
Kaggle: Google Analytics Customer Revenue Prediction EDA
阿新 • • 發佈:2018-12-12
前言
內容提要
- 本文為Kaggle競賽 Google Analytics Customer Revenue Prediction 的探索性分析
- 題目要求根據歷史顧客訪問GStore的資料,預測其中部分顧客在未來的銷售額,且預測期與原資料之間不連續
- 主要切入角度為針對待預測的問題,估計出答案的合理區間(數量級水平)
專案介紹
- 專案說明:Google Analytics Customer Revenue Prediction
- 預測目標(新):根據顧客的點選資訊資料(2016.8.1 - 2018.10.15),預測2018.5.1 - 2018.10.31期間瀏覽過GStore的顧客,在2018.12.1 - 2019.1.31的消費金額(Revenue)。11月31日截止提交。
- 預測目標(原):根據瀏覽資料預測單次消費金額的常規問題,後來經過修改,題目變得極難預測,有相當比例的參賽者提交了全0的預測。
- 資料欄位:共13個列,其中fullVisitorId為顧客的唯一標識,totals中包含一些重要的彙總資訊,4列為標準的JSON格式,兩列為不標準的JSON,處理難度較大。原始列名如下:
'channelGrouping', 'customDimensions', 'date', 'device', 'fullVisitorId', 'geoNetwork', 'hits', 'socialEngagementType', 'totals', 'trafficSource', 'visitId', 'visitNumber', 'visitStartTime'
- 資料規模:train_v2.csv, 1708345條資料, 23.6GB;test_v2.csv, 401589條資料, 7.09GB。
- 評估指標:RMSE
分析工具
- Python 3.6.5 |Anaconda, Inc.| ,主要使用Spyder作為IDE
- 電腦配置:i7- 6600U, 16GB RAM,低於此配置可能無法處理這個資料集
比賽總體思路
- 每個使用者的消費總金額可以分解為客戶單次消費的平均金額和預期消費次數
- 單次平均金額可以根據歷史資料取平均,但只針對曾經購買的客戶,無法預測新增客戶
- 所以我們需要知道每個月新增購買/重複購買客戶的分佈,新增客戶在前購買前若干月份的瀏覽情況,從而推算使用者構成(新訪新消 / 老訪新消 / 老顧客)
- 對曾經購買過的客戶,對其每次瀏覽,計算下次購買時間,標記其購買型別
- 以此為參照建立模型,嘗試預測重複購買和新增購買
分析思路和歷程
- 首先用pandas讀取CSV,觀察資料,嘗試解析JSON列
- 執行多個小時之後,發現數據量太大,記憶體佔用長期接近100%,決定拆分資料集(20000條一組)
- 分別解析JSON,通過json_normalize方法解析json列,非標準json格式需要先去掉最外層中括號(literal_eval)
- 合併資料集,檢查總行數
- 缺失值分析和資料預處理
- 建立組合特徵,計算出下次購買時間,區分新增購買和重複購買
- 資料透視和描述統計,按年月彙總,估計答案大致範圍
- 嘗試建模求解
說明
- 本文的分析主要集中於使用者的瀏覽和購買行為,不包含很多分類特徵和模型,目前參賽者還沒有從這個角度分析的kernel(現有EDA主要是分類特徵的視覺化)
- 目前比賽已經結束,2019年2月公佈比賽結果
- 本文內容較多,為了閱讀體驗,較長的程式碼均被摺疊
正文
整理資料


import os import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import json from pandas.io.json import json_normalize from datetime import datetime from ast import literal_eval import warnings warnings.filterwarnings('ignore') data_path = 'C:\\Project\\Kaggle\\Revenue_Prediction\\data\\'Import Libraries
def read_df(path, file_name, nrows = None): os.chdir(path) df = pd.read_csv(file_name, dtype = {'fullVisitorId': 'str', 'visitId': 'str'}, chunksize = 10000) return df train_head = read_df(data_path, 'train_v2.csv', nrows = 10000)Read_df

可以看出資料的結構較為複雜,對於JSON列和類JSON列,需要經過處理,才能進行有效使用。在處理的過程中, 我也參考了其他參賽者分享的一些Kernels,再通過拆分計算的思想,完成了資料的解析。
def split_df(df, path, num_split): os.chdir(path) for i in range(num_split): temp = df[i*20000 : (i+1)*20000] temp.to_csv(str(i) + '.csv', index = False) print('No. %s is done.' %i) def load_df(csv_name, nrows = None): "csv_path:檔案路徑, nrows 讀取行數,JSON_COLUMNS: JSON的列" df = pd.read_csv(csv_name, converters = {column: json.loads for column in JSON_COLUMNS}, # json.loads : json --> python dtype = {'fullVisitorId': 'str', 'visitId': 'str'}, nrows = nrows) for col in NEW_COLUMNS: df[col][df[col] == "[]"] = "[{}]" df[col] = df[col].apply(literal_eval).str[0] for column in JSON_COLUMNS + NEW_COLUMNS: column_as_df = json_normalize(df[column]) # json column --> tabel(DataFrame) column_as_df.columns = [f"{column}.{subcolumn}" for subcolumn in column_as_df.columns] # f-string in Python 3.6 # Extract the product and promo names from the complex nested structure into a simple flat list: if 'hits.product' in column_as_df.columns: column_as_df['hits.v2ProductName'] = column_as_df['hits.product'].apply(lambda x: [p['v2ProductName'] for p in x] if type(x) == list else []) column_as_df['hits.v2ProductCategory'] = column_as_df['hits.product'].apply(lambda x: [p['v2ProductCategory'] for p in x] if type(x) == list else []) del column_as_df['hits.product'] if 'hits.promotion' in column_as_df.columns: column_as_df['hits.promoId'] = column_as_df['hits.promotion'].apply(lambda x: [p['promoId'] for p in x] if type(x) == list else []) column_as_df['hits.promoName'] = column_as_df['hits.promotion'].apply(lambda x: [p['promoName'] for p in x] if type(x) == list else []) del column_as_df['hits.promotion'] df = df.drop(column, axis = 1).merge(column_as_df, left_index = True, right_index = True) df.to_csv('exjson_' + csv_name.split('.')[0] + '.csv', index = False) return df def exjson(path, num): os.chdir(path) files = [str(d) + '.csv' for d in range(num)] for i in files: load_df(i) print('No. {} is done.'.format(i.split('.')[0])) def concat_df(path, num, outname): "path: path_train/path_test; num: 86/21" os.chdir(path) file_list = ['exjson_{}.csv'.format(i) for i in range(num)] df_list = [] for file in file_list: dfname = file.split('.')[0] dfname = pd.read_csv(file, dtype = {'fullVisitorId': 'str', 'visitId': 'str'}) df_list.append(dfname) df = pd.concat(df_list, ignore_index = True) df.to_csv(outname, index = False) return df def bug_fix(df): drop_list = df[df['date'] == "No"].index.tolist() df = df.drop(drop_list) print(df) return dfSome Functions
由於比較擔心計算能力,拆分、解析、組合的過程被分別執行,且儲存了過程結果,三者的主要函式見上面摺疊的程式碼。
此後又對資料做出了一些簡單處理,分離了年月日的資訊,將totals.transactionRevenue取了對數(np.log1p),去掉了缺失值過多和數值單一的列,下面將主要對瀏覽、購買次數和時間進行分析。
構造特徵
選取特徵
- fullVisitorId: 顧客的唯一標識
- visitStartTime: 顧客本次瀏覽的開始時間,以秒為計算單位,從1970-1-1 0時開始
- visitNumber: 系統對於瀏覽次數的計數,第幾次瀏覽
- totals.transactionRevenue: 當前瀏覽帶來的銷售額
- totals.hits: 當前瀏覽的點選次數
- totals.pageviews: 當前瀏覽的頁面總數
- totals.timeOnSite: 當前瀏覽的總時間 / 秒
- totals.newVisits: 當前瀏覽是否為新增瀏覽
- date: 瀏覽日期
all_precleaning = read_df(path_data, 'all_data_precleaning.csv') all_eda = all_precleaning[['fullVisitorId', 'visitStartTime', 'visitNumber', 'totals.transactionRevenue', 'totals.hits', 'totals.pageviews', 'totals.timeOnSite', 'totals.newVisits', 'date']]
all_precleaning 總共有70列,為了突出重點展示,本文只對以上特徵進行分析。
年月合併
提取年和月作為一列,方便後續分組。
all_eda['yearMonth'] = all_eda.apply(lambda x: x['date'].split('-')[0] + x['date'].split('-')[1], axis = 1)

針對使用者的特徵構建
- sumRevenue: 使用者累計購買總額
- everBuy: 使用者是否有過購買 1 / 0
- buy: 使用者當前次瀏覽,是否購買 1 / 0
- viewTimes: 使用者瀏覽總次數
- buyTimes: 使用者購買總次數
- averageRevenue: 使用者平均銷售額(僅對實際購買次數取平均)
- nextBuyTime: 下次購買時間(分析難點,需要構造輔助列buyNumber, nextBuyGroup)
- timeToBuy: 與下次購買的時間間隔
- timeToBuy.day: 與下次購買的時間間隔,換算到天
- lastVisitTime: 使用者最後一次瀏覽時間,用於查詢需要預測的全部資料條數
- revNum: 第幾次購買(分析難點,需要輔助列buyNumber)
- firstVisitTime: 首次瀏覽時間
- firstBuy: 是否為首次購買 1 / 0
- reBuy: 是否為復購 1 / 0
- sinceFirstVisit: 與第一次瀏覽的時間間隔 / 秒
- sinceFirstVisit.day: 與第一次瀏覽的時間間隔 / 天
- sinceFirstVisit.period: 與第一代瀏覽的時間間隔 / 時期 0-30-60-120-240-800
計算過程中,將僅瀏覽一次的資料單獨計算; 其餘資料根據 fullVisitorId 進行分組累計,每個分組內按照瀏覽時間由小到大排列,以便標記次數。
計算特徵的程式碼較長,摺疊於下方,結果為29列。
def add_groupby_col(df, new_column_names, by = 'fullVisitorId', agg_cols = ['totals.transactionRevenue'], aggfunc =['count']): "new_column_names: a list of col names" temp = df.groupby(by)[agg_cols].aggregate(aggfunc) temp.columns = new_column_names df = pd.merge(df, temp, left_on = 'fullVisitorId', right_index = True, how = 'left') return df def calculate_id_features(df): df = df.sort_values(by = 'visitNumber') df['buy'] = df.apply(lambda x: 1 if x['totals.transactionRevenue']>0 else 0, axis = 1) df['buyNumber'] = df['buy'].cumsum() df['nextBuyGroup'] = df['buyNumber'] - df['buy'] next_buy_time = df.groupby('nextBuyGroup').agg({'visitStartTime': 'max'}) next_buy_time.columns = ['nextBuyTime'] df = pd.merge(df, next_buy_time, left_on = 'buyNumber', right_index = True, how = 'left') df['sumRevenue'] = df['totals.transactionRevenue'].sum() df['everBuy'] = df.apply(lambda x: 1 if x['sumRevenue']>0 else 0, axis = 1) df['buyTimes'] = df['buy'].sum() df['averageRevenue'] = df.apply(lambda x: x['sumRevenue']/x['buyTimes'] if x['buyTimes']>0 else 0, axis = 1) df['firstVisitTime'] = df['visitStartTime'].min() df['lastVisitTime'] = df['visitStartTime'].max() df['sinceFirstVisit'] = df['visitStartTime'] - df['firstVisitTime'] df['sinceFirstVisit.day'] = df['sinceFirstVisit'] // (24*3600) df['sinceFirstVisit.period'] = pd.cut(df['sinceFirstVisit.day'], [-1, 30, 60, 120, 240, 800], labels = ['within30', '30-60', '60-120', '120-240', '240-800']) def get_timegap(df_l): timegap = df_l['nextBuyTime'] - df_l['visitStartTime'] if timegap > 0: return timegap df['timeToBuy'] = df.apply(lambda x: get_timegap(x), axis = 1) df['timeToBuy'].fillna(0, inplace = True) df['timeToBuy.day'] = df.apply(lambda x: x['timeToBuy']/(24*3600) if x['everBuy']==1 else -10, axis = 1) df['revNum'] = df.apply(lambda x: x['buyNumber'] if x['buy']==1 else 0, axis = 1) df['firstBuy'] = df.apply(lambda x: 1 if x['revNum']==1 else 0, axis = 1) df['reBuy'] = df.apply(lambda x: 1 if x['revNum']>1 else 0, axis = 1) return df def one_visit_features(df): df['buy'] = df.apply(lambda x: 1 if x['totals.transactionRevenue']>0 else 0, axis = 1) df['sumRevenue'] = df['totals.transactionRevenue'].sum() df['everBuy'] = df.apply(lambda x: 1 if x['sumRevenue']>0 else 0, axis = 1) #df['viewTimes'] = df['visitStartTime'].count() df['buyTimes'] = df['buy'].sum() df['averageRevenue'] = df.apply(lambda x: x['sumRevenue']/x['buyTimes'] if x['buyTimes']>0 else 0, axis = 1) df['firstVisitTime'] = df['visitStartTime'] df['lastVisitTime'] = df['visitStartTime'] df['revNum'] = df.apply(lambda x: 1 if x['buy']==1 else 0, axis = 1) df['firstBuy'] = df.apply(lambda x: 1 if x['buy']==1 else 0, axis = 1) df['reBuy'] = 0 return df all_eda = add_groupby_col(all_eda, ['viewTimes']) all_eda_oneview = all_eda[all_eda['viewTimes'] == 1] all_eda_views = all_eda[all_eda['viewTimes'] > 1] all_eda_oneview_cal = one_visit_features(all_eda_oneview) all_eda_views_cal = all_eda_views.groupby('fullVisitorId').apply(calculate_id_features) all_eda_cal = pd.concat([all_eda_views_cal, all_eda_oneview_cal], ignore_index = True) all_eda_cal.to_csv('all_eda_cal.csv', index = False)Id Features
總瀏覽次數&總購買次數分析
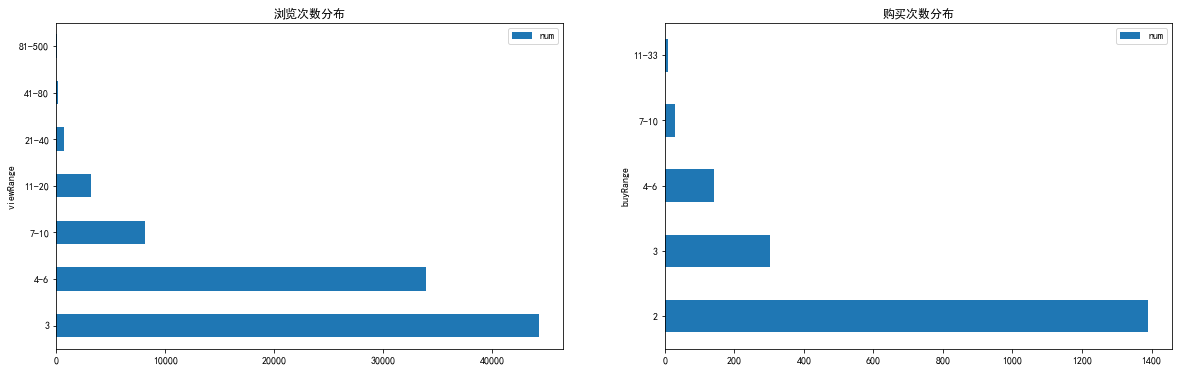
- 按次統計,劃分區間
- 瀏覽次數為1次和2次居多、購買次數絕大多數都是0
資料計算
def view_range_agg(df): "df: all_eda_cal" view_times = df.groupby('fullVisitorId').agg({'viewTimes': 'max'}) view_times_agg = view_times.groupby('viewTimes').agg({'viewTimes': 'count'}) view_times_agg.columns = ['num'] view_times_agg.reset_index(inplace = True) view_times_agg['viewRange'] = pd.cut(view_times_agg['viewTimes'], [-1, 1, 2, 3, 6, 10, 20, 40, 80, 500], labels = ['1', '2', '3', '4-6', '7-10', '11-20', '21-40', '41-80', '81-500']) result = view_times_agg.groupby('viewRange').agg({'num': 'sum'}) return result def buy_range_agg(df): "df: all_eda_agg" buy_times = df.groupby('fullVisitorId').agg({'buyTimes': 'max'}) buy_times_agg = buy_times.groupby('buyTimes').agg({'buyTimes': 'count'}) buy_times_agg.columns = ['num'] buy_times_agg.reset_index(inplace = True) buy_times_agg['buyRange'] = pd.cut(buy_times_agg['buyTimes'], [-1, 0, 1, 2, 3, 6, 10, 33], labels = ['0', '1', '2', '3', '4-6', '7-10', '11-33']) result = buy_times_agg.groupby('buyRange').agg({'num': 'sum'}) return result view_range = view_range_agg(all_eda_cal) buy_range = buy_range_agg(all_eda_cal) print('瀏覽次數分佈如下:') print(view_range) print('-' * 10) print('購買次數分佈如下:') print(buy_range)Times Calculate

原始圖表
包含所有取值可能,會導致部分資料無法獲得直觀展示
plt.rcParams['font.sans-serif']=['SimHei'] fig,axes = plt.subplots(1,2,figsize = (20,6)) view_range.plot.barh(ax = axes[0]) axes[0].set_title('瀏覽次數分佈') buy_range.plot.barh(ax = axes[1]) axes[1].set_title('購買次數分佈')Pic1

放大圖表
- 除去瀏覽次數為0和1的圖形
- 除去購買次數為0和1的圖形
fig,axes = plt.subplots(1,2,figsize = (20,6)) view_range[2:].plot.barh(ax = axes[0]) axes[0].set_title('瀏覽次數分佈') buy_range[2:].plot.barh(ax = axes[1]) axes[1].set_title('購買次數分佈')Pic2
按照年月進行分組統計
- 指標包括: 瀏覽次數、購買次數、新增瀏覽、總銷售額、新增購買次數、重複購買次數、新增購買收入、重複購買收入等
- 對資料中的每個月,繪製瀏覽次數、新增瀏覽、購買次數、新增購買、重複購買的對比折線圖
- 資料中10月只有15天,所以資料量小屬於正常現象
特徵計算
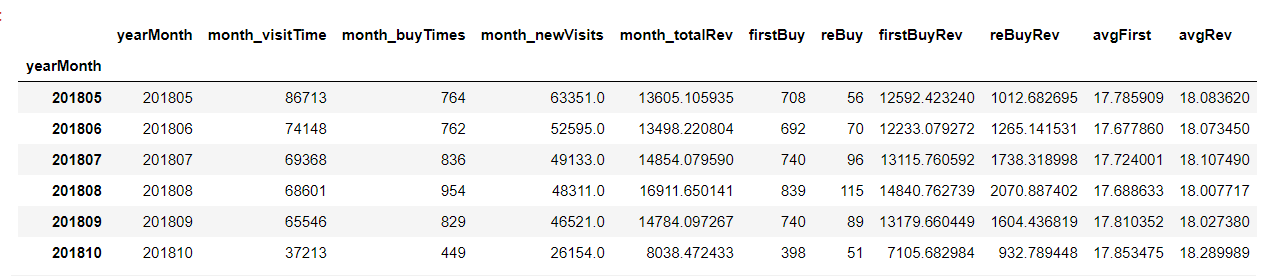
def yearMonth_des(df): "df: all_eda_cal" # 總購買數 新增瀏覽 總銷售額 yearmonth_1 = df.groupby('yearMonth').agg({'buy': 'sum', 'totals.newVisits': 'sum', 'totals.transactionRevenue': 'sum'}) yearmonth_1.columns = ['month_buyTimes', 'month_newVisits', 'month_totalRev'] # 總瀏覽數 yearmonth_visit_time = df.groupby('yearMonth').apply(lambda x: len(x)).reset_index() yearmonth_visit_time.columns = ['yearMonth', 'month_visitTime'] yearmonth_visit_time.index = yearmonth_visit_time['yearMonth'] # 新增購買 / 重複購買 銷售額 # 此時的重複購買指:不是第一次購買,有可能第一次購買就發生於當月 first_buy_rev = df[df['firstBuy']==1].groupby('yearMonth').agg({'totals.transactionRevenue': 'sum'}) rebuy_rev = df[df['reBuy']==1].groupby('yearMonth').agg({'totals.transactionRevenue': 'sum'}) first_buy_rev.columns = ['firstBuyRev'] rebuy_rev.columns = ['reBuyRev'] # 統計新增/重複購買人數 按年月分組 yearmonth_2 = df.groupby('yearMonth').agg({'firstBuy': 'sum', 'reBuy': 'sum'}) # 將分散的groupby特徵整合到一起 yearmonth_des = pd.concat([yearmonth_visit_time, yearmonth_1, yearmonth_2, first_buy_rev, rebuy_rev], axis = 1) # 計算首次購買和重複購買的金額均值 yearmonth_des['avgFirst'] = yearmonth_des['firstBuyRev'] / yearmonth_des['firstBuy'] yearmonth_des['avgRev'] = yearmonth_des['reBuyRev'] / yearmonth_des['reBuy'] #yearmonth_des.to_csv('yearmonth_group.csv', index = False) return yearmonth_des yearmonth_des = yearMonth_des(all_eda_cal) yearmonth_des.index = yearmonth_des.index.astype(str) yearmonth_des.tail(6)yearMonth_des
月瀏覽次數和購買次數折線圖
fig, ax = plt.subplots(2, 1, figsize = (20, 16)) ax[0].plot(yearmonth_des['month_visitTime']) ax[0].plot(yearmonth_des['month_newVisits']) ax[0].plot(yearmonth_des['month_buyTimes']) ax[0].legend() ax[0].set_title('瀏覽次數 新增瀏覽 購買次數') ax[1].plot(yearmonth_des['month_buyTimes']) ax[1].plot(yearmonth_des['firstBuy']) ax[1].plot(yearmonth_des['reBuy']) ax[1].legend() ax[1].set_title('購買次數 首次購買 重複購買')Pic3
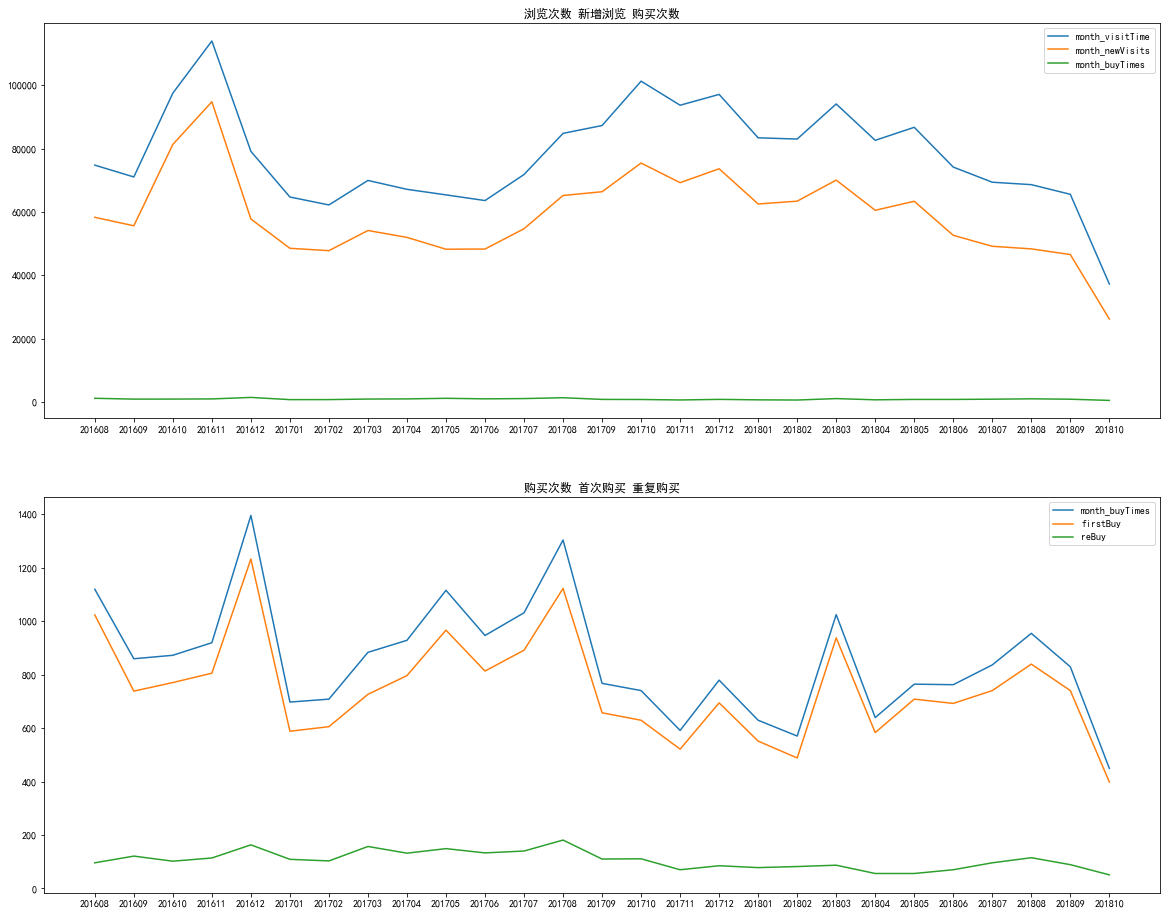
- 由上圖可以觀察到每個月瀏覽次數大約為8000次左右,波動性主要與新增瀏覽相關
- 月購買次數大約在1000次左右,很大比例都是新增購買,二者波動有很大的相關性
- 重複購買數量相對穩定,平均在100次左右
- 2018年5月左右,購買次數存在波谷,正好是訓練集和測試集的連線處,可能競賽資料並非全資料,待下一步分析
- 瀏覽和購買次數之間存在一定的相關性,但程度並不高
- 次數預測可以分解為新增購買和重複購買
每個月購買次數的資料透視
- 前面的分析將購買次數劃分為了首次和重複,並且在總體上對購買次數進行了統計
- 此時可以進行按月統計,檢視有無顯著規律
yearmonth_buy_pivo
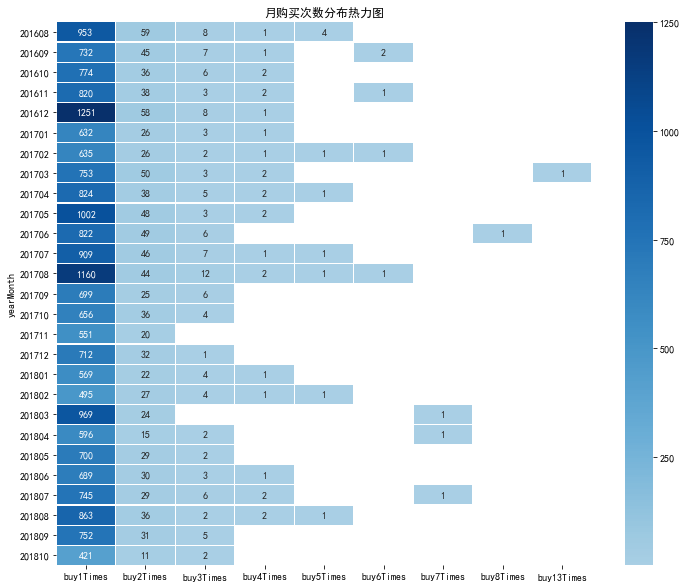
- 從圖中可以觀察到每個月購買三次以上的顧客十分少見
- 購買2-3次的顧客每月大約30人
- 此時還不能確定在一個月內大量購買的顧客的後續表現
首次購買時的瀏覽次數分佈
## 表2 # 首次購買的使用者需要的瀏覽次數 區間 all_eda_cal['visitNumRange'] = pd.cut(all_eda_cal['visitNumber'], [0, 1, 2, 5, 10, 20, 388], labels = ['1', '2', '3-5', '6-10', '11-20', '21-388']) firstBuy_visitNum_pivot = all_eda_cal[all_eda_cal['firstBuy']==1].pivot_table(index = 'yearMonth', columns = 'visitNumRange', aggfunc = {'visitNumRange': 'count'}) firstBuy_visitNum_pivot.tail(6) plt.figure(figsize = (12, 10)) #yearmonth_buy_pivot.fillna(0, inplace = True) sns.heatmap(firstBuy_visitNum_pivot, annot = True, # 是否顯示數值 fmt = '.0f', # 格式化字串 linewidths = 0.1, # 格子邊線寬度 center = 300, # 調色盤的色彩中心值,若沒有指定,則以cmap為主 cmap = 'Blues', # 設定調色盤 cbar = True, # 是否顯示圖例色帶 #cbar_kws={"orientation": "horizontal"}, # 是否橫向顯示圖例色帶 #square = True, # 是否正方形顯示圖表 ) plt.title('首次購買時的瀏覽次數分佈')View Code
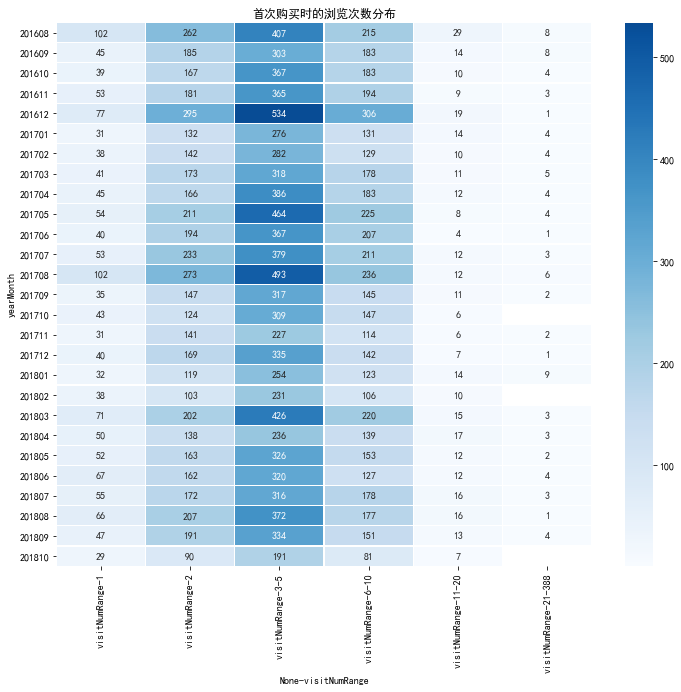
- 觀察上圖可知完成首次購買的時候,瀏覽次數主要集中於3-5次(2-10次)
- 但不能得知次數的時間跨度
購買與首次瀏覽的間隔分佈
- 時間間隔被劃分為區間進行統計
- 考慮到最後的預測目標,應主要關注60-240天的資料
## 表3表4 # 首次購買和重複購買與首次瀏覽時間間隔的分佈 firstBuy_sinceFisrtVisit_pivot = all_eda_cal[all_eda_cal['firstBuy']==1].pivot_table(index = 'yearMonth', columns = 'sinceFirstVisit.period', aggfunc = {'sinceFirstVisit.period': 'count'}) reBuy_sinceFisrtVisit_pivot = all_eda_cal[all_eda_cal['reBuy']==1].pivot_table(index = 'yearMonth', columns = 'sinceFirstVisit.period', aggfunc = {'sinceFirstVisit.period': 'count'}) firstBuy_sinceFisrtVisit_pivot.columns = [['120-240', '240-800', '30-60', '60-120', 'within30']] reBuy_sinceFisrtVisit_pivot.columns = [['120-240', '240-800', '30-60', '60-120', 'within30']] firstBuy_sinceFisrtVisit_pivot = firstBuy_sinceFisrtVisit_pivot[['within30', '30-60', '60-120', '120-240', '240-800']] reBuy_sinceFisrtVisit_pivot = reBuy_sinceFisrtVisit_pivot[['within30', '30-60', '60-120', '120-240', '240-800']] firstBuy_sinceFisrtVisit_pivot.tail(6)View Code

首次購買與首次瀏覽的時間間隔
plt.figure(figsize = (12, 10)) #yearmonth_buy_pivot.fillna(0, inplace = True) sns.heatmap(firstBuy_sinceFisrtVisit_pivot.drop('within30', axis = 1), annot = True, # 是否顯示數值 fmt = '.0f', # 格式化字串 linewidths = 0.1, # 格子邊線寬度 center = 30, # 調色盤的色彩中心值,若沒有指定,則以cmap為主 cmap = 'Blues', # 設定調色盤 cbar = True, # 是否顯示圖例色帶 #cbar_kws={"orientation": "horizontal"}, # 是否橫向顯示圖例色帶 #square = True, # 是否正方形顯示圖表 ) plt.title('首次購買與首次瀏覽的時間間隔')View Code
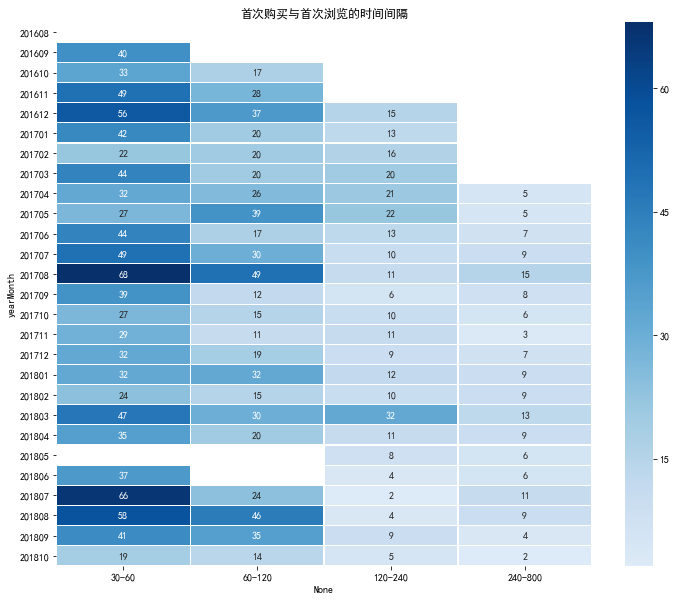
- 首次購買和首次瀏覽的間隔主要集中於30天之內,由於沒有2018.10.16-2018.11.30日資料,無需關注
- 2018年5月處出先斷層,屬於嚴重的異常,可以得知競賽資料並非GStore全部資料,訓練集/測試集分別提取了一部分
- 間隔在60-240天之間每月大約30次左右(佔比很低)
重複購買與首次瀏覽的時間間隔
plt.figure(figsize = (12, 10)) #yearmonth_buy_pivot.fillna(0, inplace = True) sns.heatmap(reBuy_sinceFisrtVisit_pivot, annot = True, # 是否顯示數值 fmt = '.0f', # 格式化字串 linewidths = 0.1, # 格子邊線寬度 center = 35, # 調色盤的色彩中心值,若沒有指定,則以cmap為主 cmap = 'Blues', # 設定調色盤 cbar = True, # 是否顯示圖例色帶 #cbar_kws={"orientation": "horizontal"}, # 是否橫向顯示圖例色帶 #square = True, # 是否正方形顯示圖表 ) plt.title('重複購買與首次瀏覽的時間間隔')View Code
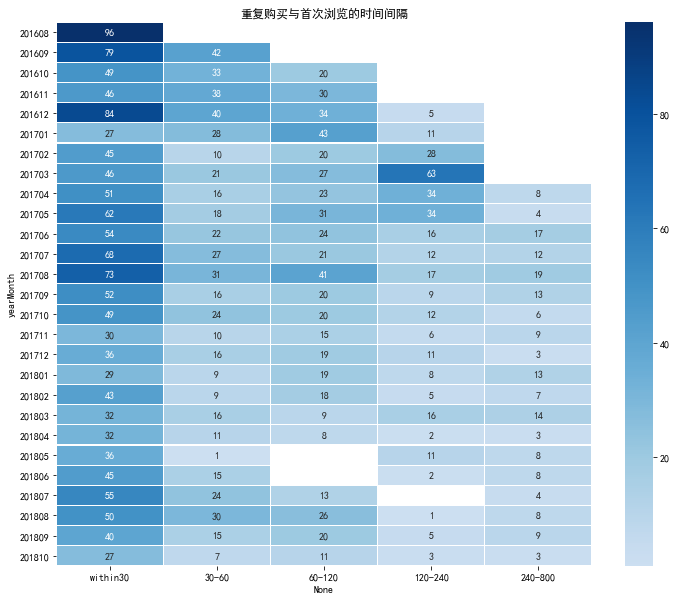
- 分析可知,預測期現有資料中重複購買的顧客數量大約在50-80
至此,我們已經對這個預測問題的基本情況有了一個初步的認識,這些資料可以為自己的交叉驗證做出有效的補充。