
spark2原理分析-Stage的實現原理
概述
本文介紹Spark任務執行框架中Stage的原理,並分析其實現機制。
Stage的基本概念
一個Stage是一個並行任務(Task實體)集,它們執行相同的計算邏輯,並作為Spark任務執行的一部分,所有的任務都具有相同的shuffle依賴。
排程器執行的每個任務DAG,在shuffle的邊界處(發生shuffling時)被分解成多個stage,然後DAGScheduler以拓撲順序執行這些階段(Stage)。
前面一篇介紹Job的文章中提到過,Job中的分割槽對應RDD的分割槽,而在Spark中RDD中的一個分割槽對應了Stage中的一個任務,它屬於一個RDD用於計算執行函式的部分結果,這些結果作為Spark Job的一部分。
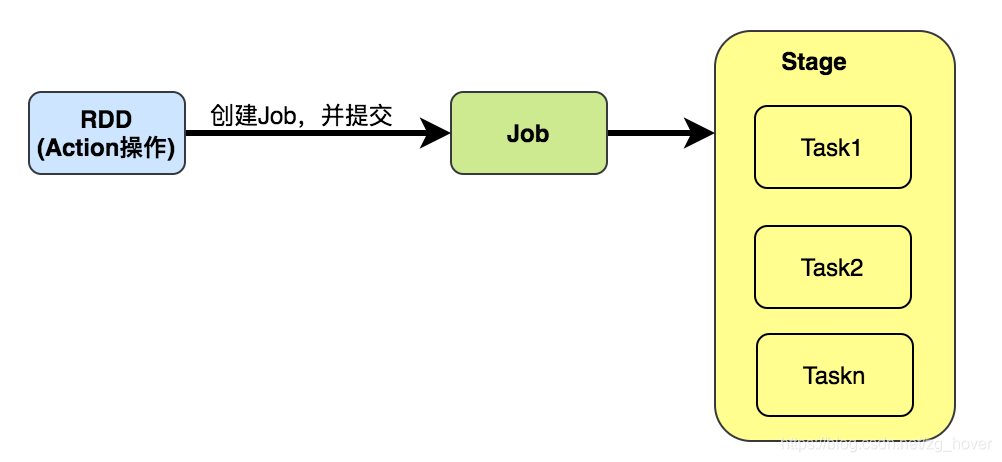
DAGScheduler將一個Job分成Stage集。每個Stage包含一系列narrow transformations(窄轉換),這些轉換操作可以在不進行shuffling的情況下完成,這些階段在shuffle的邊界(例如:shuffle發生的地方)處被分離,因此,可以說Stage是RDD graph在shuffle階段分裂的結果。
在每個階段RDD的窄轉換(例如:map()或filter()等)操作被pipeline(多個任務形成流水線,中間結果在記憶體中,以便加快計算效能)成一個任務集,但是shuffle操作卻需要依賴多個Stage。
在Stage生命中的某個時間點,Stage的每個分割槽都會轉換為一個Tasks - 分別為ShuffleMapStage和ResultStage的ShuffleMapTask和ResultTask。
分割槽在Job中計算,並且結果階段可能並不總是需要計算其目標RDD中的所有分割槽,例如,對於first()和lookup()等操作。

Stage的實現合約
在Spark中,有兩種不同的Stage,實現這兩種型別的Stage需要遵循Stage的實現合約(實現Stage抽象類)。
Stage的抽象類宣告如下:
private[scheduler] abstract class Stage
為了能夠更好的理解後面的兩種具體的Stage,下面對Stage的抽象類的成員做一個說明:
| 成員名 | 型別 | 說明 |
|---|---|---|
| id | Int | Stage的id,是Stage的唯一標識 |
| rdd | RDD[_] | 此Stage依賴的Stage列表(通過shuffle依賴關係得到) |
| numTasks | Int | 此Stage的總任務數。 |
| parents | List[Stage] | 此Stage依賴的Stage列表 |
| firstJobId | Int | 對於FIFO排程來說,此變數是此Stage屬於的第一個Job的ID |
| callSite | CallSite | 使用者編寫的程式中與該Stage相關的部分 |
| numPartitions | Int | RDD的分割槽數 |
| jobIds | 此Stage屬於的Job集 | |
| nextAttemptId | 此Stage下一次嘗試的ID | |
| _latestInfo | 返回最近的Stage資訊結構:StageInfo | |
| fetchFailedAttemptIds | 記錄Stage嘗試失敗的次數 | |
| makeNewStageAttempt | 為該Stage建立一個新的StageInfo和ID | |
| latestInfo | 返回該Stage最新的StageInfo資訊 | |
| findMissingPartitions | 返回需要計算(missing)但還沒計算的分割槽id集合 |
對於這些成員,有幾個需要重點說明:
- numTasks
該成員代表的是Stage的總任務數。但對於result stages可能不需要計算所有分割槽,例如:first(),lookup(),take()等。
ResultStage
ResultStages階段在RDD的各個分割槽上執行一些功能函式,來處理RDD的Action轉換的執行結果。
該實體的定義如下:
private[spark] class ResultStage(
id: Int,
rdd: RDD[_],
val func: (TaskContext, Iterator[_]) => _,
val partitions: Array[Int],
parents: List[Stage],
firstJobId: Int,
callSite: CallSite)
extends Stage(id, rdd, partitions.length, parents, firstJobId, callSite) {
ResultStage物件會捕獲函式func去執行,並把該函式應用引數’partitions’表示的分割槽ID集中的每一個分割槽。
注意:ResultStage是Job的最後一個Stage。
在提交Stage時會先遞迴找到該Stage依賴的父級Stage,並先提交父級Stage。
ShuffleMapStage
在執行Stage的DAG(有向無環圖)中,ShuffleMapStage是一箇中間階段,為其他階段生成資料。
它為一個shuffle過程產生map操作的輸出檔案。它也可能是自適應查詢規劃/自適應排程工作的最後階段。
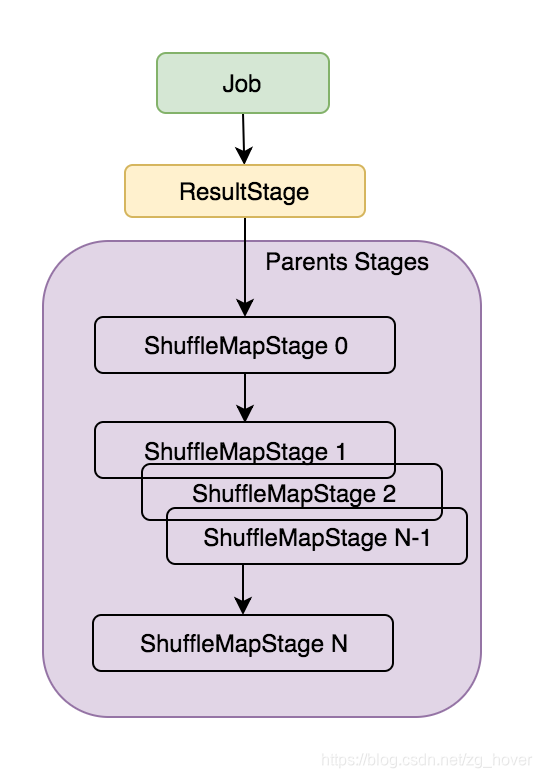
Stage的提交過程
通過上一節的分析可知,在提交Job時會先建立一個ResultStage,再根據RDD的血緣關係(lineage)查詢與ResultStage相關聯的RDD的分割槽,再根據這些分割槽來建立新的Stage。
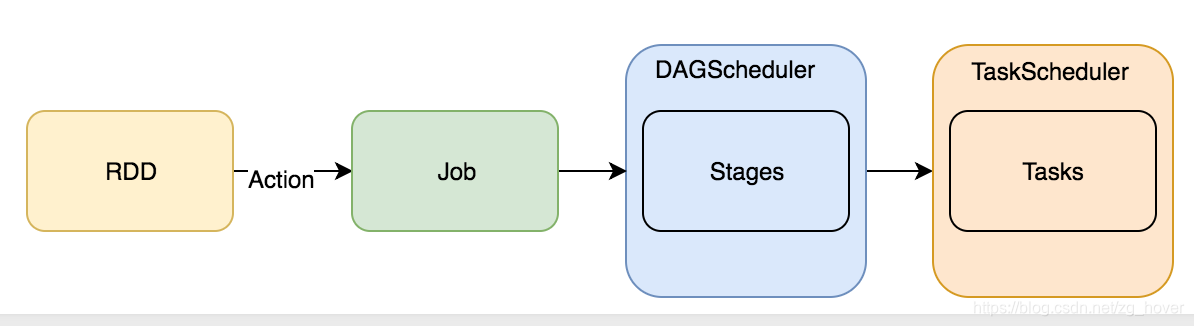
下圖是Job提交的總體流程:
下圖是提交Stage的流程:
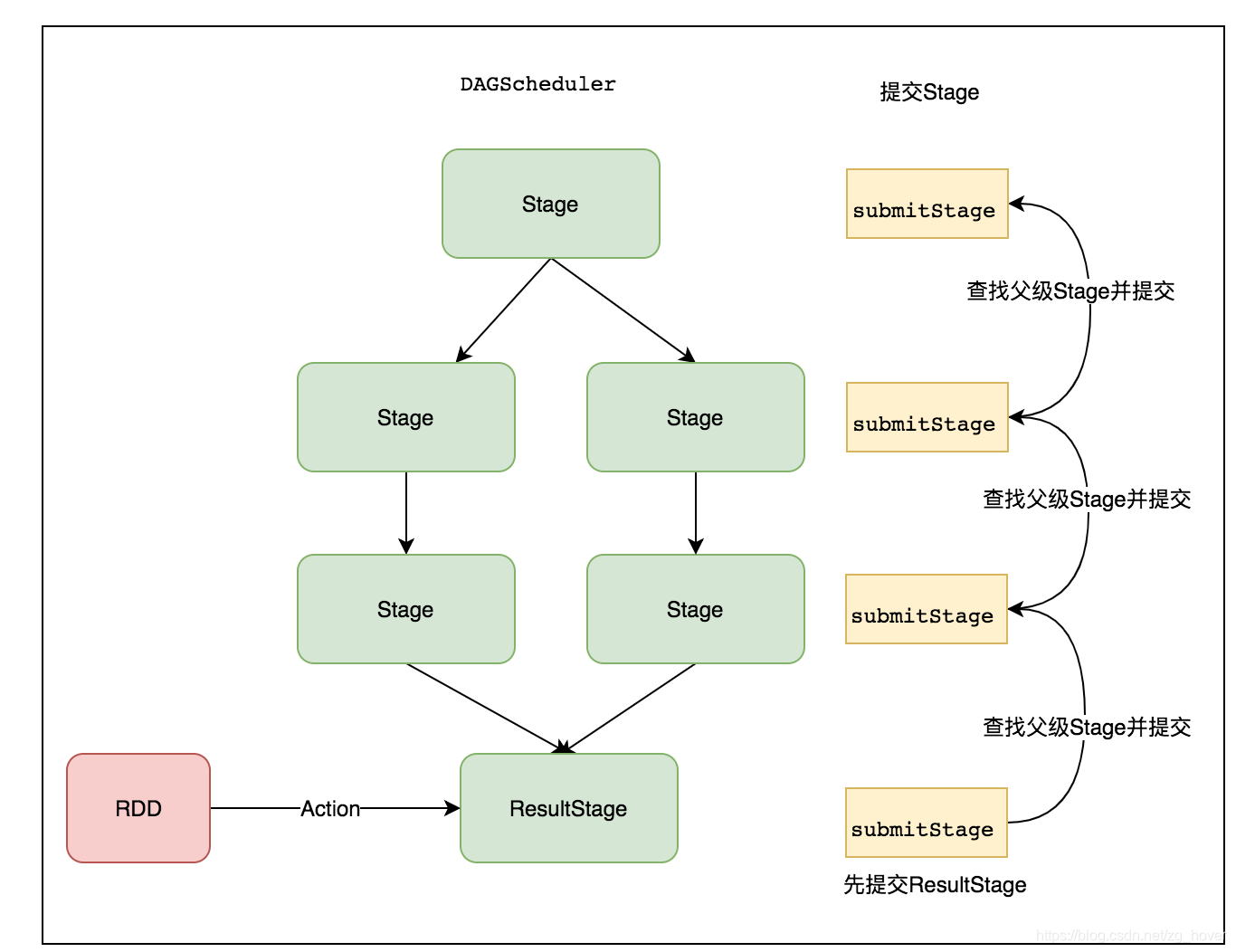
在提交Stage時,也是通過遞迴提交最先依賴的Stage,最後提交ResultStage。實現過程如下:
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
...
// 建立一個階段:最後的一個階段
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
...
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
// 向事件處理匯流排發起SparkListenerJobStart事件(會在後面的文章中講到)
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
// 提交最後一個階段
submitStage(finalStage)
我們看一下階段的提交的實現,階段提交在submitStage函式中實現:
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
...
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 查詢並獲取依賴的父Stage
val missing = getMissingParentStages(stage).sortBy(_.id)
...
if (missing.isEmpty) {
...
// 已經找到全部的依賴Stage並已提交,最後提交最後一個Stage
submitMissingTasks(stage, jobId.get)
} else {
// 先提交依賴的父Stage
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
從提交Stage的程式碼實現中可以看出,先建立最後一個Stage,而在提交時,提交Stage時會先提交依賴的父Stage。
總結
本文說明了Stage的實現原理,並對Stage的提交過程進行了分析。