
Apollo自動駕駛入門課程第④講 — 感知(上)


上一篇文章中,我們釋出了無人駕駛技術的很多開發者結合定位篇與Apollo平臺的視訊,對定位系統已經有了自己的見解,提出了有趣的問題。也希望更多的開發者能夠參與到Apollo的平臺中去,在學習交流的同時豐富這個平臺。
本週我們將介紹感知,瞭解車輛如何利用感知元件感知周圍環境,瞭解不同的感知任務,例如分類、檢測和分割,並學習對感知而言至關重要的卷積神經網路。
在開車時,我們用眼睛來判斷速度、車道位置、轉彎位置。在無人駕駛中,情況類似,只不過需要使用靜態攝像頭和其他感測器來感知環境,使用大量計算機視覺技術。
1.感知的概述
我們人類天生就配備多種感測器,眼睛可以看到周圍的環境,耳朵可以用來聽,鼻子可以用來嗅,也有觸覺感測器,甚至還有內部感測器,可以測量肌肉的偏轉。通過這些感測器,我們可以感知到我們周圍的環境。我們的大腦每分每秒都在進行資料處理,大腦的絕大部分都是用於感知。
現在,無人駕駛車輛也在做這些事情,只不過他們用的不是眼睛而是攝像頭。但是他們也有雷達和鐳射雷達,它們可以幫忙測量原始距離,可以得到與周圍環境物體的距離。對於每個無人駕駛汽車,它的核心競爭力之一就是利用海量的感測器資料,來模仿人腦理解這個世界。談論感測器時也會涉及到神經網路、深度學習、人工智慧。
2.計算機視覺
作為人類,我們可以自動識別影象中的物體,甚至可以推斷這些物體之間的關係。但是對於計算機而言影象只是紅、綠、藍色值的集合。無人駕駛車有四個感知世界的核心任務:檢測——指找出物體在環境中的位置;分類——指明確物件是什麼;跟蹤——指隨時間的推移觀察移動物體;語義分割——將影象中的每個畫素與語義類別進行匹配如道路、汽車、天空。

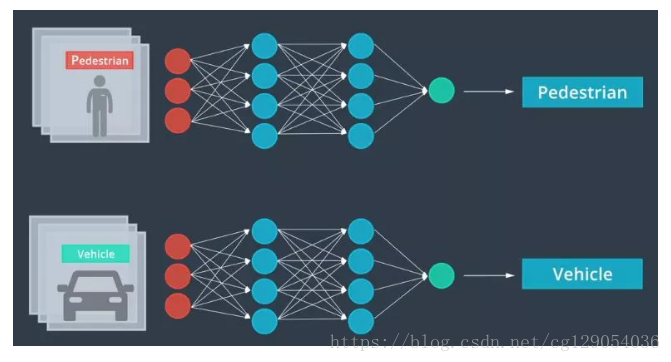
將分類作為研究計算機視覺一般資料流程的例子。影象分類器是一種將影象作為輸入,並輸出標識該影象的標籤的演算法,例如交通標誌分類器檢視停車標誌並識別它停車標誌、讓路標誌、限速標誌還是其它標誌。分類器甚至可以識別行為,比如一個人是在走路還是在跑步。
分類器有很多種,但它們都包含一系列類似的步驟。首先計算機接收類似攝像頭等成像裝置的輸入。然後通過預處理髮送每個影象,預處理對每個影象進行了標準化處理,常見的預處理包括調整影象大小、旋轉影象、將影象從一個色彩空間轉換為另一個色彩空間,比如從全綵到灰度,預處理可幫助我們的模型更快地處理和學習影象。接下來,提取特徵,特徵有助於計算機理解影象,例如將汽車與自行車區分開來的一些特徵,汽車通常具有更大的形狀並且有四個輪子而不是兩個,形狀和車輪將是汽車的顯著特徵。最後這些特徵被輸入到分類模型中。此步驟使用特徵來選擇影象類別,例如分類器可以確定影象是否包含汽車、自行車、行人這樣的物件。

為了完成這些視覺任務,需要建立模型,模型是幫助計算機瞭解影象內容的工具。
3.攝像頭影象
不論計算機在執行什麼識別任務,通常在開始時將攝像頭影象作為輸入。
攝像頭影象是最常見的計算機視覺資料,以這張汽車照片為例,讓我們看看計算機如何認為這實際上是一輛汽車的影象。從計算機的角度來看,影象只是一個二維網格被稱為矩陣,矩陣中的每個單元格都包含一個值,數字影象全部由畫素組成,其中包含非常小的顏色或強度單位,我們可以對其中的數字做出非常多的處理。通常這些數字網格是許多影象處理技術的基礎,多數顏色和形狀轉換都只是通過對影象進行數學運算以及逐一畫素進行更改來完成。
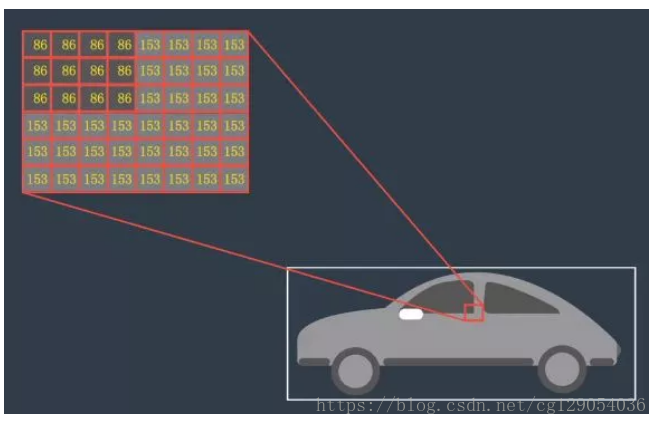
以上是我們講一個影象分解為二維灰度畫素值網路,彩色照片是相似的,但是更復雜一些。
彩色影象被構建為值的三維立方體,每個立方體都有高度、寬度和深度,深度為顏色通道數量。大多數彩色影象以三種顏色組合表示紅色、綠色。藍色,稱為RGB影象。對於RGB影象來說,深度值是3,因此可用立方體來表示。

4.LiDAR影象
感知擴充套件到感測器,而不僅僅是攝像頭。鐳射雷達感測器建立環境的點雲表徵,提供了難以通過攝像頭影象獲得的資訊如距離和高度。鐳射雷達感測器使用光線尤其是鐳射來測量與環境中反射該光線的物體之間的距離,鐳射雷達發射鐳射脈衝並測量物體將每個鐳射脈衝反射回感測器所花費的時間。反射需要的時間越長,物體離感測器越遠,鐳射雷達正是通過這種方式來構建世界的視覺表徵。

鐳射雷達通過發射光脈衝來檢測汽車周圍的環境,藍色點表示反射鐳射脈衝的物體,中間的黑色區域是無人駕駛車本身佔據的空間。由於鐳射雷達測量鐳射反射束,它收集的資料形成一團雲或“點雲”,點雲中的每個點代表反射回感測器的鐳射束,可以告訴我們關於物體的許多資訊例如其形狀和表面紋理。這些資料提供了足夠的物件檢測、跟蹤、分類資訊。正如我們所看,在點雲上執行的檢測和分類結果為紅點為行人,綠點表示其他汽車。
鐳射雷達資料提供了用於構建世界視覺表徵的足夠空間資訊,計算機視覺技術不僅可以使用攝像頭影象進行物件分類,還可以使用點雲和其他型別的空間相關資料進行物件分類。
5.機器學習
機器學習是使用特殊演算法來訓練計算機從資料中學習的電腦科學領域。通常,這種學習結果存放在一種被稱為“模型”的資料結構中,有很多種模型,事實上“模型”只是一種可用於理解和預測世界的資料結構。機械學習誕生於20世界60年代,但隨著計算機的改進,在過去的20年終才真正的越來越受到歡迎。
機器學習涉及使用資料和相關的真值標記來進行模型訓練,例如可能會顯示車輛和行人的計算機影象以及告訴計算機哪個是哪個的標籤。我們讓計算機學習如何最好地區分兩類影象,這類機器學習也成為監督式學習,因為模型利用了人類創造的真值標記。
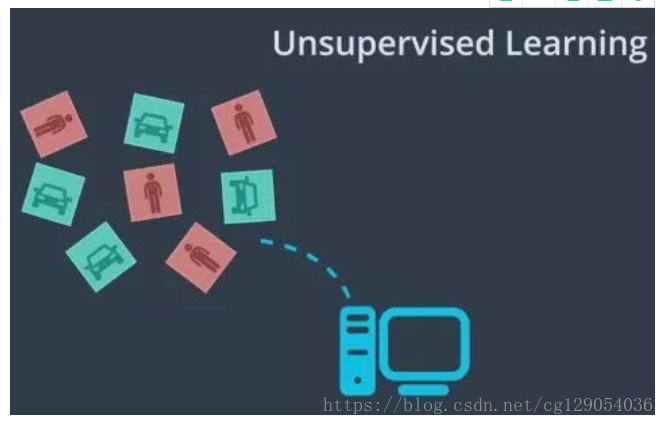
可以假想一個類似的學習過程,但這次使用的是沒有真值標記的車輛與行人影象,讓計算機自行決定哪些影象相似、哪些影象不同,這被稱為無監督學習。不提供真值標記,而是通過分析輸入的資料,計算機憑藉自行學習找到區別。
半監督式學習是將監督學習和無監督學習的特點結合在一起,該方法使用少量的標記資料和大量的未標記資料來訓練模型。
強化學習是另一種機器學習,強化學習涉及允許模型通過嘗試許多不同的方法來解決問題,然後衡量哪種方法最為成功,計算機將嘗試許多不同的解決方案,最終使其許多方法與環境相適應。
例如在模擬器中,強化學習智慧體可訓練汽車進行右轉,智慧體將在初試位置發動車輛,然後以多種不同的方向和速度進行實驗性駕駛,如果車輛實際完成了右轉,智慧體會提高獎勵即得分。
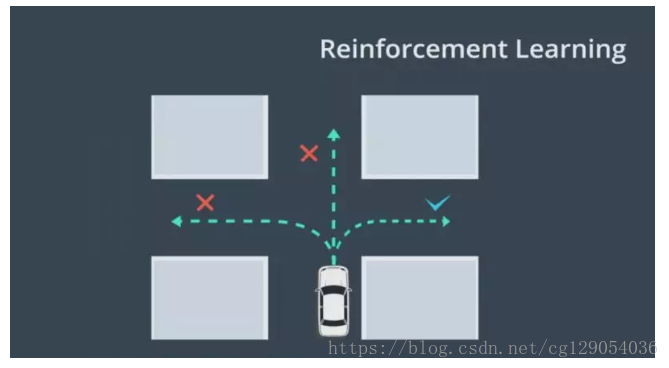
起初車輛可能無法找到執行轉彎的方法,然而就像人類那樣,車輛最終會從一些成功右轉經驗中學習,最終學會如何完成任務。
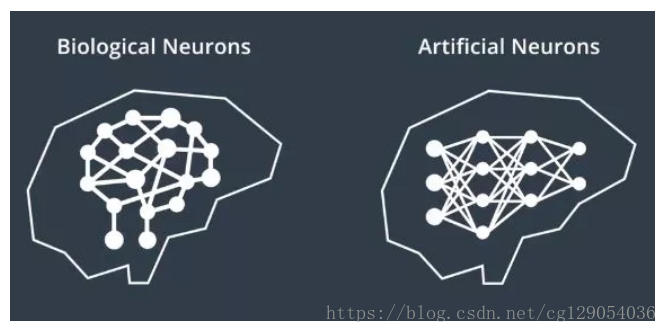
6.神經網路
人工神經網路用於無人駕駛,受到構成人類神經系統的生物神經元啟發,生物神經元通過相互連線構成了神經元網路或神經網路,通過類似的方式將人工神經元層連線起來以建立用於機器學習的人工神經網路。
人工神經網路是通過資料來學習複雜模式的工具,神經網路由大量的神經元組成,人工神經元負責傳遞和處理資訊,也可以對這些神經元進行訓練。可以將這些影象識別為車輛,無論它們是黑是白、或大或小,你甚至可能不知道自己如何知道它們是車輛,也許是某些特徵觸發了你的反應,如車輪、車燈、車窗。人工神經網路具有類似的運作方式。人工神經網路通過密集訓練,計算機可以辨別汽車、行人、交通訊號燈、電線杆。它們學習了用於執行任務的模型,只是我們可能很難直觀地理解該數學模型。
當看到該影象時,你的大腦如何工作?你的大腦可能會將影象分為幾部分然後識別特徵如車輪、車窗、顏色,然後大腦將使用這些特徵對影象進行檢測和分類。
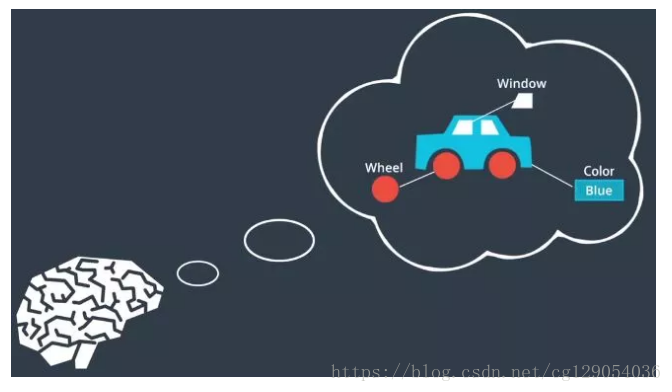
例如在確定影象是否為車輛時,大腦可能不會認為顏色是關鍵特徵。因為汽車有多種顏色,所以大腦會將更多權重放在其他特徵上並降低顏色的重要性。

同樣,神經網路也會從影象中提取許多特徵,但這些特徵可能是我們人類無法描述或甚至無法理解的特徵。但我們最終並不需要理解,計算機將調整這些特徵的權重,以完成神經網路的最終任務。
7.反向濾波法
學習有時稱為訓練,由三步迴圈組成——前瞻、誤差測定、反向傳播。
首先隨機分配初試權重即人工神經元的值,通過神經網路來饋送每個影象產生輸出值,這被稱為前饋。
繼續開車可以發現,有些點右邊只有一棵樹,也可以排除。
下一步為誤差測定,誤差是真是標記與前饋過程所產生輸出之間的偏差。
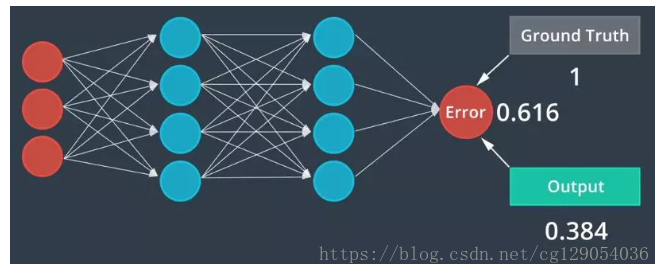
最後一步是反向傳播,通過神經網路反向傳送誤差,此過程類似前饋過程,只是以相反方向進行。

每個人工神經元都對其值進行微調,這是基於通過神經網路後向傳播的誤差,可生成更準確的網路。一個訓練週期:
包括前饋、誤差測定、反向傳播還遠遠不夠。為了訓練網路,通常需要數千個這樣的週期,最終結果應該是模型能夠根據新資料做出準確預測。
更多詳細課程內容,大家可以登陸官網繼續學習!
也可以新增社群小助手(Apollodev)為好友,回覆“課程學習”進群與其他開發者共同交流學習。

自課程上線以來,瀏覽量已超10萬,已幫助全球97個國家約 7000 名學員入門自動駕駛與 Apollo 開源平臺,其中37%為海外學員,本門課程已成為優達學城 (Udacity) 近期獲得關注度最高的免費課程之一