch) {
HuffNode current = theNodes[ch];
if (current == null)
return null;
String v = "";
HuffNode par = current.parent;
while (par != null) {
if (par.left == current)
v = "0" + v;
else
v = "1" + v;
current = current.parent;
par = current.parent;
}
//Codes are represented by an int[]
//each element is either a 0 or 1
int[] result = new int[v.length()];
for (int i = 0; i < result.length; i++)
result[i] = v.charAt(i) == '0' ? 0 : 1;
return result;
}
/**
* Get the character corresponding to code.
*/
public int getChar(String code) {
HuffNode p = root;
for (int i = 0; p != null && i < code.length(); i++)
if (code.charAt(i) == '0')
p = p.left;
else
p = p.right;
if (p == null)
return ERROR;
return p.value;
}
/**
* Writes an encoding table to an output stream.
* Format is character, count (as bytes).
* A zero count terminates the encoding table.
*/
public void writeEncodingTable(DataOutputStream out) throws IOException {
for (int i = 0; i < BitUtils.DIFF_BYTES; i++) {
if (theCounts.getCount(i) > 0) {
out.writeByte(i);
out.writeInt(theCounts.getCount(i));
}
}
out.writeByte(0);
out.writeInt(0);
}
/**
* Read the encoding table from an input stream in format
* given above and then construct the Huffman tree.
* Stream will then be positioned to read compressed data.
*/
public void readEncodingTable(DataInputStream in) throws IOException {
for (int i = 0; i < BitUtils.DIFF_BYTES; i++)
theCounts.setCount(i, 0);
int ch;
int num;
for (; ; ) {
ch = in.readByte();
num = in.readInt();
if (num == 0)
break;
theCounts.setCount(ch, num);
}
createTree();
}
/**
* Construct the Huffman coding tree.
*/
private void createTree() {
PriorityQueue<HuffNode> pq = new PriorityQueue<HuffNode>();
for (int i = 0; i < BitUtils.DIFF_BYTES; i++) {
//at least once
if (theCounts.getCount(i) > 0) {
//create a new tree node
HuffNode newNode = new HuffNode(i, theCounts.getCount(i), null, null, null);
theNodes[i] = newNode;
pq.add(newNode);
}
}
//end-of-file symbol
theNodes[END] = new HuffNode(END, 1, null, null, null);
pq.add(theNodes[END]);
while (pq.size() > 1) {
HuffNode n1 = pq.remove();
HuffNode n2 = pq.remove();
HuffNode result = new HuffNode(INCOMPLETE_CODE, n1.weight + n2.weight, n1, n2, null);
n1.parent = n2.parent = result;
pq.add(result);
}
root = pq.element();
}
}
對於getCode方法,先通過theNodes方法獲取儲存該字元的節點。如果找不到,返回空引用。否則,我們使用迴圈,從父節點向上一直到根節點。每一步都用0或者1表示,最後轉換成整數陣列,返回。
對於getChar方法,我們從根開始,根據編碼沿著分支向下,或者返回null,或者返回節點儲存的值。
對於讀寫編碼表的方法,我們使用的格式很簡單,不一定是最節省空間的。對每個有編碼的字元,我們寫它(一個位元組),然後寫該字元的總數(四個位元組)。最後寫一個’\0’ 字元和一個0總數(這是個特殊訊號)。讀表的時候,更新讀的總數。呼叫createTree,構造樹。
因為節點實現了Comparable介面(基於節點的weight),程式維護了一個樹節點的優先佇列。然後我們搜尋至少出現過一次的字元。136-142行,逐行翻譯樹構造演算法。當我們有兩個或者更多的樹,就從優先佇列抽取兩棵樹,合併它們,放回優先佇列。在迴圈的結束,優先佇列裡只留下一棵樹,可以退出迴圈,設定根。
通過createTree方法產生的樹,依賴優先佇列如何打破關係。這意味著如果程式在兩臺機器上編譯,有可能在一臺機器上壓縮的檔案,到另一臺機器上無法解壓。想避免這個問題,需要更多的工作。
壓縮類
先看HZIPOutputStream類。每次呼叫write方法,都寫到ByteArrayOutputStream。呼叫close,完成實際的壓縮工作。
close方法的第34行,如果我們只使用byte,傳給getCode的整數可能和EOF混淆,因為高位被當作符號位。所以使用位掩碼。
退出迴圈的時候,到了檔案末尾,所以寫end-of-file碼。BitOutputStream的close方法會把任何剩餘的位flush到檔案,所以不再需要呼叫flush。
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class HZIPOutputStream extends OutputStream {
private ByteArrayOutputStream byteOut = new ByteArrayOutputStream();
private DataOutputStream dout;
public HZIPOutputStream(OutputStream out) throws IOException {
dout = new DataOutputStream(out);
}
public void write(int ch) throws IOException {
byteOut.write(ch);
}
public void close() throws IOException {
byte[] theInput = byteOut.toByteArray();
ByteArrayInputStream byteIn = new ByteArrayInputStream(theInput);
CharCounter countObj = new CharCounter(byteIn);
byteIn.close();
HuffmanTree codeTree = new HuffmanTree(countObj);
codeTree.writeEncodingTable(dout);
BitOutputStream bout = new BitOutputStream(dout);
//repeatedly gets a character and writes its code
for (int i = 0; i < theInput.length; i++)
bout.writeBits(codeTree.getCode(theInput[i] & (0xff)));
//end-of-file code
bout.writeBits(codeTree.getCode(BitUtils.EOF));
bout.close();
byteOut.close();
}
}
然後是HZIPInputStream。
import java.io.DataInputStream;
import java.io.IOException;
import java.io.InputStream;
public class HZIPInputStream extends InputStream {
private BitInputStream bin;
private HuffmanTree codeTree;
public HZIPInputStream(InputStream in) throws IOException {
DataInputStream din = new DataInputStream(in);
codeTree = new HuffmanTree();
codeTree.readEncodingTable(din);
bin = new BitInputStream(in);
}
public int read() throws IOException {
//the (Huffman) code that we are currently examining
String bits = "";
int bit;
int decode;
while (true) {
bit = bin.readBit();
if (bit == -1)
throw new IOException("Unexpected EOF")