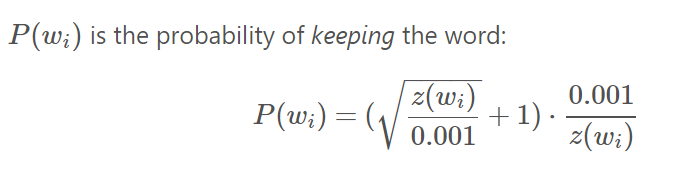Word2vec tutorial-the skip gram &Word2Vec Tutorial Part 2 - Negative Sampling 文章講解
阿新 • • 發佈:2018-12-12
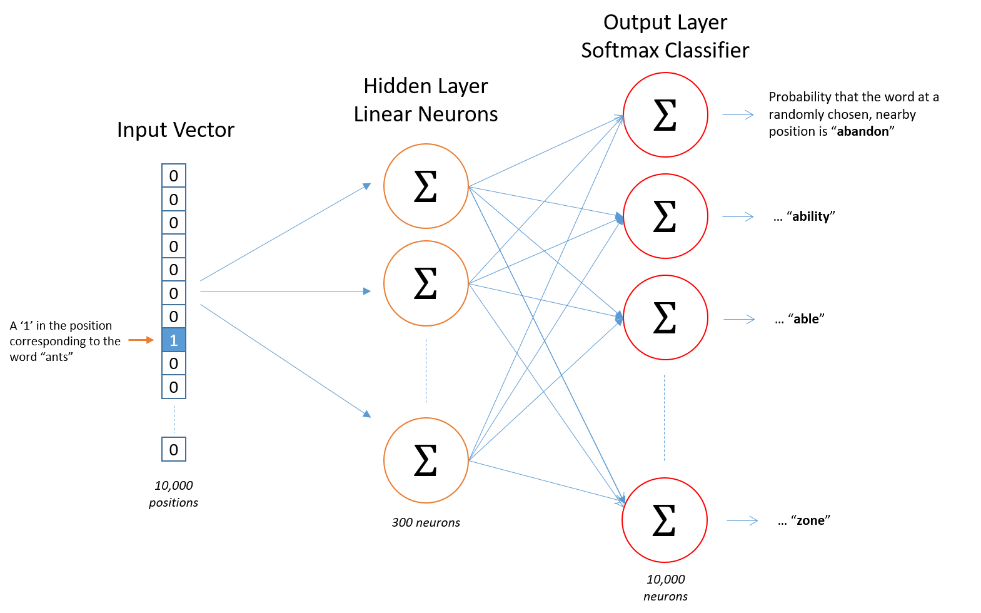
Word2vec tutorial-the skip gram1.總述:建立一個簡單的神經網路,一個輸入層,一個隱藏層,一個輸出層,我們只需要得到有效的隱藏層的權重即可。
2.構建資料:使用word pairs作為一個訓練組(w1,w2)輸入一個單詞,輸出其上下文單詞。
3.訓練: 輸入w1的one-hot表示,輸出所有詞的概率分佈(通過softmax得到),取 概率最大的那個詞w*作為神經網路的輸出詞。
4.獲取詞向量:Hidden layer weight matrix即為詞向量
注意:神經網路不考慮輸出詞相對於輸出詞的位置資訊相似上下文的單詞,其詞向量也會相似。5.分散式方法的限制:5.1相似性的定義;不同語境下其效果會變差,即相似性並不只侷限於其上下文的相似性,分散式的假設並沒有那麼的 魯棒。5.2害群之馬;許多詞的“瑣碎”屬性不會反映在文字中5.3反義詞;基於分散式的假設的模型趨向於認為反義詞之間非常的相似 5.4語料庫的偏好;5.5語境缺乏;詞的含義依賴於上下文(語境),對於所有的形式都是用統一個向量是有問題的。Word2Vec Tutorial Part 2 - Negative Sampling1.問題:對於擁有10000個不重複單詞,每個單詞300維的特徵,其weight的個數為300million,如此多的數量,作梯度下降必然十分的slow.2.詞向量訓練的優化方式:2.1把具有普遍意義的片語作為一個單詞例如:Boston Globe 比單個的Boston和Globe更有意義在組成phrase之前,每對單詞出現在訓練文字的次數,都將決定是否組成phrase2.2Subsampling Frequent Words 對頻繁的單詞進行子取樣比如(fox,the),這個pairs對fox的含義並沒有太大的貢獻,同時由於the出現的太頻繁,含有the的pairs的訓練對於the的詞向量的貢獻已經過飽和了。故在訓練時,根據這個單詞出現的頻率決定其在訓練時被刪除的概率。詞的保留概率公式如下:
x->詞頻,公式的結果表示其保留的概率。即word的詞頻越大,其保留的概率越低。2.3negative sampling訓練時,由於在一次bp中需要對所有的引數求梯度,故速度太慢,所以每次只對部分的weight求導,更新部分Weight(對本應輸出1的神經元(‘positive’)和其他n個本應輸出0的神經元(‘negative’)),出現頻率越高的詞其越有可能被選作為negative samples如何選擇negative sample? |