
Light-Head R-CNN
文章目錄
論文資訊
原文地址:Light-Head R-CNN: In Defense of Two-Stage Object Detector
程式碼實現:地址
作者:Zeming Li,Chao Peng,Gang Yu,Xiangyu Zhang,Yangdong Deng,Jian Sun
two-stage 檢測器的速度瓶頸
目標檢測(detection)主要分為兩個流派,one-stage(SSD,YOLO系列等)和 two-stage(R-CNN系列等),前者速度快,後者精度高。
two-stage的檢測框架一般將任務分為兩步:
-
第一步:產生足夠多的候選框(proposal),作者稱之為Body(檢測器體)
-
第二步:對候選框進行識別,作者稱為Head(檢測器頭)
通常,想要取得最好的準確率,Head的設計一般比較 Heavy,就是計算量引數較多,計算量比較大。作者發現,像 Faster RCNN 和 R-FCN 都有共同點,就是有一個非常 Heavy 的 Head 接到主體框架上:
-
Faster RCNN 在對 ResNet 的 conv5 進行 ROI Pooling 後,接了兩個全連線層。由於 ROI Pooling 後的特徵非常大,所以第一個 fc 層非常耗記憶體,並且影響速度。每個 Region Proposal 都要經過兩個 fc 層也導致計算量非常大。
-
在 R-FCN中,雖然少了兩個全連線層,但是需要構建一個 大小的Score Map( 為後接的池化層的大小),也是需要非常大的記憶體和計算量。
由於Faster R-CNN 和 R-FCN 的重頭設計,即使換用小的主幹網路,速度也很難有較大的提升,於是作者結合兩者優點,提出如下兩點改進:
-
使用 Large Separable Convolution 來生成一個 “Thin” 的Score Map,Score Map只有 通道。在論文中,作者用了 。
-
在 ROI Pooling 後接上一個全連線層。為什麼要接上這個全連線層呢?因為原來的 R-FCN 的 Score Map 是 通道,正好對應 Classes 的預測,現在沒有這麼多個通道了,沒辦法用原來的投票方法了,所以接上一個全連線層也是為了後面能夠接上 Faster R-CNN 的迴歸和分類。
Light-Head R-CNN 與其他網路的速度對比如下圖,主幹網路分別使用 (a small Xception like network,Resnet-50,Resnet-101):
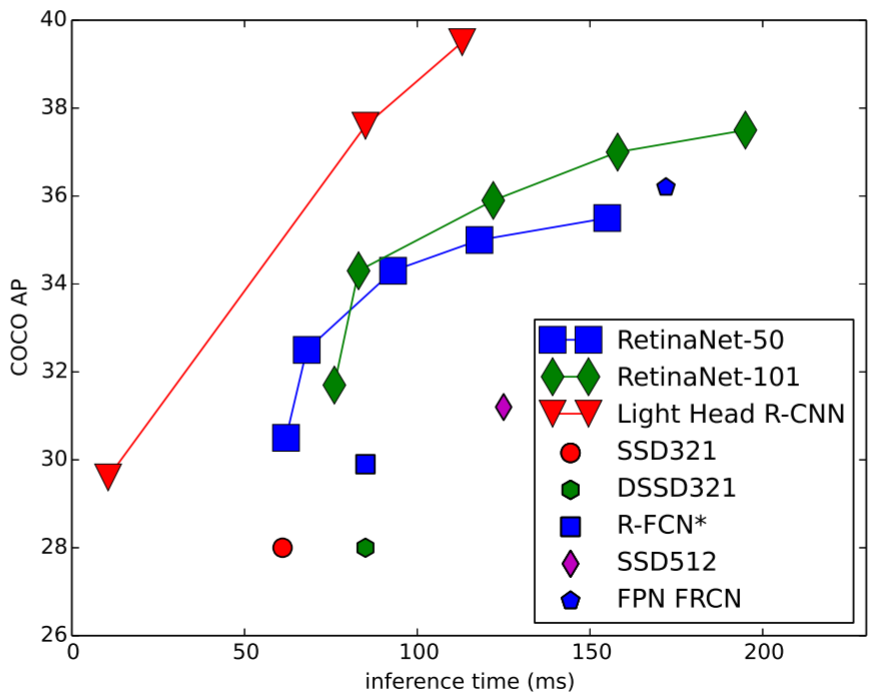
網路架構對比
作者將Light-Head R-CNN 與 Faster R-CNN 和 R-FCN 的架構進行了對比:
- Faster R-CNN
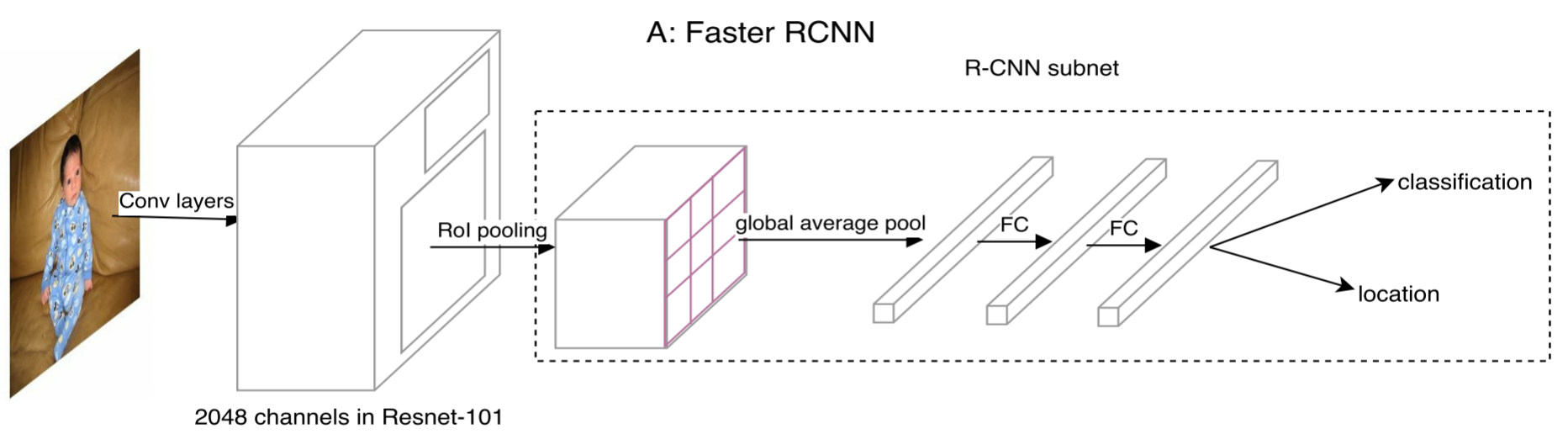
Faster R-CNN 在 ROI Pooling 以後要對每個 ROI 進行計算,也就是 R-CNN subnet,這部分包括兩個 fc 層,且第一個 fc 層要全連線上一層的全部channel,使用 ResNet101 作為主幹網路時,在上一層有 2048 個channel,這個計算量就很大了,所以說 ROI-wise 部分的計算太重了。
- R-FCN

R-FCN 為了對 ROI-wise subnet 進行加速,就採用了一種全卷積的策略。R-FCN 首先為每個 region 預測一個score maps,通道數是 (p是接下來的pooling形狀),接著是沿著每個 ROI 做pool,然後 average vote 最後的預測。
採用這種方式,R-CNN subnet 其實是沒有計算量的(但是效果上不如有 ROI-wise 的 Faster R-CNN),但是要為ROI pooling生成一個大的score map, 還是挺耗時的。
(圖中 表示物體檢測的類別數, 表示背景類。)
- Light-Head R-CNN
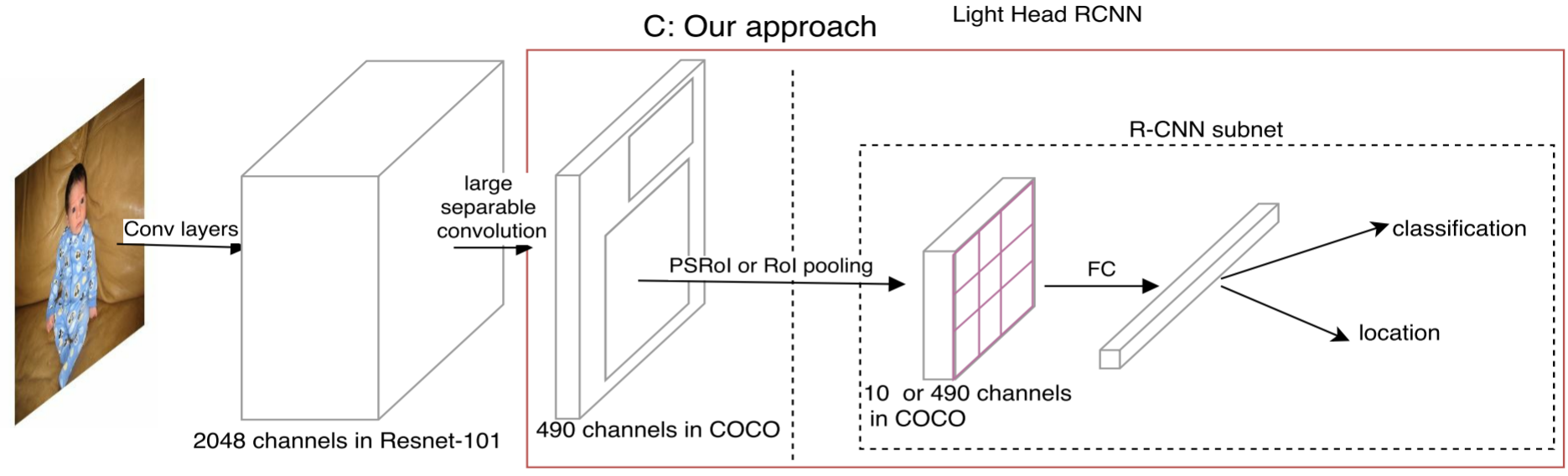
Light-Head R-CNN結合了Faster R-CNN和R-FCN的優點:
-
對 ResNet 卷積層中 conv5 的 2048 通道輸出,使用large separable convolution 降低特徵圖(feature maps)厚度並簡化計算量,生成 “薄”的 thin feature map( , ),避免了 R-FCN feature map 太大,且隨類別數 增加而增大的問題。
-
在 thin feature map 後面接 ROI Pooling,此時得到的 ROI-wise feature map 也薄,這樣後面再接 fc 層,此時的計算量就小了,避免了Faster R-CNN 在 R-CNN subnet 的第一個 fc 層計算量過大的問題。
Light-Head R-CNN 將原來 R-FCN 的 score map 的職責兩步化了:thin score map 主攻位置資訊,R-CNN子網路中的 fc 主攻分類資訊。另外,global average pool 的操作被去掉,用於保持精度。
主幹網路 Backbone
在Head小了以後,Light-Head R-CNN就可以在速度和精度之間做權衡,可以選擇性地使用大的或者小的backbone網路了。文章中給出了兩種設定:
-
“ L” 表示使用大的 backbone network,更注重精度。這裡用的 L 網路是resnet101。
-
“S” 表示使用小的 backbone network,更注重速度。這裡用的 S 網路是Xception-like model。
Thin feature maps for RoI warping
使用 large separable convolution,應該是借鑑了 Inception 3 的思想,用 和 的兩層卷積來代替 的卷積核,其結構如下:
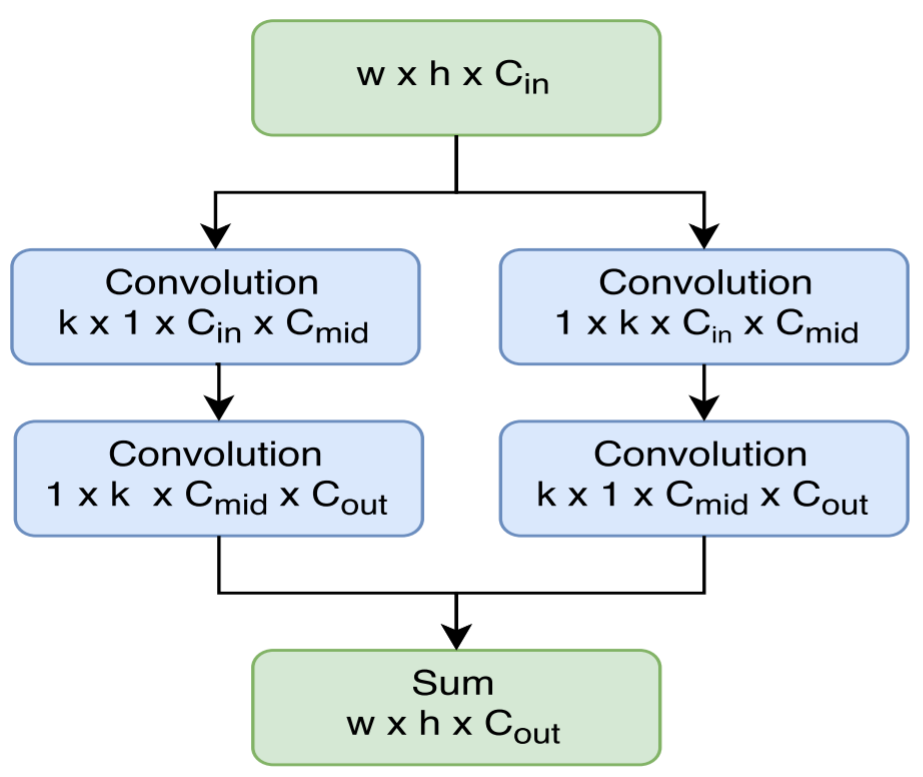
其中 kernel 大小: ,很大,所以叫 large conv,這主要是為了保證不丟失太多精度。因為這一層之前的 feature map 有2048 channel,這一層只有 490 channel,這麼多channel數的減少要通過 large conv 進行一定的補償。
另外,separate conv 能夠減少計算量, , ,遠小於 R-FCN 的 。
RPN
RPN 網路用於生成候選區域(region proposals)。通過 softmax 判斷 anchors 屬於前景(foreground)或者背景(background),同時利用bounding box regression 修正 anchors 的偏移和縮放,獲得精確的proposals。
Light-head R-CNN中使用RPN網路生成候選區域,具體過程如下:
-
卷積以及生成候選框(RoI):
在Light-head R-CNN中,使用 Resnet 的 conv4 的輸出作為 RPN 的輸入特徵圖,其維度是 。對特徵圖進行 卷積,並對feature map 進行滑窗操作。
當前滑窗的中心在原畫素空間的對映點稱為 anchor,以此 anchor 為中心,可以得到 15 個候選框(proposals):
-
使用 5 種面積尺寸(scales),即{ }
-
在每個面積尺寸下,取 3 種不同的縱橫比(Aspect Ratios): { }。
-
-
以3×3卷積核的中心點,作為 anchor 的中心點,通過滑動視窗和 anchor 機制得到影象的多尺度候選框。
-
使用1×1卷積核,基於 anchor 種類數量進行卷積,得到所有 anchors 的foreground softmax scores 和 bounding box regression 偏移量。
-
根據 bounding box regression 偏移量,獲取位置修正後的 anchors。
-
按照 foreground softmax scores 由大到小排序 anchors,提取前 6000 個 foreground anchors。
-
限定超出影象邊界的 foreground anchors 為影象邊界,防止後續 RoI Pooling 時 proposal 超出影象邊界
-
剔除非常小(width < threshold or height < threshold)的 foreground anchors。
-
進行非最大抑制(non maximum suppression,NMS),其中
-
再次按照 NMS 後的 foreground softmax scores 由大到小排序foreground anchors,提取前 1000 個結果作為 proposal 輸出。
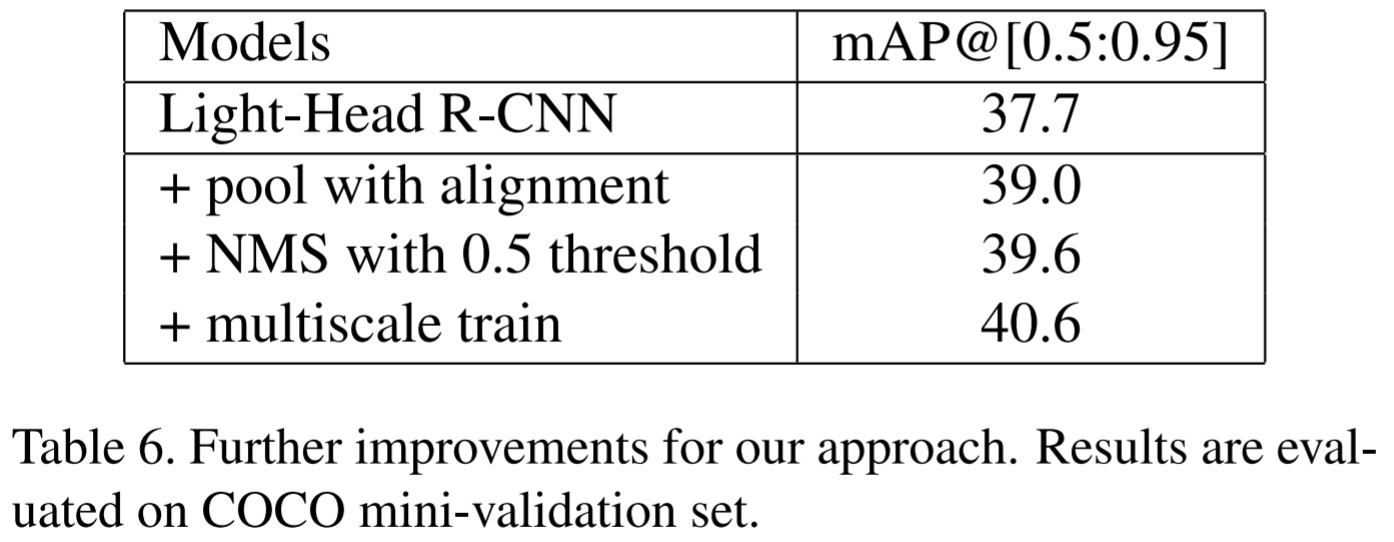
Light-Head R-CNN 精度提升技巧
為了提升演算法精度,作者又加入了其他 trick,分別是:
-
在 PSRoI pooling 中加入RoIAlign ( Mask-RCNN ) 中的插值技術,提升了1.7%.
-
將NMS threshold從 0.3 改成 0.5 之後,提升了0.6%.
-
使用 multi-scale 進行training,提升1%.
Light-Head R-CNN 速度提升技巧
為了平衡精度與速度,作者做了如下一些改變:
-
用 tiny Xception 代替 Resnet-101.
-
棄用 atrous algorithm.
-
將 RPN channel 減少一半到256.
-
Large separable convolution: .
-
採用 PSPooling + RoI-align. 用 alignment 技術做了 RoI warping,它能減少被 pool 的 feature map通道[ 倍,k是 pooling size],RoI-align能提升結果。
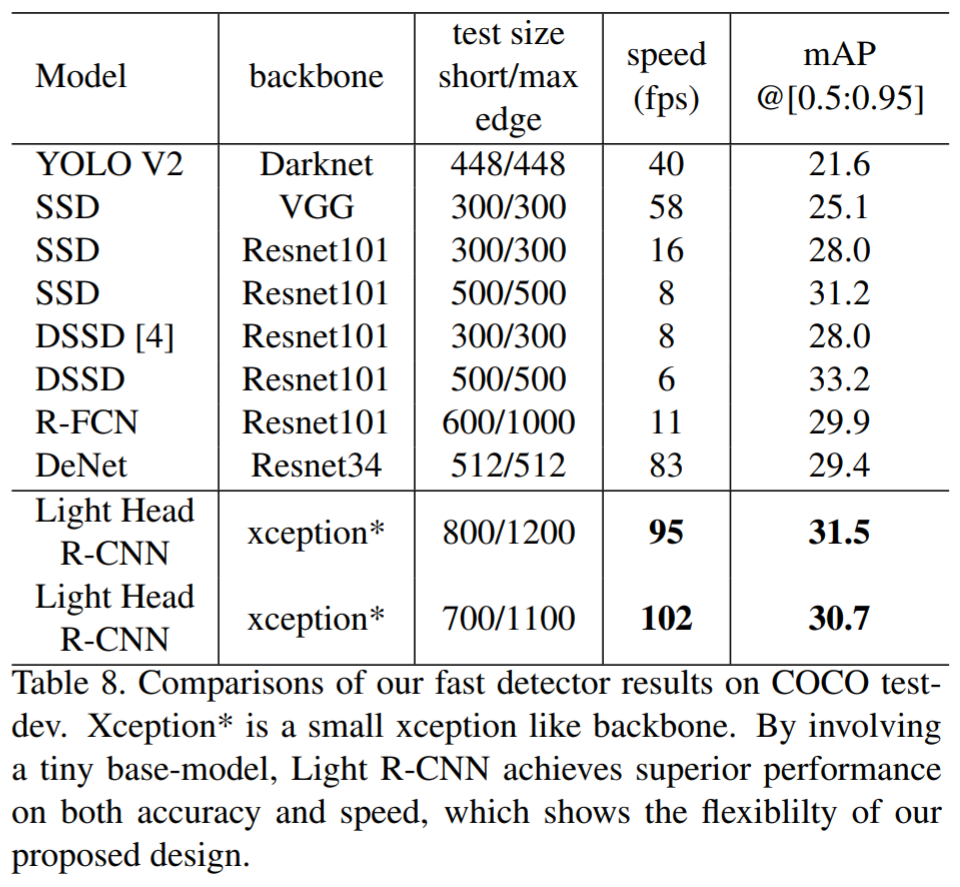
採用上述trick之後,能夠在COCO上達到102FPS,同時達到30.7% mmAP的精度:
作者的測試環境:The code is tested on a server with 8 Pascal Titian XP gpu, 188.00 GB memory, and 40 core cpu.