
快速熟悉one-hot,N-gram,word2vec模型
在自然語言處理領域,最開始的學習肯定繞不開one-hot,N-gram,word2vec。下文會快速,簡要的介紹這兩種技術,至於更多的技術細節,可以參考文章最後的參考文獻。在閱讀了本篇文章後,讀者應該能夠達到如下幾個目的:
1.明白one-hot,N-gram,word2vec的作用
2.明白one-hot,N-gram,word2vec的數學/網路架構
1.詞向量
詞向量就是用來將語言中的詞進行數學化的一種方式,顧名思義,詞向量
就是把一個詞表示成一個向量。這樣做的初衷就是機器只認識0 1 符號,換句話說,在自然語言處理中,要想讓機器識別語言,就需要將自然語言抽象表示成可被機器理解的方式。所以,詞向量是自然語言到機器語言的轉換。
詞向量最初是用one-hot represention表徵的,也就是向量中每一個元素都關聯著詞庫中的一個單詞,指定詞的向量表示為:其在向量中對應的元素設定為1,其他的元素設定為0。採用這種表示無法對詞向量做比較,後來就出現了分散式表徵。
在word2vec中就是採用分散式表徵,在向量維數比較大的情況下,每一個詞都可以用元素的分散式權重來表示,因此,向量的每一維都表示一個特徵向量,作用於所有的單詞,而不是簡單的元素和值之間的一一對映。這種方式抽象的表示了一個詞的“意義”。
向量的長度為詞典的大小,向量的分量只有一個 1,其他全為 0, 1 的位置對應該詞在詞典中的位置,例如
“話筒”表示為 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麥克”表示為 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
優點: 如果使用稀疏方式儲存,非常簡潔,實現時就可以用0,1,2,3,…來表示詞語進行計算,這樣“話筒”就為3,“麥克”為8.
缺點:1.容易受維數災難的困擾,尤其是將其用於 Deep Learning 的一些演算法時;2.任何兩個詞都是孤立的,存在語義鴻溝詞(任意兩個詞之間都是孤立的,不能體現詞和詞之間的關係)。
也正是這些原因,Hinton在 1986 年提出了Distributional Representation,可以克服 one-hot representation的缺點。解決“詞彙鴻溝”問題,可以通過計算向量之間的距離(歐式距離、餘弦距離等)來體現詞與詞的相似性
。
其基本想法是直接用一個普通的向量表示一個詞,這種向量一般長成這個樣子:[0.792, −0.177, −0.107, 0.109, −0.542, …],常見維度50或100。
優點:解決“詞彙鴻溝”問題
缺點:訓練有難度。沒有直接的模型可訓練得到。所以採用通過訓練語言模型的同時,得到詞向量 。
當然一個詞怎麼表示成這麼樣的一個向量是要經過一番訓練的,訓練方法較多,word2vec是其中一種。值得注意的是,每個詞在不同的語料庫和不同的訓練方法下,得到的詞向量可能是不一樣的。
2.N-gram
N-gram就是最簡單的一種語言模型。在一些NLP任務中,我們需要判斷一句話出現的概率是多少,即這句話是不是符合人的說話習慣,這時就可以利用到N-gram。另外,N-gram可以用於實現漢字轉換,關於這點,讀者可以查詢資料。
N-gram的數學模型非常簡單,就是一條數學表示式:
上面概率公式的意義為:第一次詞確定後,看後面的詞在前面次出現的情況下出現的概率。
例如,有個句子“大家喜歡吃蘋果”,一共四個詞”大家,喜歡,吃,蘋果”
P(大家,喜歡,吃,蘋果)=p(大家)p(喜歡|大家)p(吃|大家,喜歡)p(蘋果|大家,喜歡,吃)
p(大家)表示“大家”這個詞在語料庫裡面出現的概率;
p(喜歡|大家)表示“喜歡”這個詞出現在“大家”後面的概率;
p(吃|大家,喜歡)表示“吃”這個詞出現在“大家喜歡”後面的概率;
p(蘋果|大家,喜歡,吃)表示“蘋果”這個詞出現在“大家喜歡吃”後面的概率。
把這些概率連乘起來,得到的就是這句話平時出現的概率。
如果這個概率特別低,說明這句話不常出現,那麼就不算是一句自然語言,因為在語料庫裡面很少出現。如果出現的概率高,就說明是一句自然語言
為了表示簡單,上面的公式用下面的方式表示
其中,如果Contexti是空的話,就是它自己p(w),另外如“吃”的Context就是“大家”、“喜歡”,其餘的對號入座。
因此,如何計算 呢? 上面看的是跟據這句話前面的所有詞來計算,這樣計算就很複雜,像上面那個例子得掃描四次語料庫,這樣一句話有多少個詞就得掃描多少趟。語料庫一般都比較大,越大的語料庫越能提供準確的判斷。這樣計算開銷太大。
N-gram的精髓
為了解決這個問題,N-gram假設一句話中,一個字只跟這個字之前的幾個字相關(一般為2或3),這本身就是馬爾科夫模型的思想。因此,上式的計算變成:
如果一個詞的出現僅依賴於它前面出現的一個詞,那麼我們就稱之為bigram。即
如果一個詞的出現僅依賴於它前面出現的兩個詞,那麼我們就稱之為trigram。
為什麼只考慮2和3呢?這裡主要是考慮到計算機的算力。取3時,所有可能的N-gram的個數,已經接近計算機的最大算力了。
3.word2vec
現在得到詞向量最常用的方法是什麼?毫無疑問是word2vec。word2vec通過訓練一個神經網路,得到網路的權重矩陣,作為輸入的詞向量。常用的word2vec模型是:CBOW,Skip-gram。框架圖如下:
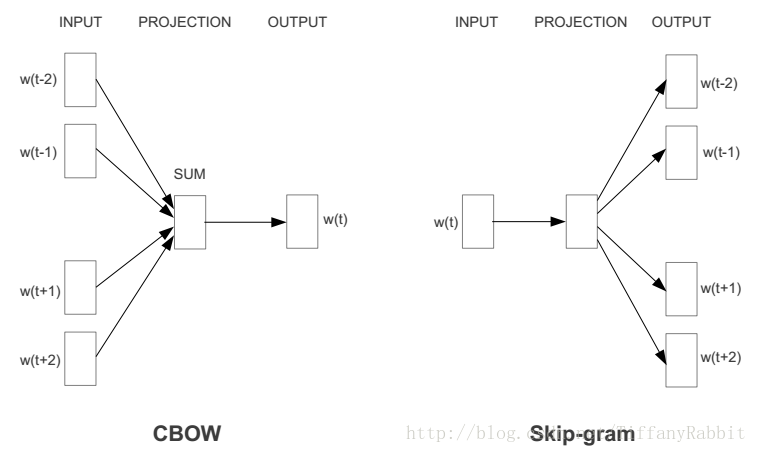
CBOW,Skip-gram兩者的差別在於:CBOW通過上下文預測中心詞概率,而Skip-gram模型則通過中心詞預測上下文的概率。
什麼意思呢?舉個例子,對於一句話:社會主義就是好,對於CBOW,如果要預測“主義”,則輸入就是“社會”,“就是”,“好”;對於Skip-gram,輸入則是“主義”,輸出是剩下的幾個字。
但它們的相同點在於,這兩個演算法訓練的目標都是最大限度的觀察實際輸出詞(焦點詞)在給定輸入上下文且考慮權重的條件概率。比如在上段的例子裡,通過輸入“社會”,“就是”,“好”之後,演算法的目標就是訓練出一個網路,在輸出層,能最大概率的得到“主義”的條件概率。
下面基於CBOW,詳細講述一下網路架構:
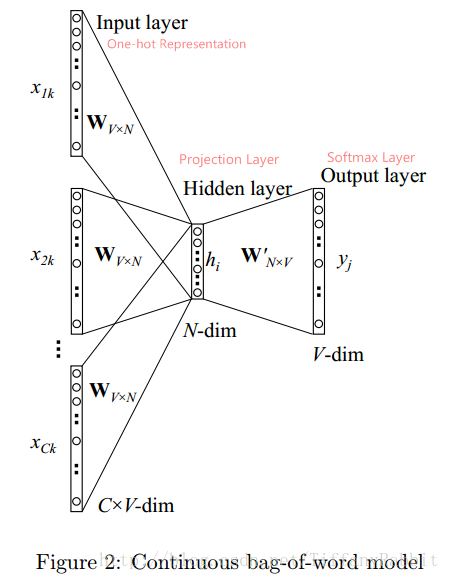
上圖是CBOW的架構。
符號定義: 語料庫為D,詞彙總數V;考慮上下文詞語數C個,分別表示為
;對映層/詞向量維度為N;
為詞彙w的One-hot Representation,V維;
為詞彙w的詞向量,N維。
輸入層: 輸入層的節點為C個上下文詞語的one-hot表示,共C*V輸入節點。
對映層: 將輸入層節點乘上權重矩陣
得到的詞向量(word embedding)求平均得到h。公式如下。
相關推薦
快速熟悉one-hot,N-gram,word2vec模型
在自然語言處理領域,最開始的學習肯定繞不開one-hot,N-gram,word2vec。下文會快速,簡要的介紹這兩種技術,至於更多的技術細節,可以參考文章最後的參考文獻。在閱讀了本篇文章後,讀者應該能夠達到如下幾個目的: 1.明白one-hot,N-gram,word2v
對one hot 編碼的理解,sklearn. preprocessing.OneHotEncoder()如何進行fit()的?
查閱了很多資料,逐漸知道了one hot 的編碼,但是始終沒理解sklearn. preprocessing.OneHotEncoder()如何進行fit()的?自己琢磨了一下,後來終於明白是怎麼回事了。 先看one hot 的編碼的理解:引用至:https://blog.csdn.net/wy250229
回溯法總結+四個小例題(裝載問題,01揹包,n後,最大團,m著色)
目錄 回溯法的基本策略 回溯法的基本策略 回溯法的解空間 回溯法基本思想 回溯法解題步驟 遞歸回溯和迭代回溯 子集樹和排列樹 裝載問題 01揹包問題回溯法求解 n後問題 圖的最大團問題 圖的m著色
word2vec實戰:獲取和預處理中文維基百科(Wikipedia)語料庫,並訓練成word2vec模型
前言 傳統的方法是將詞彙作為離散的單一符號,這些符號編碼毫無規則,無法提供詞彙之間可能存在的關聯關係,而詞彙的向量表示將克服上述難題。 向量空間模型(VSM)將詞彙表示在一個連續的向量空間中,語義近似的詞被對映為相鄰的資料點。VSM依賴於分散式假設思想,
N-gram統計語言模型(總結)
為了解決引數空間過大的問題,引入了馬爾科夫假設:任意一個詞的出現的概率僅僅與它前面出現的有限的一個或者幾個詞有關。如果一個詞的出現的概率僅於它前面出現的一個詞有關,那麼我們就稱之為bigram model(二元模型)。即 P(S) = P(W1,W2,W3,…,Wn)=P(W1)P(W2|W1)P
【hdu4549 M斐波那契數列】【矩陣快速冪】【F[n] = F[n-1] * F[n-2] ,求F[n] 】
【連結】 【題意】 F[0] = a F[1] = b F[n] = F[n-1] * F[n-2] ( n > 1 ) 給出a, b, n,求出F[n] 【分析】 寫出幾項後,發現:F[n]=a^x*b^y,x,y成斐波那契數列。 且有規律:ans=a^
有一個整數陣列,請你根據快速排序的思路,找出陣列中第K大的數。 給定一個整數陣列a,同時給定它的大小n和要找的K(K在1到n之間),請返回第K大的數,保證答案存在。
一, 原快速排序的實現 http://blog.csdn.net/taotaoah/article/details/50987837 using System; namespace taotao {
ES6 新特性,快速熟悉es6
ES6新特性 let命令 ES6新增了let命令,用來宣告變數,它的用法類似於var,但是所宣告的變數,只在let命令所在的程式碼塊內有效。{ let a = 10; var b = 1; } a // ReferenceError: a is not d
Android逆向工程:講解相關逆向工具的配置和使用,帶你快速熟悉逆向操作
有個一週沒有寫部落格了,最近一直都在忙於公司的業務開發,沒有多少時間來和大家分享技術,好不容易逮到一個時間,抽空寫一下部落格,那麼就讓我們趕快開始今天的學習把! 上面的部落格中,我們學習了smali語法的相關知識,以及動態除錯smali程式碼的操作,不知道你是否已經學會了,
加入新公司,怎樣快速熟悉業務和項目?
ron 輔助 基礎上 -i 增刪改 oid 文檔 你會 應該 轉載自:https://www.toutiao.com/a6599078103778066947/?tt_from=weixin&utm_campaign=client_share&wxshare
D. Powerful array 離線+莫隊算法 給定n個數,m次查詢;每次查詢[l,r]的權值; 權值計算方法:區間某個數x的個數cnt,那麽貢獻為cnt*cnt*x; 所有貢獻和即為該區間的值;
code ++ 計算方法 equal ati contains tdi ces sum D. Powerful array time limit per test 5 seconds memory limit per test 256 megabytes input st
利用jQuery選擇器快速匹配文檔中的按鈕,並為該按鈕綁定事件處理函數
body var jquery pla .org title color button ansi <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org
梯有N階,上樓可以一步上一階,也可以一步上二階。編寫一個程序,計算共有多少中不同的走法?
技術 告訴 不同的 mis misc 技術分享 blog main print c語言實現,小夥伴們誰要有更好的實現方法,要告訴我呦 #include int main(void) { int f,i,f1=1,f2=2; printf("請輸入樓梯數"); scanf(
快速收集有價值的網頁,微博,郵件!
tro -s ron images blog size jpg line 內容 網頁收藏 在手機上的瀏覽器裏看到有價值的網頁時,點擊底端的 分享按鈕,選擇 為知筆記,網頁內容就保存到為知筆記啦! 微博收藏 當你在微博上看到感興趣、有意思的文字或圖片時,直接 評論或
Java選擇排序,插入排序,快速排序
col log println 左移 i++ void -1 left oid public class Test { public static void main(String[] args) { int a[] = { 1, 2, 3,
2017省夏令營Day7 【快速冪,篩法,矩陣快速冪,線段樹】
swap 暴力 == define 練習 矩陣快速冪 color amp fine 題解:首先,我們可以得到一個規律:經過2次變換後,a和b的值都分別乘2了,所以只要用快速冪就能過啦,但是,要特判n為0的情況。 代碼如下: 1 #include<cstdi
譚浩強 c程序設計 8.17用遞歸法將一個整數n轉換成字符串。例如,輸入486,應輸出字符串"486"。n的位數不確定,可以是任意位數的整數。
tco xsl bof hcl mku owb kit gym code 8.17用遞歸法將一個整數n轉換成字符串。例如,輸入486,應輸出字符串"486"。n的位數不確定,可以是任意位數的整數。 #include <stdio.h>char str1[20]
1到n,n個整數連續異或的值(1 xor 2 xor 3 ... .. xor n)
。。 nbsp 異或 == ... n) 暴力 bsp 連續 暴力推,前12個數如下: 1 3 0 4 1 7 0 8 1 11 0 12 。。。。 所以對於任意的 n 有如下結論: if : n % 4 == 1 ans
簡單兩步快速實現shiro的配置和使用,包含登錄驗證、角色驗證、權限驗證以及shiro登錄註銷流程(基於spring的方式,使用maven構建)
protect login uid sim isa 當前 sub efi inf 前言: shiro因為其簡單、可靠、實現方便而成為現在最常用的安全框架,那麽這篇文章除了會用簡潔明了的方式講一下基於spring的shiro詳細配置和登錄註銷功能使用之外,也會根據慣例在文章最
輸入兩個整數n和m,從數列1,2,3,……n中隨意取幾個數,使其和等於m 轉載
輸出 -1 pri str spa private 組合 開始 () 題目:編程求解,輸入兩個整數n和m,從數列1,2,3,……n中隨意取幾個數,使其和等於m。要求將所有的可能組合列出來。 分析:分治的思想。可以把問題(m,n)拆分(m - n, n -1)和(m, n -