
Machine Learning第八講【非監督學習】-- (四)PCA應用
一、Reconstruction from Compressed Representation(壓縮特徵的復原)
本部分主要講我們如何將已經壓縮過的特徵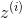
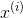
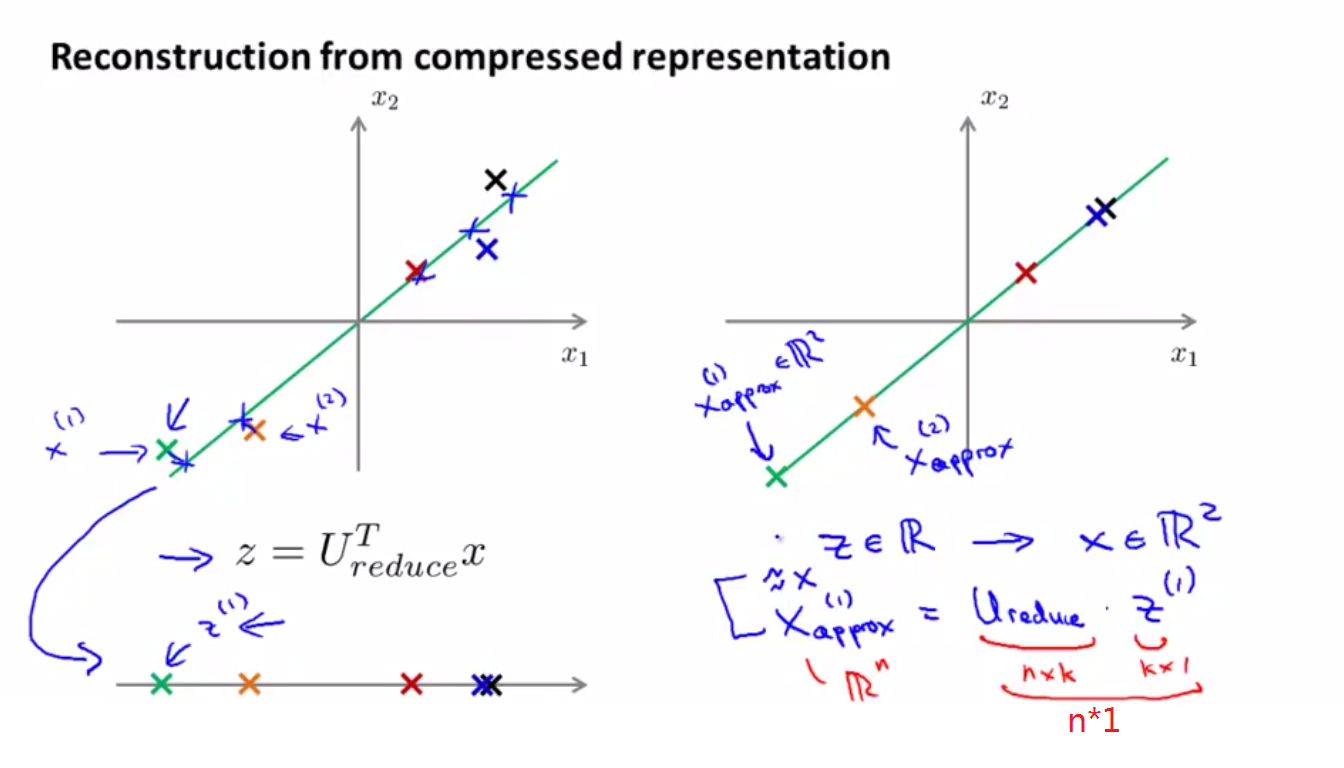
左邊的二維圖是未縮減維數之前的情況,下面的一維圖是利用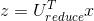
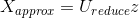
二、Choosing the Number of Principal Components(如何選擇主成分的k值)
我們應該如何選擇的值呢?
我們使用下面的不等式作為判斷值是否符合的標準:
有了這個判斷式,我們該怎麼將其應用到實踐中?
左圖是一個常見的思路,就是“試”,從k=1開始不斷嘗試,判斷k=1是否滿足不等式,直到試到k=?使得不等式成立,因此我們取k=?這個值。但是這樣需要多次計算U,x,xapprox,效率比較慢。因此我們使用第二種方式,即進行奇異值分解,能夠得到S,利用S的資料來計算不等式,比較高校。
具體步驟即為:
因為大多數資料特徵具有高度相關性,PCA滿足這個不等式時,能夠保留99%的差異性,即使是壓縮比例很大的情況下,也會看到這樣的現象。
三、Advice for Applying PCA(應用PCA的建議)
PCA是非監督學習的方法,如果我們的資料是帶有y標籤,我們應該怎樣把PCA應用起來呢?
先對訓練集的x值使用PCA得到z,再使用z替換x,得到新的訓練集,使用這個訓練集訓練資料。
PCA的主要用途如下:
在實際情況下,很多人會認為PCA可以預防過擬合問題,這個想法是錯誤的,雖然PCA看起來降維會使得特徵數更少,讓人感覺不會出現過擬合,但是PCA並不是解決過擬合的好方法,PCA把一些資料和資訊捨棄掉了,並且在對資料標籤y不知情的情況下,對資料進行降維,PCA可用於加速演算法速率,但是使用其避免過擬合併不合適。事實證明,當你使用線性迴歸或者邏輯迴歸時,使用正則化對於解決過擬合問題更好,公式如下:
另外在實際情況中,我們不能夠拿來一個數據集,就先對其進行PCA再訓練,實際上,需不需要使用PCA需要根據我們的需求,當我們的需求不需要我們使用PCA時,我們不需要非得使用它。