
LeetCode #126 Word Ladder II
(第四周演算法部落格)
因為國慶假和調課,直到現在本人才把上一週的演算法部落格發出來。不過我在這道題上也走了不少彎路,只能說自己的思維確實還需要鍛鍊。
這篇部落格詳細地描述了我的思路過程,當是一個記錄,也希望它能提醒我以後進行更為全面高效的思考。
下面來看看題目:
題目
Given two words (beginWord and endWord), and a dictionary’s word list, find all shortest transformation sequence(s) from beginWord to endWord, such that:
- Only one letter can be changed at a time
- Each transformed word must exist in the word list. Note that beginWord is not a transformed word.
Note:
- Return an empty list if there is no such transformation sequence.
- All words have the same length.
- All words contain only lowercase alphabetic characters.
- You may assume no duplicates in the word list.
- You may assume beginWord and endWord are non-empty and are not the same.
Example 1:
Input:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]
Output:
[
["hit","hot","dot","dog","cog"],
["hit","hot","lot","log","cog"]
]
Example 2:
Input: beginWord = "hit" endWord = "cog" wordList = ["hot","dot","dog","lot","log"] Output: [] Explanation: The endWord "cog" is not in wordList, therefore no possible transformation.
分析
我們先定義如何檢測兩個字串是否只有一個不同處:
inline bool cmp(const string& s1, const string& s2){
int len = s1.length();
int diff = 0;
for(int i = 0; i < len; i++){
if(s1[i] != s2[i]) diff++;
}
return diff == 1;
}
構建兩端之間的最短路徑圖
因為要找 begin 與 end 之間的最短路徑,所以要用 BFS 演算法,即廣度優先搜尋演算法。
那麼,就可以把每個單詞視作一個節點,這個問題本質上是一個圖論問題。
為了方便,我們用 vector 的索引代表每個單詞。使用 vector<int> 表示 vertex ,即節點的前驅節點列表,vector<vertex>[i] 表示第 i 個節點的前驅節點列表。
由於要找所有最短路徑,且可能有多個節點通往 end ,所以在找到 end 之後,還不能停下來,要繼續找到其他在前一層的、同樣通往 end 的節點。
同理,對其他節點,可能有多個前驅節點,所以在進行 BFS 時,如果某一個節點有已經加入 BFS 搜尋隊列(即 distance 值已更改)的後繼節點,也要把該節點加入這個後繼節點的前驅節點列表。只有未加入 BFS 搜尋隊列的後繼節點,才需要加入 BFS 搜尋隊列、更新 distance 值。
typedef vector<int> vertex; // prev-list
class Solution{
private:
vector<vertex> buildGraph(bool& accessible, const int& begin, const int& end,
const int& size, const vector<string>& dictionary);
void findPaths(...); // 具體引數因演算法不同而有所改變,參見後面程式碼塊
public:
vector<vector<string>> Solution::findLadders(string beginWord, string endWord, vector<string>& wordList);
};
vector<vertex> Solution::buildGraph(bool& accessible, const int& begin, const int& end,
const int& size, const vector<string>& dictionary){
vector<vertex> vers; // saves prev-lists of vertexes
vers.assign(size, vertex());
int distance[size];
for(int i = 0; i < size; i++){
distance[i] = INT_MAX;
}
distance[begin] = 0;
queue<int> bfs;
bfs.push(begin);
int levelFlag = -1; // records the distance from the end to the begin
// builds a graph and makes bfs
while(!bfs.empty()){
int index = bfs.front();
bfs.pop();
if(distance[index] == levelFlag) break;
else if(cmp(dictionary[index], dictionary[end])){
vers[end].push_back(index);
// cout << "[" << dictionary[index] << " " << dictionary[end] << "]" << endl;
if(distance[end] > distance[index] + 1){ // end is found for the first time
levelFlag = distance[end] = distance[index] + 1;
bfs.push(end);
accessible = true;
}
continue;
}
for(int i = 0; i < size; i++){
if(i != index && cmp(dictionary[index], dictionary[i])){
if(distance[i] >= distance[index] + 1){ // index -> i
// cout << "[" << index << " " << dictionary[index] << " "
// << i << " " << dictionary[i] << "]" << endl;
vers[i].push_back(index);
}
if(distance[i] > distance[index] + 1){
distance[i] = distance[index] + 1;
bfs.push(i);
}
}
}
}
return vers;
}
記錄所有路徑
通過從 end 開始,使用前驅節點列表向前回溯,就不用考慮那些不在最短路徑上的節點。這樣,產生的路徑與期望路徑是相反的,我們需要在最後對每條路徑進行逆序操作。
舉個比較複雜的、可能的圖的例子:
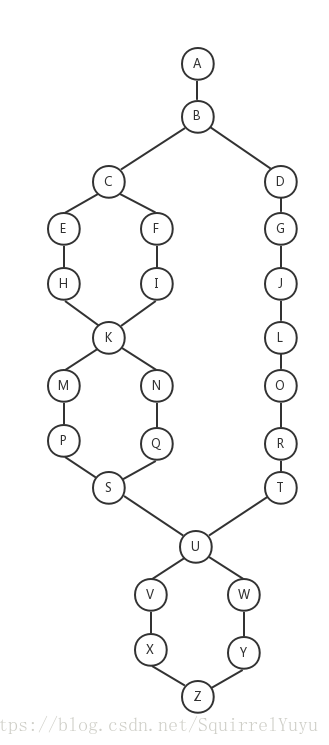
圖中存在環,需要考慮在遍歷時選擇分支和分支匯合的問題。
歧路:節點分裂
我曾經考慮過,把有多個入度(在這裡,如果 A 在 B 的前驅節點列表裡,則在從 end 開始的回溯過程中有從 B 指向 A 的邊,這會產生一個入度)的節點分裂出多個副本,以此得到沒有分支匯合的樹。在 end 和 begin 之間,將產生多條獨立而無交叉的路徑。
類似下圖:
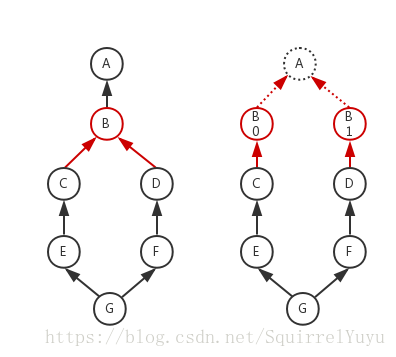
但其實這是歧路,難以實現。我們需要考慮到更復雜的情況,即有多個入度大於1的節點。
① 如下圖,若在進行 BFS 從 begin 走到 end 的過程中,對有多個後繼節點的節點進行分裂,那麼到了後面依舊會再現巢狀環的結構。
( A 為 begin ,H 為 end ,從 u 指向 v 的箭頭表示 u 的前驅節點列表中有 v ,u 是 BFS 過程中 v 的後繼節點,從 end 開始回溯時會從 u 走到 v 。)
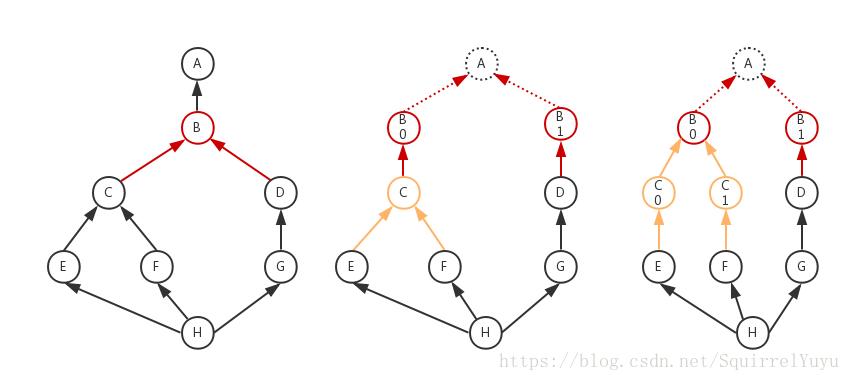
② 如果在進行從 end 回溯到 begin 的過程時,將遇到的入度大於1的節點分裂,保持每個節點只有一個入度。
這樣雖然可以消除巢狀環,但是就需要更復雜的資料結構,比如每個節點維持一個前驅節點列表和後繼節點列表。空間耗費比起①又會更大一些。
而且,進行節點分裂後一樣需要進行 DFS 遍歷,因為仍然存在分支,只是分支不會匯合了。
正途:不刪除邊的DFS演算法
老老實實地重新審視這些圖。
自己重新走一遍圖,可以發現遵循的仍是 DFS 演算法。但以前做對樹的 DFS 遍歷時,通常會選擇在出棧時把已訪問的節點從樹中刪除。然而對這個有分支匯合形成環的圖,不能把節點從圖中刪掉,因為可能之後還要再回來訪問。
那麼,就可能需要輔助的資料結構來記錄分支的訪問情況。
遞迴實現
利用遞迴的函式棧,來實現 DFS 訪問。只改變記錄路徑的 words ,不改變圖 graph。
void Solution::findPaths(const int& index, vector<vector<string>>& result, vector<string>& words,
const vector<vertex>& graph, const vector<string>& dictionary){
words.push_back(dictionary[index]);
const vertex& list = graph[index];
for(const int& v : list){
findPaths(v, result, words, graph, dictionary);
}
if(index == graph.size() - 1){ // index == begin
result.push_back(words);
}
words.pop_back();
}
vector<vector<string>> Solution::findLadders(string beginWord, string endWord, vector<string>& wordList){
// finds if endWord is in dictionary
int e = -1;
for(int i = 0; i < wordList.size(); i++){
if(wordList[i] == endWord){
e = i;
break;
}
}
if(e == -1) return vector<vector<string>>();
vector<string> dictionary = wordList;
dictionary.push_back(beginWord);
const int size = dictionary.size();
const int begin = size - 1;
const int end = e;
bool accessible = false; // presents if the end is accessible
// builds a graph by bfs
const vector<vertex> graph = buildGraph(accessible, begin, end, size, dictionary);
if(!accessible) return vector<vector<string>>();
// finds all the shortest paths by dfs
vector<vector<string>> result;
vector<string> words;
findPaths(end, result, words, graph, dictionary);
for(vector<string>& v : result){
reverse(v.begin(), v.end());
}
return result;
}
用時 。
整個演算法的時間複雜度為 , 指節點數, 指邊數。
迴圈&棧實現
遞迴的缺點是,呼叫函式時的棧操作比較耗時。現在嘗試使用迴圈來實現 DFS 演算法。
在迴圈中,不像遞迴那樣可以直接掃描前驅節點列表進入不同的分支。我們需要一個棧,來記錄在每個岔路口選擇的分支。
以下面這張圖為例,
有如下分支棧的變化:
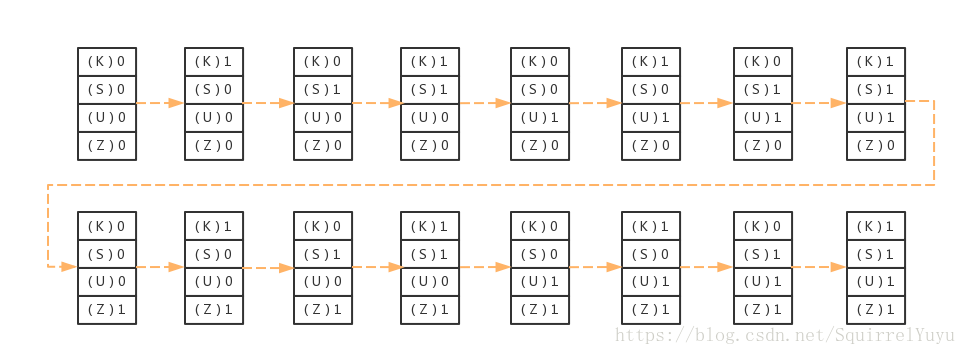
在以下演算法中,我們有兩個int 型別的棧 dfs 和 branch 。
dfs 棧記錄遍歷時遇到的節點,branch 棧記錄遇到岔路口(有多個前驅節點的節點)時,選擇的分支。
-
遍歷時,將
dfs棧頂節點的第一個前驅節點推入dfs棧,如果dfs棧頂節點有多個前驅節點,則將0推入branch棧,表示選擇第一個分支。一直入dfs棧直到begin入棧。 -
然後對
dfs進行出棧操作,期間如果遇到有多個前驅節點的節點,則將branch棧的棧頂與該節點的前驅節點個數比較,看是否已經走過了最後一個分支。如果是最後一個分支,那麼
branch出棧,dfs繼續出棧,直到遇到下一個有未遍歷的分支的岔路口。這個節點不出棧。 -
停止出棧操作,將
branch的棧頂自增,記結果為top。表示選擇dfs棧頂節點的第top+1個分支。將
dfs棧頂節點的第top+1個前驅節點推入dfs棧,如果該節點也有多個前驅節點,則將0推入branch棧。 -
重複以上過程,直到
dfs棧為空。
void Solution::findPaths(vector<vector<string>>& result, const int end,
const vector<vertex>& graph, const vector<string>& dictionary){
const int begin = graph.size() - 1;
vector<string> words;
stack<int> dfs;
stack<int> branch;
dfs.push(end);
// cout << "push " << end << " " << dictionary[end] << endl;
words.push_back(dictionary[end]);
if(graph[end].size() > 1){
branch.push(0);
// cout << "branch push 0" << endl;
}
while(1){
// push
while(dfs.top() != begin){
const int& prev = dfs.top();
const int& next = graph[prev][0];
dfs.push(next);
words.push_back(dictionary[next]);
// cout << "push " << next << " " << dictionary[next] << endl;
if(graph[next].size() > 1){
branch.push(0);
// cout << "branch push 0" << endl;
}
}
result.push_back(words);
// pop till meets a vertex with unchoosed branch
while(!dfs.empty()){
const int& prev = dfs.top();
if(graph[prev].size() > 1){
if(graph[prev].size() != branch.top() + 1){
break;
}
else{
// cout << "branch pop" << branch.top();
branch.pop();
}
}
// cout << " pop " << dfs.top() << " " << words.back() << endl;
dfs.pop();
words.pop_back();
}
if(dfs.empty()) break;
// cout << dfs.top() << endl;
// turn to another branch
int top = branch.top();
top++;
branch.pop();
branch.push(top);
// cout << branch.top() << " branch top" << endl;
const int& prev = dfs.top();
const int& next = graph[prev][top];
dfs.push(next);
words.push_back(dictionary[next]);
// cout << "push " << next << " " << dictionary[next] << endl;
if(graph[next].size() > 1) {
branch.push(0);
// cout << "branch push 0" << endl;
}
}
}
vector<vector<string>> Solution::findLadders(string beginWord, string endWord, vector<string>& wordList){
// finds if endWord is in dictionary
int e = -1;
for(int i = 0; i < wordList.size(); i++){
if(wordList[i] == endWord){
e = i;
break;
}
}
if(e == -1) return vector<vector<string>>();
vector<string> dictionary = wordList;
dictionary.push_back(beginWord);
const int size = dictionary.size();
const int begin = size - 1;
const int end = e;
bool accessible = false; // presents if the end is accessible
// builds a graph by bfs
const vector<vertex> graph = buildGraph(accessible, begin, end, size, dictionary);
if(!accessible) return vector<vector<string>>();
// finds all the shortest paths by dfs
vector<vector<string>> result;
vector<string> words;
findPaths(result, end, graph, dictionary);
for(vector<string>& v : result){
reverse(v.begin(), v.end());
}
return result;
}
用時 。
整個演算法的時間複雜度為 。
測試程式碼
現附上測試程式碼,方便後來人:
void print(vector<vector<string>> result){
for(vector<string>& v : result){
for(string& s : v){
cout << s << " ";
}
cout << endl;
}
cout << endl;
}
int main(){
string b1 = "hit", e1 = "cog";
vector<string> l1;
l1.push_back("hot"); l1.push_back("dot"); l1.push_back("dog");
l1.push_back("lot"); l1.push_back("log"); l1.push_back("cog");
string b2 = "hit", e2 = "cog";
vector<string> l2;
l2.push_back("hot"); l2.push_back("dot"); l2.push_back("dog");
l2.push_back("lot"); l2.push_back("log");
string b3 = "red", e3 = "tax";
vector<string> l3;
l3.push_back("ted"); l3.push_back("tex"); l3.push_back("red");
l3.push_back("tax"); l3.push_back