【機器學習筆記22】神經網路(卷積神經網路)
阿新 • • 發佈:2018-12-12
【參考資料】 【1】《面向機器智慧的tensorflow實踐》 【2】Keras/example – mnist_cnn.py 【3】Keras中文文件
常用層
卷積層
卷積理解就是之前影象處理裡用作檢測邊緣、檢測角點的運算元,例如: 輸入: 核:
卷積: 輸出:
卷積處理時需要考慮(在tensorflow引數中)
- 跨度: 即不是每個影象區域都要進行卷積,可以跨過一些畫素
- 邊界填充:當卷積核(例如3*3的sobel卷積核)滑動到邊界時,考慮用0填充
*備註: 卷積作為整個網路的核心,理解是模擬生物學中的特徵,即我們的視覺神經只是做最簡單的邊緣檢測,然後在一層層的對接後,將簡單的邊界線抽象出複雜的形狀等資訊。 *
# 32 為輸出維度 # kernel_size為卷積核的大小,此時核的定義由 # kernel_initializer初始化,預設是glorot_uniform,一種基於均勻分佈的隨機取值 # activation 為該卷積輸出的啟用函式 model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
池化層
池化層層通過對輸入進行採用,比如在3*3的區域內取最大值,目的在於減少輸入尺寸、降低過擬合等。
#(2,2)表示在x、y軸上都使得輸出變為原圖的一半,進行最大值池化
model.add(MaxPooling2D(pool_size=(2, 2)))
Dropout層
為輸入資料施加Dropout。Dropout將在訓練過程中每次更新引數時按一定概率(rate)隨機斷開輸入神經元,Dropout層用於防止過擬合。
# 0.25是要斷開的神經元比例
model.add(Dropout(0.25))
Flatten層
Flatten層用來將輸入“壓平”,即把多維的輸入一維化,常用在從卷積層到全連線層的過渡。Flatten不影響batch的大小。
Dense層(全連線層)
# 128 表示該層的輸出維度
model.add(Dense(128, activation='relu'))
備註:理解在全連線層之前的卷積和池化層可以理解為特徵的選取,即從原始空間對映到一個新的特徵空間,但這個特徵真正意義上的分類是在全連線做的。
卷積神經網路程式(keras/mnist_cnn.py)
mnist是手寫數字識別庫
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
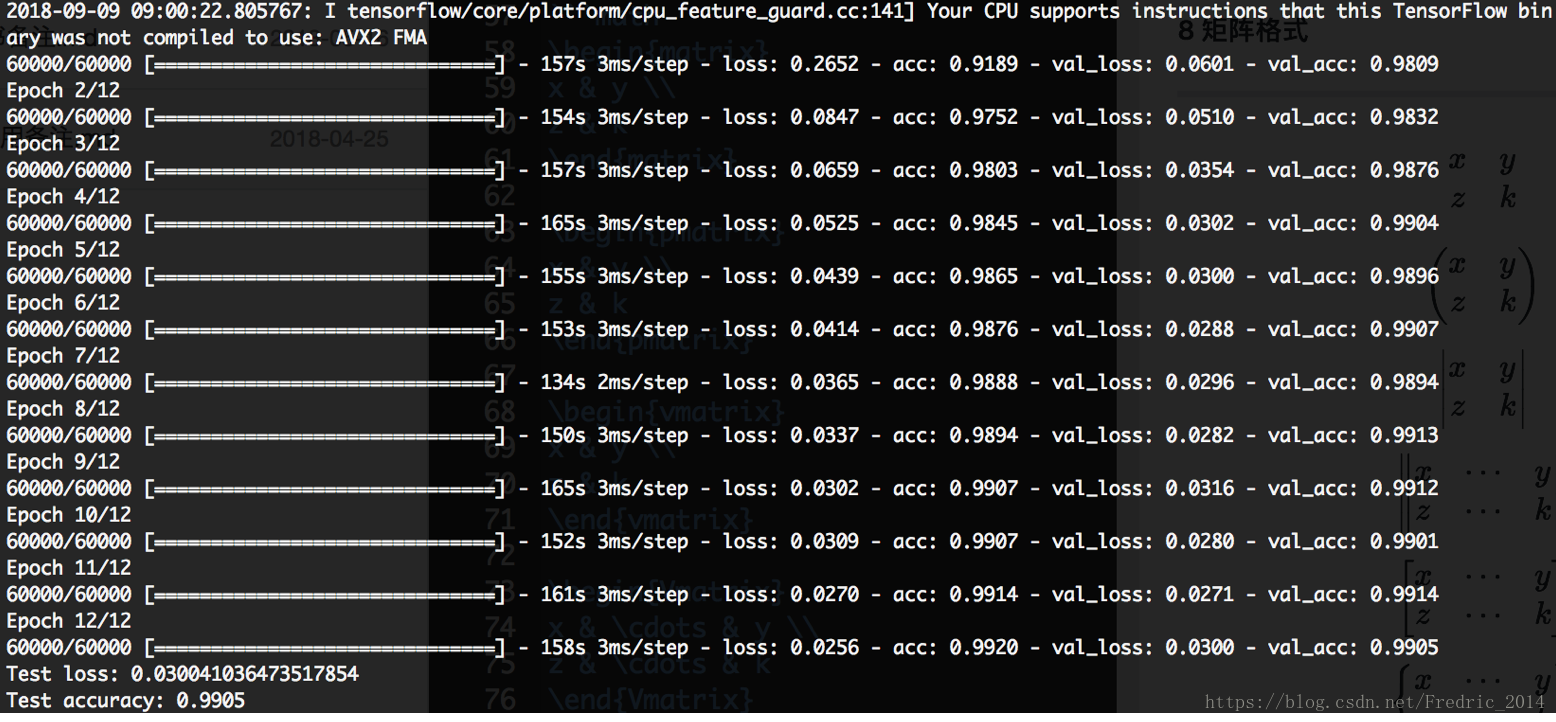
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])