
spark2原理分析-Job執行框架概述
概述
本文描述了Spark2的job的實現框架,並對其各個組成部分進行了介紹。
spark的Job介紹
從前面的文章中我們知道:一般來說Spark RDD的轉換函式(transformation)不會執行任何動作,而當Spark在執行RDD的action函式時,Spark排程程式(scheduler)會構建執行圖(graph)併發起一個Spark作業(Job)。
Job由很多的Stage構成,這些Stage是在轉換中實現最終RDD所需資料的步驟。
每個Stage由一組在執行器(executor)上平行計算的任務(task)構成。
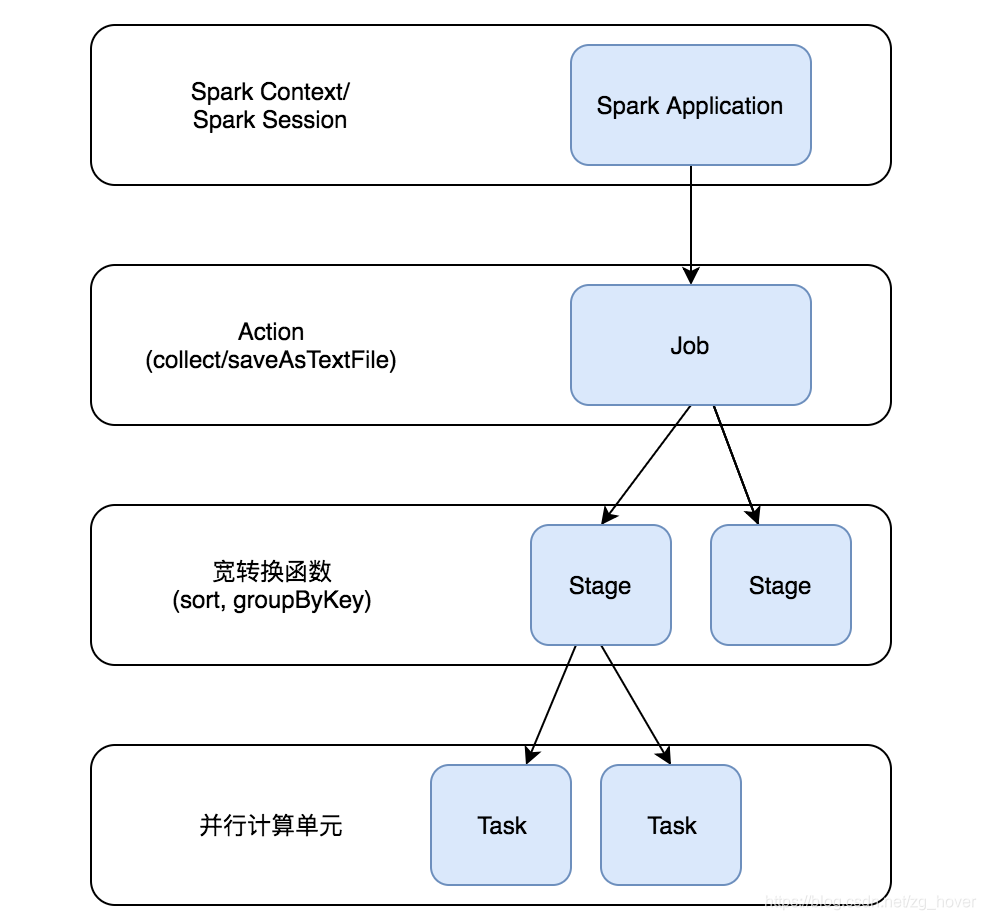
上圖說明了Job->Stage->Task的建立過程:
- 通過SparkContext或SparkSession來執行應用程式
- 在應用程式中若有Action操作,此時會生成Job,並提交
- 若在Job中需要進行寬轉換等操作,則會建立若干的Stage
- Stage會創建出一系列的Task,這些Task會在各個執行器(executor)中並行執行
DAG
在Spark任務排程的高的層面,Spark會根據RDD的依賴關係,為每個Job構建Stage的有向無環圖(DAG)。在Spark中,這被稱為DAG Scheduler。
DAG Scheduler為每個Job構建一個stage graph,確定執行每個任務(Task)的位置,並將該資訊傳遞給TaskScheduler。TaskScheduler負責在叢集上執行任務。 TaskScheduler建立一個包含分割槽之間依賴關係的圖(graph)。
DAGScheduler
實現面向階段(Stage)的高層次的排程。 它為每個Job計算出一個由Stage組成的DAG,跟蹤RDD和Stage的輸出,並找到執行Job的最小執行計劃。
然後,它將階段(Stage)作為TaskSets提交給已經實現的TaskScheduler,再由TaskScheduler在叢集上執行TaskSets。
TaskSet包含完全獨立的任務,這些可以根據群集中已有的資料立即執行(例如,對映前一階段的輸出檔案),但如果此資料不可用,則任務可能會失敗。
DAGScheduler除了建立Stage的DAG,它們還會根據目前的cache狀態來決定執行每個任務(task)的最優位置,並把這些任務傳送給較低層次的TaskScheduler。同時,它還會處理由於shuffle輸出檔案丟失產生的失敗任務,這種失敗會導致一些已經計算過的Stage從新被提交。不是由shuffle檔案丟失引起的Stage內的失敗由TaskScheduler處理,它將在取消整個Stages之前重試每個任務小几次。
Job
Job由[[ActiveJob]]表示,是提交給排程程式(scheduler)的頂級工作項。例如,當用戶呼叫一個action操作函式(如count())時,將會通過submitJob提交作業。每個作業(Job)可能需要執行多個階段(Stage)來構建中間資料。
Stages
Stage是job中一組計算中間結果的任務集,每個task在相同的RDD的分割槽上執行計算。
有兩種型別的Stage(階段):[[ResultStage]],用於執行Action(動作)的最後階段,[[ShuffleMapStage]],用於為shuffle寫入graph(地圖)輸出檔案。若這些Job重複使用相同的RDD,則Stage通常會在多個Job中共享。
Tasks
每個Stage由一組Task組成。Task(任務)是執行層次結構中的最小單元,每個單元可以表示一個本地計算。
一個階段中的所有任務在不同的資料片段上執行相同的程式碼。一個Task不能在多個執行器(executor)上執行。
但是,每個執行器(executor)都有一個動態分配器的資源數用來執行任務,並且可以在其生命週期內併發執行多個任務。
每個階段(Stage)的任務數對應於該階段的輸出RDD的分割槽數。
總結
本文介紹了Spark Job的執行框架,對給執行框架中的各個成員進行了簡要的說明。後續的文章將詳細分析Spark Job執行框架中的各個成員的實現原理。