
VoxelNet: 基於點雲的三維空間資訊逐層次學習網路

量化結果。使用LiDAR檢測的3D BoundingBox被投影到RGB影象
1. 論文綜述
3D點雲中目標的精準檢測是很多應用場景的核心問題,如自動駕駛,家居機器人,虛擬/增強現實。為了將高度稀疏的LiDAR點雲與區域候選網路連線在一起,很多研究學者將關注帶你放在手工設計的特徵表達,例如鳥瞰投影a bird's eye view projection. 這份工作中作者放棄了人工設計特徵,直接提出了端到端的VoxelNet進行3D目標檢測。具體來說,VoxelNet將點雲劃分為等間距的三維體素,並通過新引入的體素特徵編碼(VFE)層將每個體素內的一組點轉換為統一的特徵表示。這樣,點雲可以被編碼成可以描述的體積表徵,進而他被量接到區域候選網路進行目標檢測。在KITTI資料集上,作者的方法取得了最好的結果。
- VoxelNet是一種基於點雲的-可訓練的-端到端的-3D目標識別框架,可以直接作用於係數的3D點雲,避免了特徵工程;
- 該框架融合了稀疏點雲結構,並且充分利用了voxel grid的並行處理
- 該文也提出了一種有效的資料增強策略
在基於LiDAR的3D目標檢測任務中,大多數方法均採用了特徵工程的方法進行演算法設計,最多的就是鳥瞰視覺投影。作者創新性的移除了人為的特徵工程,並提出了有效的端到端的VoxelNet-3D detection框架。該方法最大的亮點在於可以直接操作3D點雲資料並且捕捉到3D點雲中的形狀資訊。
2. 主幹和細節
將三維點雲劃分為一定數量的Voxel
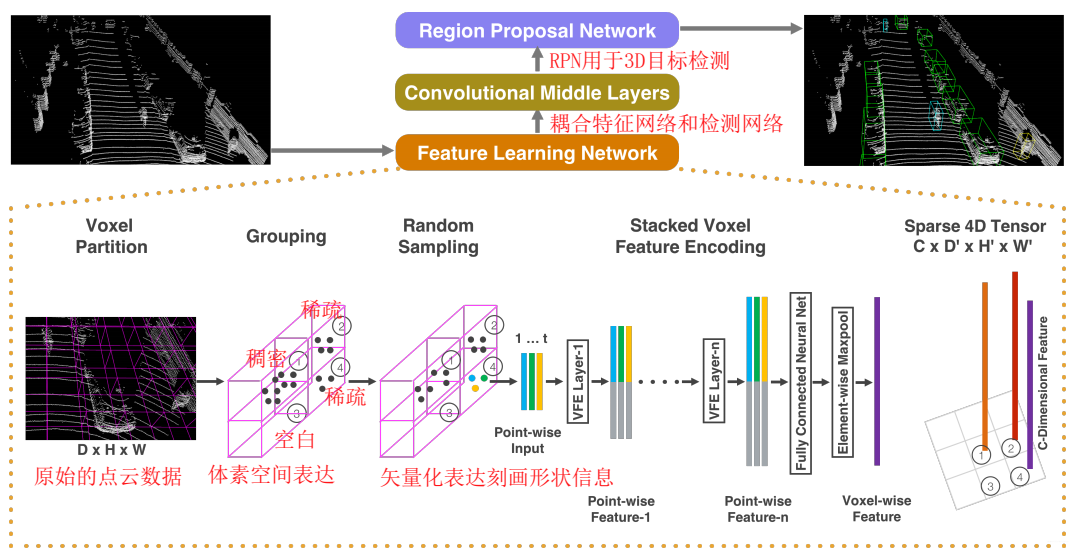
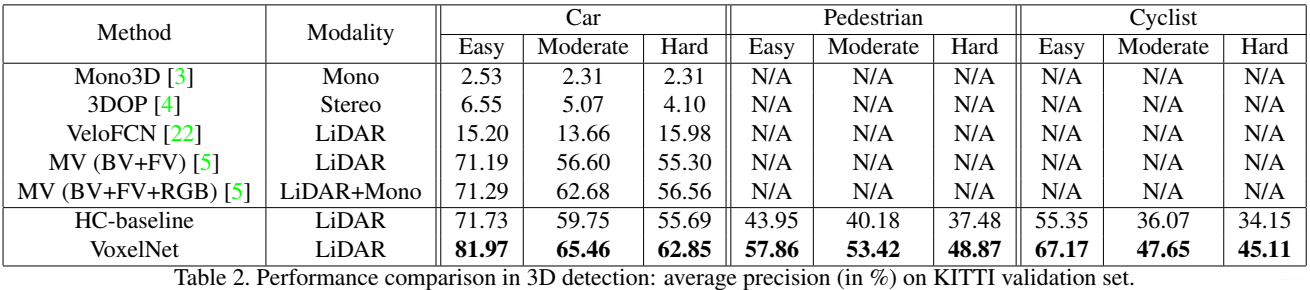
VoxelNet網路結構. 特徵學習網路直接輸入原始的3D點雲資料,然後將整個3D空間劃分成獨立的小voxel,每個voxel都採用特徵提取網路進行特徵提取,最後將各個特徵按照原來的幾何結構拼接在一起[這就是我們之前經常說的Global=Multi-Parts]。這樣做的目的應該是為了抵抗形變。Middle Layer的目標在於增大感受野,提取更加高階的語義特徵。最後交給3D-RPN網路進行BoundingBox迴歸。
2.1 點雲的多層次學習
VoxelNet是對PointNet以及PointNet++這兩項工作的拓展與改進,粗淺地說,是對點雲劃分後的Voxel使用"PointNet"。我們可以仔細看一下某一層VFE,如下圖所示,一塊Voxel中的三個點經過FCN抽象Point-wise feature,並使用MaxPool得到Locally Aggregated Feature(區域性聚合特徵),然後將這個區域性特徵concatenate到每一個Point-wise feature上。
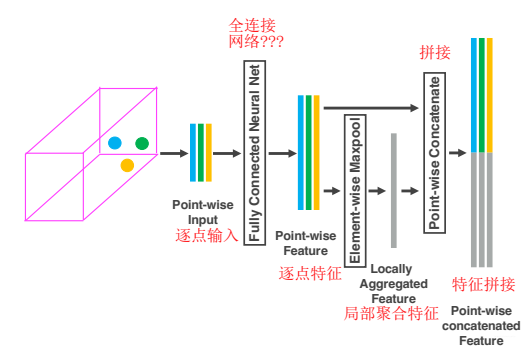
針對每一個Voxel提取特徵 [逐點特徵+區域性聚合特徵]
2.2 點雲的高效查詢
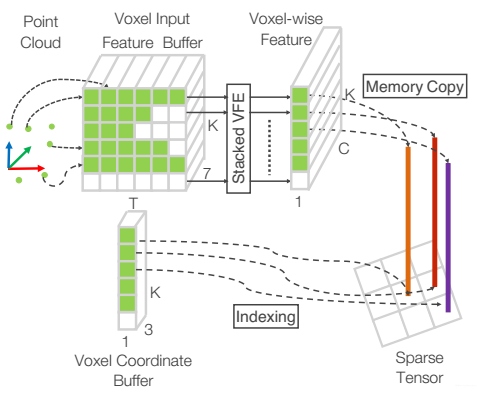
此外,由於點雲具有高度的稀疏性以及密度不均勻性,作者利用雜湊表查詢的方式,可以做到快速找到每一個Voxel中的點在三維點雲中的具體位置,如下圖所示。
3. 論文總結
3.1 思考
VoxelNet只使用鐳射雷達資料,在KITTI上取得了state-of-the-art的效果。目前,3D Object Detection(Car)榜單第一名VoxelNet++也僅僅是隻使用了點雲,相對於榜單中同時使用點雲以及RGB影象並採用fusion操作的其他幾種方法,VoxelNet能夠領先有些耐人尋味。廖子對於這種異常資訊融合的結果解釋如下:
- 在3D場景中,RGB資訊對3D Detection不是特別重要。因為汽車、自行車、人這三類物體僅僅通過外形輪廓就能夠區分出來,如果網路能夠很好地學習到這些幾何空間特徵,那麼只需要點雲就能得到很好的效果。但是如果是針對3D Instance Segmentation這類任務,比如區分黃車與黑車,LiDAR data與RGB data之間進行fusion就很有必要了。
- 直接將兩種data(或者兩者對應的feature map)進行fusion操作,這種資料處理方式可能會使得神經網路不容易去學習更好的特徵。比如人具備顏色資訊感知與空間位置感知,但是這兩種感知並不是混為一談的,兩者應該是並行且存在互動的關係,這種互動關係可能比目前先concatenate再通過若干層全連線層的fusion機制要更加高階抽象。
3.2 論文金句總結
- Compared to imagebased detection, LiDAR provides reliable depth information that can be used to accurately localize objects and characterize their shapes
- We present VoxelNet, a generic 3D detection framework that simultaneously learns a discriminative feature representation from point clouds and predicts accurate 3D bounding boxes, in an end-to-end fashion. We design a novel voxel feature encoding (VFE) layer, which enables inter-point interaction within a voxel, by combining point-wise features with a locally aggregated feature
- The convolutional middle layers aggregate voxel-wise features within a progressively expanding receptive field, adding more context to the shape description.介紹了卷積中間層的作用,是一種空間感受野增量式的學習過程,有利於學習高階語義特徵,比如說資料分佈結構等...
4. 參考文獻
1. Zhou Y, Tuzel O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection[J]. computer vision and pattern recognition, 2018.