
監督學習(Supervised learning)
定義符號
m:訓練樣本的數目
n:特徵的數量
x‘s:輸入變/特徵值
y‘s:輸出變數/目標變數
(x,y):訓練樣本 ->(x(i),y(i)):訓練集,第i個訓練樣本,i=1,2..,m
監督學習
定義:(口頭表達,非正式)我們給學習演算法一個數據集,這個資料集由“正確答案”組成,它的目標是給定某個訓練集,需要學習某個函式h:X->Y(x到Y的對映), 使得h(x)就是一個“好”的預測器,能夠給出相應的輸出值y。函式h稱為hypothesis。
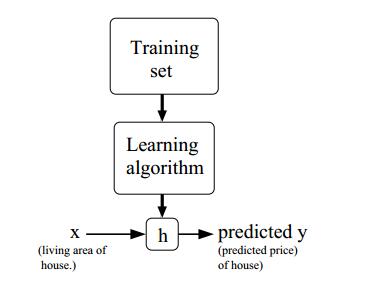
解釋:首先通過訓練集來學習出一個演算法得到一個假設函式h,然後利用假設函式來完成x到y的最好對映。
監督學習的例子
假定我們有一個數據集,它給出了居住地和房子價格的關係,如下表格所示:

假設上面的資料有47組,影象如下圖所示:
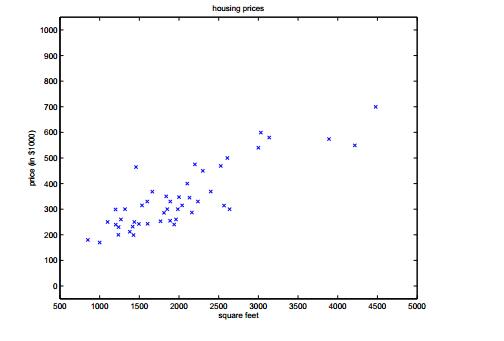
這樣根據我們上面給出的訓練集我們要經過一個學習演算法,得到一個假設函式,使得這個假設函式能更好的擬合我們給出的資料,從而在以後當我們給出房屋的大小時能更好的預測房屋的價格。
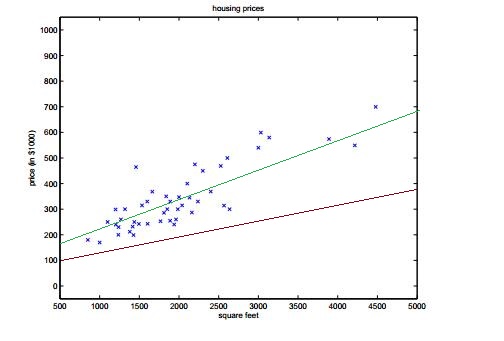
如上圖所示,假設我們得出的假設函式是一個線性的,這樣上面的函式明顯比下面相對於我們給出的樣本能夠更好的擬合。這就是一個監督問題。
監督學習的分類
當我們想要預測的輸出值為連續的,例如上例中我們的輸出值是價格,那麼該學習問題為一個迴歸(Regression)問題。當輸出值y僅能在一個有限的離散值集合中取值,我們稱之為分類(Classification)問題。
相關推薦
監督學習(Supervised learning)
定義符號 m:訓練樣本的數目 n:特徵的數量 x‘s:輸入變/特徵值 y‘s:輸出變數/目標變數 (x,y):訓練樣本 ->(x(i),y(i)):訓練集,第i個訓練樣本,i=1,2..,m 監督學習 定義:(口頭表達,非正式)我們給學習演算法一個數據集,這個資料集由“正確
機器學習之監督學習supervised learning
分類與迴歸 監督學習的問題主要有兩種,分別是分類classification和迴歸regression。 分類: 分類問題的目的是預測類別標籤class label,這些標籤來自預定義的可選列表。 迴歸: 迴歸任務的目的是預測一個連續值,也叫作浮點數floating-point nu
如何區分監督學習(supervised learning)和非監督學習(unsupervised learning)
如何區分監督學習(supervised learning)和非監督學習(unsupervised learning) 機器學習的常用方法中,我們知道一般分為監督學習和非監督學習。(當然還有半監督) l 監督學習:監督學習,簡單來說就是給定一定的訓練樣本(這裡一定要注意,這個
Strong Baselines for Neural Semi-supervised Learning under Domain Shift半監督學習
2018 ACL 論文 Strong Baselines for Neural Semi-supervised Learning under Domain Shift 不同資料集的遷移學習 MT-Tri方法在情感分析上(無監督域適應)超過DANN方法 半監督學習結合了監督學習和無監督學
機器學習與深度學習系列連載: 第一部分 機器學習(十三)半監督學習(semi-supervised learning)
在實際資料收集的過程中,帶標籤的資料遠遠少於未帶標籤的資料。 我們據需要用帶label 和不帶label的資料一起進行學習,我們稱作半監督學習。 Transductive learning:沒有標籤的資料是測試資料 Inductive learning:沒有標
【GAN ZOO翻譯系列】Cat GAN:UNSUPERVISED AND SEMI-SUPERVISED LEARNING WITH CATEGORICAL GAN 用於監督和半監督學習的GAN
Jost Tobias Springenberg 弗萊堡大學 79110 Freiburg, Germany [email protected] 原文連結https://arxiv.org/abs
Semi-supervised Learning ;半監督學習
1. 進入半監督學習 2. 半監督學習 出現的原因??? 原因:收集樣本資料容易,但是給每個樣本打標籤 成本就很高。 Collecting data is easy, but collecting “labelled” data is expensive. 3. 本篇
【論文解讀】【半監督學習】【Google教你水論文】A Simple Semi-Supervised Learning Framework for Object Detection
題記:最近在做LLL(Life Long Learning),接觸到了SSL(Semi-Supervised Learning)正好讀到了谷歌今年的論文,也是比較有點開創性的,淺顯易懂,對比實驗豐富,非常適合缺乏基礎科學常識和剛剛讀研不會寫論文的同學讀一讀,觸類旁通嘛。 這篇論文思路等等也非常適合剛剛開始
Unsupervised Learning: Linear Dimension Reduction---無監督學習:線性降維
避免 other 介紹 near -s func 例子 get 特征選擇 一 Unsupervised Learning 把Unsupervised Learning分為兩大類: 化繁為簡:有很多種input,進行抽象化處理,只有input沒有output 無中生
第八週(無監督學習)-【機器學習-Coursera Machine Learning-吳恩達】
目錄 K-means演算法 PCA(主成分分析) 1 K-means 1)演算法原理: a 選擇聚類中心
從零開始-Machine Learning學習筆記(29)-半監督學習
文章目錄 1. 生成式方法 2. 半監督SVM(Semi-Supervised Support Vector Machine, S3VM) 3. 圖半監督學習 3.1 針對於二分類問題的標記傳播
論文閱讀筆記3——基於域適應弱監督學習的目標檢測Cross-Domain Weakly-Supervised Object Detection through Progressive Domain A
本文是東京大學發表於 CVPR 2018 的工作,論文提出了基於域適應的弱監督學習策略,在源域擁有充足的例項級標註的資料,但目標域僅有少量影象級標註的資料的情況下,儘可能準確地實現對目標域資料的物體檢測。 ■ 連結 | https://www.paperweekly.site/papers/21
深度強化學習cs294 Lecture2: Supervised Learning of behaviors
cs294 Lecture2: Supervised Learning of behaviors Definition of sequential decision problems Terminology & notation
學習筆記之Supervised Learning with scikit-learn | DataCamp
Supervised Learning with scikit-learn | DataCamp https://www.datacamp.com/courses/supervised-learning-with-scikit-learn At the end of day, the value of D
Machine Learning--week1 監督學習、預測函式、代價函式以及梯度下降演算法
Supervised Learning given labelled data to train and used to predict for regression problem and classification problem Unsupervised Le
機器學習15:半監督學習semi-supervised
一、why semi-supervised dataset中只有部分資料進行了lable標註,即,有的資料成對出現{輸入,輸出},有的資料只有輸入{輸入}; Transductive learning(直推試學習):unlabled資料作為測試集; Inductive learning(
機器學習筆記——無監督學習(unsupervised learning)
聚類 之前我們講到的都是監督學習,下面讓我們來看對於無監督學習我們應該如何進行分類呢?無監督學習對應的就是給定的樣本點我們不給輸出值來進行分類 K-means K-means是一種十分常用的演算法,它的過程就是對於給定的K個初始點,首先根據各個樣本點到其的距離進行分類,之後將這K個
Deep learning發展歷程中的監督學習和非監督學習
1. 前言 在學習深度學習的過程中,主要參考了四份資料: 對比過這幾份資料,突然間產生一個困惑:臺大和Andrew的教程中用了很大的篇幅介紹了無監督的自編碼神經網路,但在Li feifei的教程和caffe的實現中幾乎沒有涉及。當時一直搞不清這種現象的原因,直到翻閱了深度學習的發展史之後,才稍微有了些眉目。
Machine Learning第八講【非監督學習】-- (四)PCA應用
一、Reconstruction from Compressed Representation(壓縮特徵的復原) 本部分主要講我們如何將已經壓縮過的特徵復原成原來的,如下圖: 左邊的二維圖是未縮減維數之前的情況,下面的一維圖是利用縮減之後的情況,我們利用公式可以得到x的近似值,如右圖,
Machine Learning第八講【非監督學習】--(三)主成分分析(PCA)
一、Principal Component Analysis Problem Formulation(主成分分析構思) 首先來看一下PCA的基本原理: PCA會選擇投影誤差最小的一條線,由圖中可以看出,當這條線是我們所求時,投影誤差比較小,而投影誤差比較大時,一定是這條線偏離最優直線。