
Spark2原理分析-DAGScheduler(Stage排程器)的基本概念
概述
本文介紹Saprk中DAGScheduler的基本概念。該物件實現了一個面向Stage的高層排程器。它為每個Job計算一個Stage的DAG圖,並跟蹤這些RDD和Stage的輸出,並找到一個最小的代價的DAG圖來執行該Job。
DAGScheduler介紹
在文章《spark2原理分析-Stage的實現原理》中,介紹了Stage的基本概念和Stage的提交實現原理。本文主要介紹 DAGScheduler排程器的實現。
DAGScheduler是spark的較高層次的排程器,它實現了stage-oriented(面向stage)的排程。它為每個job的stages計算並建立一個DAG,跟蹤RDD和stage的輸出。並找出一個最小代價的DAG去執行。然後,它把stage作為TaskSets提交給在叢集上執行的TaskScheduler。一個TaskSet包含全部的可以立即執行的獨立任務,這些任務基於目前叢集中已經存在的資料執行,這些任務可能會執行失敗。
RDD 2 Stage:
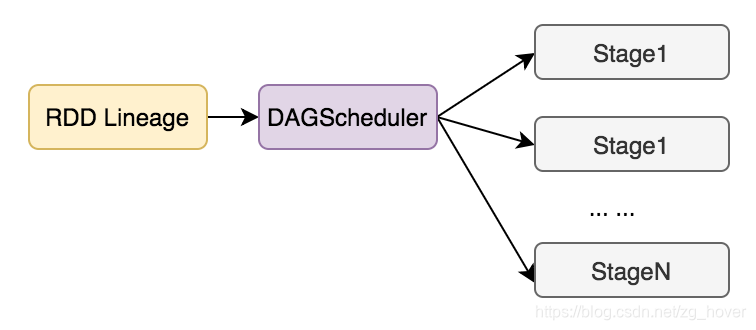
DAGScheduler的功能
- 為每個Job計算一個DAG圖(根據rdd和父rdd的lineage來建立)
- 基於目前的cache的狀態決定執行每個task的最佳位置,並把它們傳遞給TaskScheduler
- 處理由於shuffle輸出檔案丟失而產生的錯誤,可能會重新提交舊的stage。
為避免重複計算,DAGScheduler標記處哪些rdd已經被快取。同樣,會記錄哪些在進行shuffle的map stage已經產生了輸出檔案,從而避免重複執行shuffle的map操作。
DAGScheduler會基於rdd的依賴關係,快取或shuffling資料的位置來計算執行任務的最佳位置。
當任務執行完成後,所有的資料結構都會被清空。
為了從失敗中恢復,同樣的stage可能會執行多次。若由於前一個stage的map輸出檔案丟失,TaskScheduler報告了一個任務失敗,DAGScheduler會重新提交丟失的stage。這是通過一個帶有FetchFailed或ExecutorLost的CompletionEvent事件檢測到的。DAGScheduler將等待一小段時間以檢視其他節點或任務是否失敗,然後為任何缺失的階段(Stage)重新提交TaskSet(任務集)。
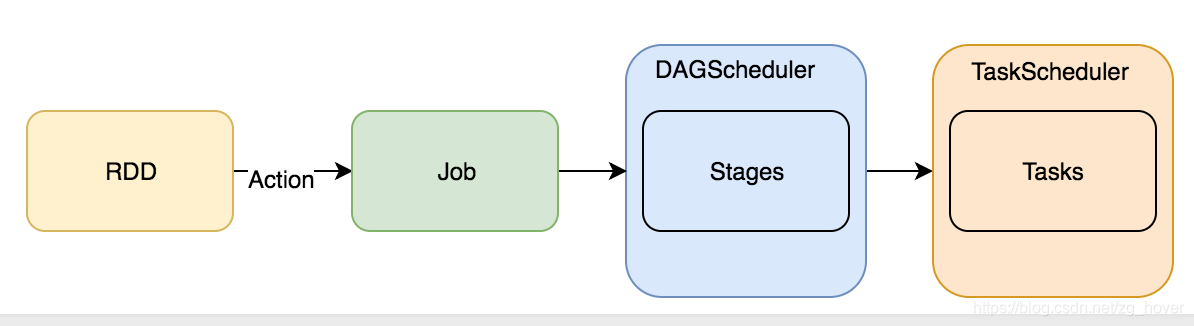
DAGScheduler的使用
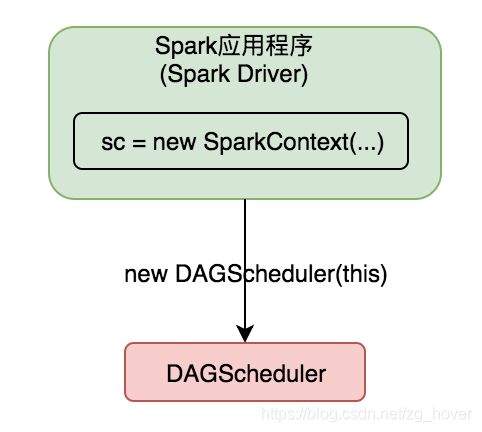
DAGScheduler例項在SparkContext中建立,SparkContext會把自己的成員變數,作為引數傳遞給DAGScheduler的建構函式。
如下圖所示:
總結
本文對DAGScheduler的功能和使用相關概念進行了介紹,接下來的文章會詳細分析DAGScheduler的實現原理,並對實現程式碼進行相應的剖析。