
第5章 線性迴歸(一 理論講解)
開發IDE:Anaconda 3(python3.6.5)
迴歸是由達爾文(Charles Darwin)的表兄弟Francis Galton發明的。Galton於1877年完成了第一次迴歸預測,目的是根據上一代豌豆種子(雙親)的尺寸來預測下一代豌豆種子(孩子)的尺寸。 Galton在大量物件上應用了迴歸分析,甚至包括人的身高。他注意到,如果雙親的高度比平均高度高,他們的子女也傾向於比平均高度高,但尚不及雙親。孩子的高度向著平均高度回退(迴歸)。 Galton在多項研究上都注意到這個現象,所以儘管這個英文單詞跟數值預測沒有任何關係,但這種研究方法仍被稱作迴歸。
那麼什麼是線性迴歸呢?在統計學中,線性迴歸(Linear Regression)是利用稱為線性迴歸方程的最小平方函式對一個或多個自變數和因變數之間關係進行建模的一種迴歸分析
我們和以前一樣,還是結合例項來講解吧。就以房價為例吧,這也是大家最熟悉,最關心得。
給定資料集 ,其中 ,共有個樣本,每個樣本含有個特徵。
現在我們有關於重慶洪崖洞附近房價的一些資料, ,其中只含有一個特徵,表示房子的面積, 表示是第 個訓練樣本, 是數值,表示房子的價格。我們將該數值繪製成下圖。
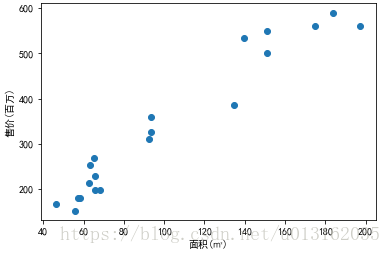
通過觀察我們大致可以看出,房子的面積 與房子的價格 具有一定的線性關係,也就是說,我們可以畫出能夠大致表示 與 關係的一條直線,如下圖:
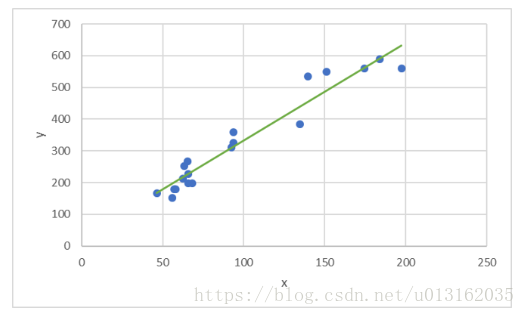
在該直線中,房子的面積為自變數,房子的價格為因變數。而“線性迴歸”的目的就是,利用自變數 與因變數 ,來學習出這麼一條能夠描述兩者之間關係的線。對於一元線性迴歸來說就是學習出一條直線,而對於多元線性迴歸來說則是學習出一個面或超平面。
對於上述的例子,我們可以得到一個函式關係, 。為了解決一般問題,我們就需要將線性迴歸的問題進行一般化、抽象化,轉換成我們能夠求解的數學問題。
5.1一元線性模型
在上面的例子中,我們可以看出自變數**與因變數大致成線性關係,因此我們可以對因變數做如下假設(hypothesis): 或者
其中在這裡使用是由於通過觀察,我們可以發現直線並沒有完全擬合數據,而是存在一定的誤差。該假設即為一元線性函式的模型函式,其中含有兩個引數與 。其中 可視為斜率, 為則直線在 軸上的截距。接下來的任務就是如何求得這兩個未知引數。
5.1.1損失函式
模型建立好了,那麼怎樣的模型才是適合資料集放入呢?衡量一個模型和與資料點之間的接近程度,我們使用平方差來衡量。對於 其對應的直線上的值為,但所給的資料集中 對應的值為 。而預測值與實際值存在誤差(或者也叫做殘差(residual),在機器學習中也被稱為代價(cost))。我們可以認為,預測值與實際值的誤差越小越好。
在這裡我們使用均方誤差(Mean Squared Error)來描述所需要求解的目標函式(Objective function)或代價函式(Loss function):
其中 目標函式描述了所有訓練樣本實際值與預測值之間的均方誤差,而我們的目的就是求解能夠使得該誤差值最小的引數 。可將其表示為:
在確定了代價函式以及所需要求解的目標以及條件