
【機器學習筆記26】基於VGG16的影象風格遷移
Note: 本文主要是對論文及參考文獻【1】中程式碼的理解
概述
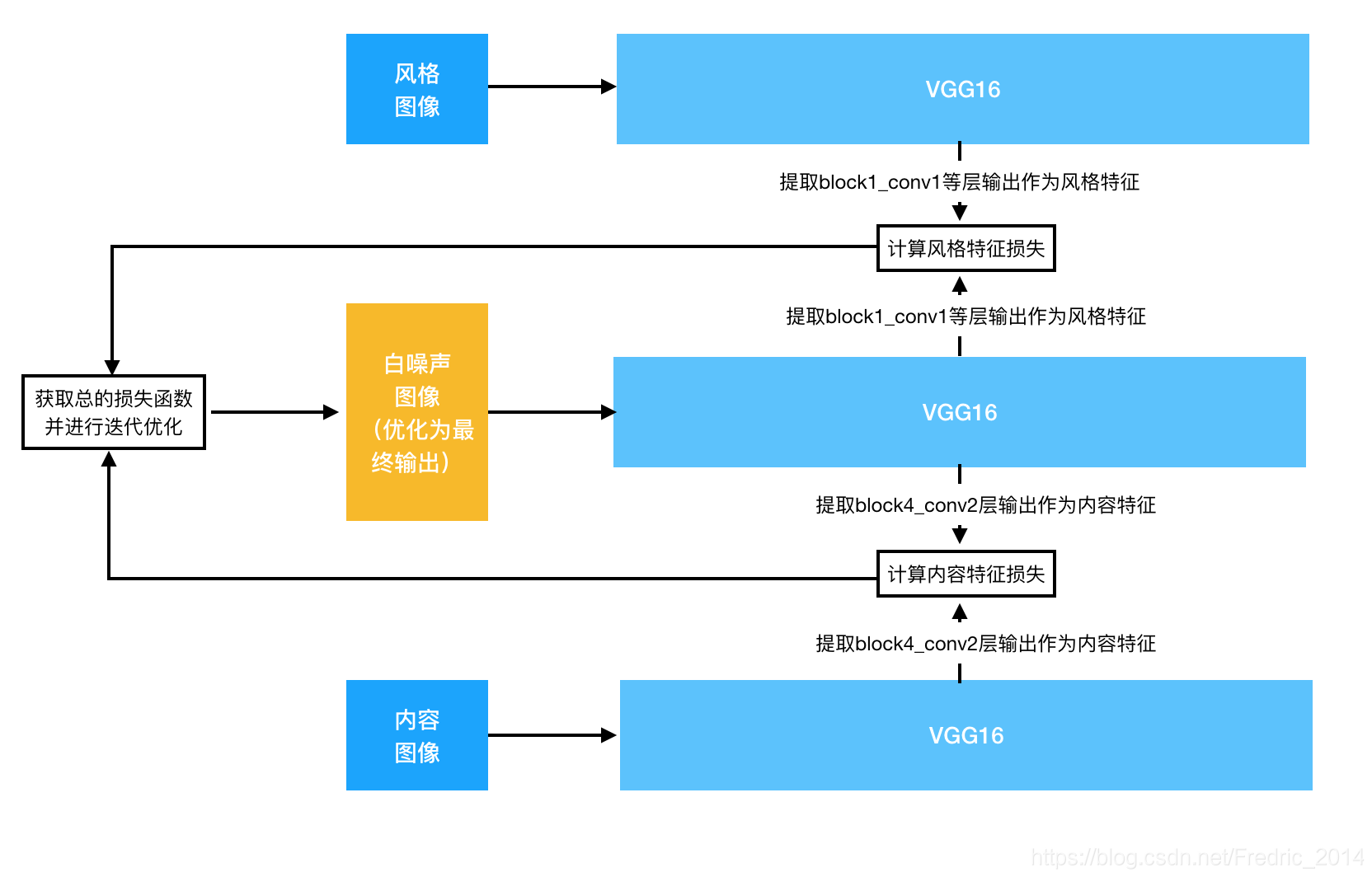
該演算法的本質是利用深度卷積網路對影象輸入的抽象,主要是三部分:
- 將風格影象輸入卷積神經網路,將某些層輸出作為風格特徵(做一次);
- 將內容影象輸入卷積神經網路,將某些層輸出作為內容特徵(做一次);
- 不斷優化一個隨機影象,使得它在該卷積神經網路的對應層輸出不斷接近上述兩個影象的風格和內容特徵(迭代);
如下圖所示:
VGG16
VGG網路是牛津大學計算機視覺組和Google Deepmind研發的一種深度卷積網路。其特點在於反覆的利用3x3的小型卷積核以及2x2的池化層。VGG16即16層的VGG網路,我們可以在keras-applications/vgg16.py中找到其模型實現。分析如下:
- 在vgg16的全連線層之間,總共分了5個block的卷積層
- block1由兩層64個3x3卷積層,以及一個2x2的最大池化層,分別命名為block1_conv1、block1_conv2和block1_pool。原始碼如下(後續block程式碼類似不再贅述):
# Block 1 x = layers.Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(img_input) x = layers.Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x) x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
- block2由兩層128個3x3卷積層和一個2x2最大池化層組成,分別命名為block2_conv1、block2_conv2和block2_pool
- block3由三層256個3x3卷積層和一個2x2最大池化層組成,分別命名為block3_conv1、block3_conv2、block3_conv3和block3_pool
- block4由三層512個3x3卷積層和一個2x2最大池化層組成,分別命名為block4_conv1、block4_conv2、block4_conv3和block4_pool
- block5由三層512個3x3卷積層和一個2x2最大池化層組成,分別命名為block5_conv1、block5_conv2、block5_conv3和block5_pool
- 最後是三個全連線層以softmax作為分類輸出(在影象遷移中我們用不到這些層),如下:
x = layers.Flatten(name='flatten')(x)
x = layers.Dense(4096, activation='relu', name='fc1')(x)
x = layers.Dense(4096, activation='relu', name='fc2')(x)
x = layers.Dense(classes, activation='softmax', name = 'predictions')(x)
具體程式碼流程
1. 構建VGG16
利用VGG16構建三個神經網路,分別對應內容影象輸入、風格影象輸入和白噪聲影象
cModel = VGG16(include_top=False, weights='imagenet', input_tensor=cImArr)
sModel = VGG16(include_top=False, weights='imagenet', input_tensor=sImArr)
gModel = VGG16(include_top=False, weights='imagenet', input_tensor=gImPlaceholder)
2. 利用VGG16的部分層輸出獲取風格特徵和內容特徵
內容特徵獲取層為’block4_conv2’ 風格特徵獲取層為’block1_conv1 block2_conv1 block3_conv1 block4_conv1’
P = get_feature_reps(x=cImArr, layer_names=[cLayerName], model=cModel)[0]
As = get_feature_reps(x=sImArr, layer_names=sLayerNames, model=sModel)
其中get_feature_rep函式就是獲取神經網路在某些層的輸出,注意的是這裡對於風格特徵需要將若干層拼接起來,而對於內容特徵只取了其中一個維度,應表示RGB其中一種顏色。
for ln in layer_names:
selectedLayer = model.get_layer(ln)
featRaw = selectedLayer.output #獲取該層的輸出
3. 訓練並輸出
xopt, f_val, info= fmin_l_bfgs_b(calculate_loss, x_val, fprime=get_grad, maxiter=iterations, disp=True)
xOut = postprocess_array(xopt)
xIm = save_original_size(xOut)
核心的訓練函式是這句,x_val即白噪聲影象的輸出。根據《A Neural Algorithm of Artistic Style》一文中的定義的損失函式和梯度計算方法,白噪聲影象被不斷優化,在一定迭代後,它的VGG16的對應層輸出會不斷接近風格影象和內容影象的對應層輸出,因此形成了最終的效果。下面來看損失函式和梯度的計算方式: 備註:其他一些優化的paper基本思路都類似,只是在所選擇卷積神經網路模型以及損失函式的定義上作了優化。
3.1 calculate_loss
def get_total_loss(gImPlaceholder, alpha=1.0, beta=10000.0):
#這裡關鍵的幾個步驟:
1. gImPlaceholder 就是白噪聲影象,作為gModel的輸入;這個輸入應該在每次迭代都會被更新;
2. get_content_loss 計算其與內容特徵的差異
3. get_style_loss 計算其餘與風格內容特徵的差異
4. 將上述差異計算總的損失值
F = get_feature_reps(gImPlaceholder, layer_names=[cLayerName], model=gModel)[0]
Gs = get_feature_reps(gImPlaceholder, layer_names=sLayerNames, model=gModel)
contentLoss = get_content_loss(F, P)
styleLoss = get_style_loss(ws, Gs, As)
totalLoss = alpha*contentLoss + beta*styleLoss
return totalLoss
def calculate_loss(gImArr):
if gImArr.shape != (1, targetWidth, targetWidth, 3):
gImArr = gImArr.reshape((1, targetWidth, targetHeight, 3))
loss_fcn = K.function([gModel.input], [get_total_loss(gModel.input)])
return loss_fcn([gImArr])[0].astype('float64')
3.1 calculate_loss F是噪聲影象的內容特徵輸出;P是內容影象的特徵輸出
def get_content_loss(F, P):
cLoss = 0.5*K.sum(K.square(F - P))
return cLoss
3.2 get_style_loss
- Gs是噪聲影象的風格特徵輸出,As是風格影象的特徵輸出
- get_Gram_matrix 構造的是一個Gram矩陣
Gram矩陣為其向量話特徵的內積: 計算風格損失函式(每層): 總的損失函式:其中是每層的權重因子,本程式碼中為全1
def get_Gram_matrix(F):
G = K.dot(F, K.transpose(F))
return G
def get_style_loss(ws, Gs, As):
sLoss = K.variable(0.)
for w, G, A in zip(ws, Gs, As):
M_l = K.int_shape(G)[1]
N_l = K.int_shape(G)[0]
G_gram = get_Gram_matrix(G)
A_gram = get_Gram_matrix(A)
sLoss+= w*0.25*K.sum(K.square(G_gram - A_gram))/ (N_l**2 * M_l**2)
return sLoss
3.3 get_grad
def get_grad(gImArr):
if gImArr.shape != (1, targetWidth, targetHeight, 3):
gImArr = gImArr.reshape((1, targetWidth, targetHeight, 3))
grad_fcn = K.function([gModel.input], K.gradients(get_total_loss(gModel.input), [gModel.input]))
grad = grad_fcn([gImArr])[0].flatten().astype('float64')
return grad
結果輸出
