
機器學習筆記(四)PCA主成分分析
首先先複習一下要用到的基礎的知識:
(一)、協方差和方差
樣本均值:
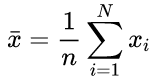
樣本方差:
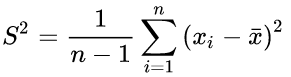
樣本X和樣本Y的協方差:
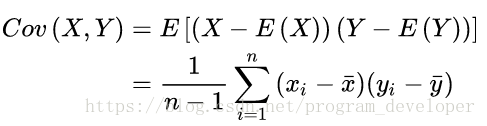
協方差代表了兩個變數之間的相關關係,協方差為正時,說明X和Y是正相關關係;協方差為負時,說明X和Y是負相關關係;協方差為0時,說明X和Y是相互獨立。Cov(X,X)就是X的方差。當樣本是n維資料時,它們的協方差實際上是協方差矩陣(對稱方陣)。例如,對於3維資料(x,y,z),計算它的協方差就是:
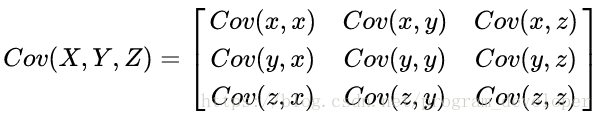
(二)、特徵值與特徵向量
如果向量v與變換A滿足Ax=λx,則稱向量x是變換A的一個特徵向量,λ是相應的特徵值。
描述正方形矩陣的特徵值的重要工具是特徵多項式,λ是A的特徵值等價於線性方程組(A – λI) x = 0 (其中I是單位矩陣)有非
函式p(λ) = det(A – λI)是λ的多項式,因為行列式定義為一些乘積的和,這就是A的特徵多項式。矩陣的特徵值也就是其特徵多項式的零點。一個矩陣A的特徵值可以通過求解方程pA(λ) = 0來得到。 若A是一個n×n矩陣,則pA為n次多項式,因而A最多有n個特徵值,包括虛數。但是如果是是對稱矩陣的話他的特徵值都是實數。Ax表示對向量x的旋轉拉伸。如果Ax和x的方向一樣,只是長度不一樣,說明x是A的特徵向量,拉伸倍數為λ。例如下圖,x3是A的特徵向量。
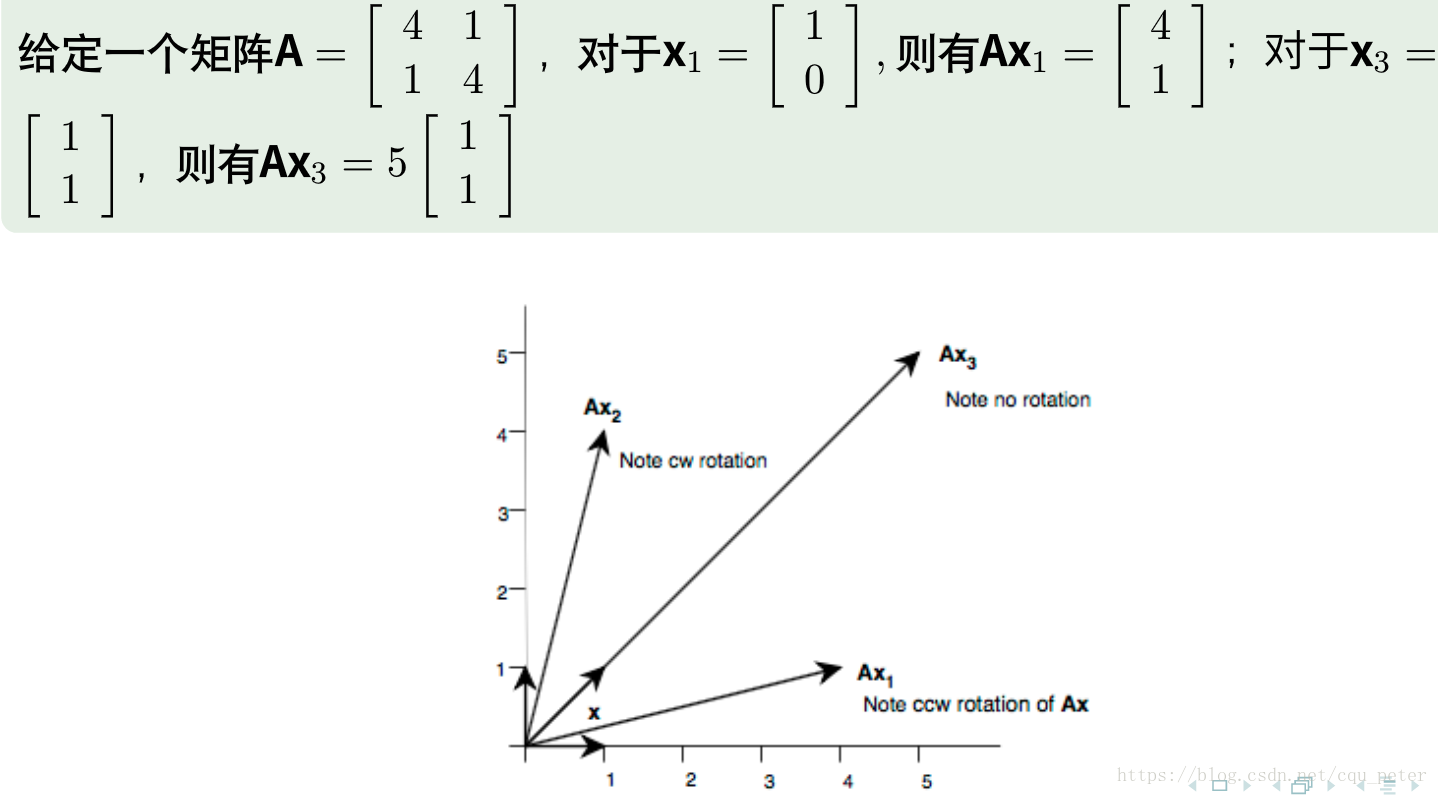
如果  有n個線性無關的特徵向量
有n個線性無關的特徵向量  ,與它們對應的特徵值是
,與它們對應的特徵值是  ,以
,以
 對角元素的分別是,可以得到
對角元素的分別是,可以得到 


(三)、PCA演算法的數學原理。
先看下面這幅圖:
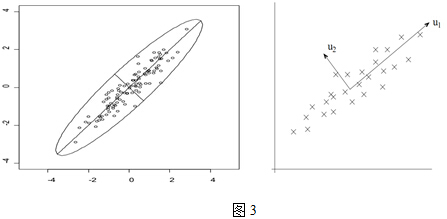
先假定只有二維,即只有兩個變數,它們由橫座標和縱座標所代表;因此每個觀測值都有相應於這兩個座標軸的兩個座標值;如果這些資料形成一個橢圓形狀的點陣,那麼這個橢圓有一個長軸和一個短軸。在短軸方向上,資料變化很少;在極端的情況,短軸如果退化成一點,那只有在長軸的方向才能夠解釋這些點的變化了;這樣,由二維到一維的降維就自然完成了。上圖中,u1就是主成分方向,然後在二維空間中取和u1方向正交的方向,就是u2的方向。則n個數據在u1軸的離散程度最大(方差最大),資料在u1上的投影代表了原始資料的絕大部分資訊,即使不考慮u2,資訊損失也不多。而且,u1、u2不相關。只考慮u1時,二維降為一維。
對給定的一組資料(下面的闡述中,向量一般均指列向量):
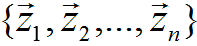
其資料中心位於:
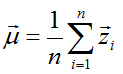
資料中心化(將座標原點移到樣本點的中心點):
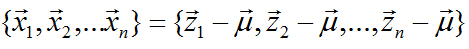
中心化後的資料在第一主軸u1方向上分佈散的最開,也就是說在u1方向上的投影的絕對值之和最大(也可以說方差最大),計算投影的方法上面已經闡述,就是將x與u1做內積,由於只需要求u1的方向,所以設u1也是單位向量。
在這裡,也就是最大化下式:
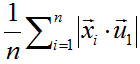
由矩陣代數相關知識可知,可以對絕對值符號項進行平方處理,比較方便。所以進而就是最大化下式:
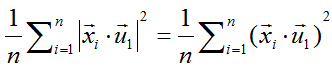
兩個向量做內積,可以轉化成矩陣乘法:
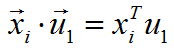
所以目標函式可以表示為:
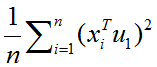
括號裡面就是矩陣乘法表示向量內積,由於列向量轉置以後是行向量,行向量乘以列向量得到一個數,一個數的轉置還是其本身,所以又可以將目標函式化為:
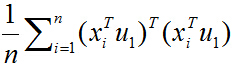
去括號:
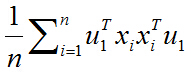
又由於u1和i無關,可以拿到求和符外面,上式化簡為:
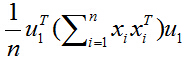
學過矩陣代數的同學可能已經發現了,上式括號裡面求和後的結果,就相當於一個大矩陣乘以自身的轉置,其中,這個大矩陣的形式如下:
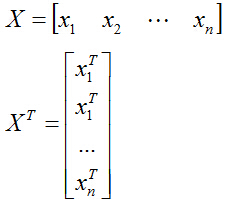
X矩陣的第i列就是xi
於是有:
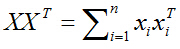
所以目標函式最終化為:
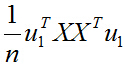
其中的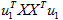
我們假設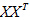
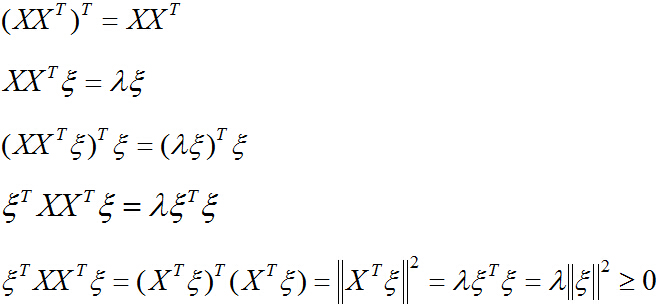
所以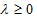
由於我們做過均值化處理,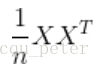
max

subject 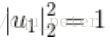
lagrange 函式為:
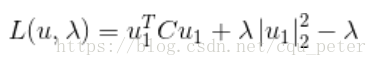
對u求導可得


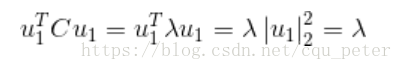
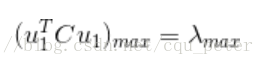
因此u1就是C的最大特徵值對應的特徵向量。
總結一下PCA的演算法步驟:
設有m條n維資料。
1)將原始資料按列組成n行m列矩陣X
2)將X的每一行(代表一個屬性欄位)進行零均值化,即減去這一行的均值
3)求出協方差矩陣C=1mXXTC=1mXXT
4)求出協方差矩陣的特徵值及對應的特徵向量
5)將特徵向量按對應特徵值大小從上到下按行排列成矩陣,取前k行組成矩陣P
6)Y=PXY=PX即為降維到k維後的資料
宣告:參考了大量文章並加入自己的理解,非完全原創