
用nvidia-docker跑深度學習模型.md
用nvidia-docker跑深度學習模型
##背景
最近實驗室要參加一個目標檢測的比賽,這段時間一直在跑ssd模型,最開始根據作者給的文件成功編譯後,可以在VOC資料集上進行訓練。由於要用比賽官方的資料集,因此做了幾天的資料集,然後拿自己的資料集訓練的時候,出現了以下報錯:Check failed: a <= b (0 vs. -1.192093-07)
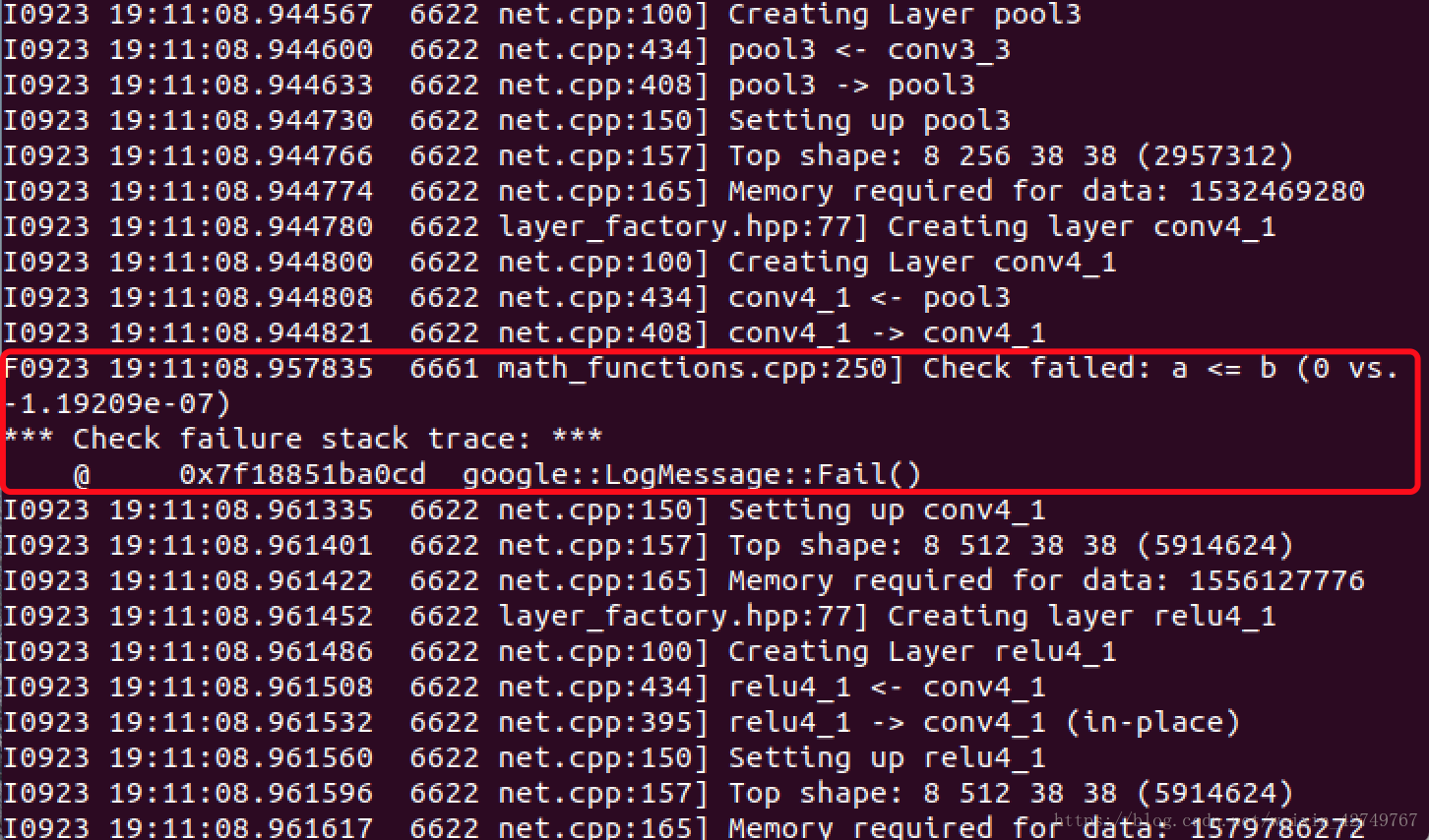
去網上搜了相關的解決方法,全都是說把math_functions.cpp第250行註釋掉,重新編譯,這種方案一看就不靠譜,而且也沒人說個所以然,但是還是抱著試一試的心態照做了,果然又出現了新的bug。查了幾天的資料也沒找到解決方案,一開始我懷疑可能是我的資料集做的有問題,然後我又重新在VOC資料集上訓練,結果會出現同樣的問題,聯想到前兩天實驗室伺服器重灌了系統,然後cuda從8.0換到了9.1版本,會不會是這個原因導致了現在的報錯呢?但是因為實驗室伺服器是大家共用的,把cuda改回到8.0版本可能給其他人帶來困擾,剛好實驗室有其他同學在搞nvidia docker,乾脆直接用nvidia docker來跑模型,就不用考慮環境問題了。
##什麼是nvidia docker
介紹nvidia docker之前,首先要了解什麼是docker。
Docker 是一個開源的應用容器引擎,基於 GO語言並遵從Apache2.0協議開源。
Docker 可以讓開發者打包他們的應用以及依賴包到一個輕量級、可移植的容器中,然後釋出到任何流行的 Linux 機器上,可以實現虛擬化。
Docker所代表的容器虛擬化技術屬於作業系統級虛擬化:核心通過建立多個虛擬的作業系統例項(核心和庫)來隔離不同的程序。並且傳統虛擬化技術是在硬體層面實現虛擬化,增加了系統呼叫鏈路的環節,有效能損耗;容器虛擬化技術以共享Kernel的方式實現,幾乎沒有效能損耗。
這裡可以將容器理解為一種沙盒。每個容器內執行一個應用,不同的容器相互隔離,容器之間可以建立通訊機制。容器的建立和停止都十分快速(秒級),容器自身對資源的需求十分有限,遠比虛擬機器本身佔用的資源少。
docker一般服務於基於cpu 的應用,而我們的深度學習模型是跑在gpu上面的,因此需要用nvidia docker。nvidia docker的執行需要基於一定的硬體環境,需要安裝nvidia driver,docker容器本身並不支援nvidia gpu。最開始的解決方法是在容器內部安裝nvidia driver,然後通過設定相應的裝置引數來啟動container,但是這樣做帶來一個弊端就是可能導致image無法共享,因為宿主機的driver的版本必須完全匹配容器內的driver版本,很可能本地機器的不一致導致每臺機器都需要去重複操作,這很大的違背了docker的初衷。nvidia docker實際上是一個docker plugin,它在docker上做了一層封裝,對docker進行呼叫,類似一個守護程序,發現宿主機驅動檔案以及gpu 裝置,並且將這些掛載到來自docker守護程序的請求中,以此來支援docker gpu的使用。
安裝docker
- GPU driver安裝
nvidia官網下載安裝對應型號的顯示卡驅動:連結 如果安裝成功,在終端中輸入 lspci | grep -i nvidia ,會顯示自己的NVIDIA GPU版本資訊
- CUDA安裝
實驗室伺服器是ubuntu 18.04版本,可以直接sudo apt install nvidia-cuda-toolkit安裝
-
docker安裝
-
安裝必要的一些系統工具
sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common -
安裝GPG證書
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add - -
寫入軟體源資訊
sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" -
更新並安裝 docker-ce
sudo apt-get -y update sudo apt-get -y install docker-ce -
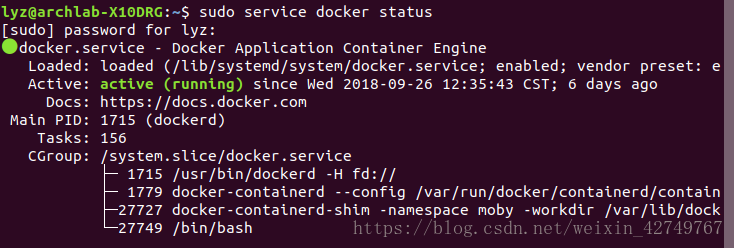
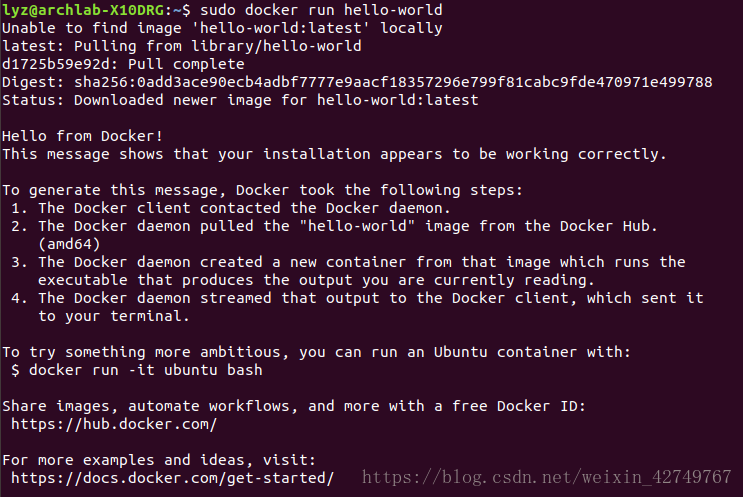
驗證
sudo service docker status #或者sudo systemctl status service.docker 檢查Docker服務的狀態 sudo docker run hello-world #測試Docker安裝是否成功
-
nvidia-docker安裝
- 如果之前安裝過docker1.0版本,需要先刪掉該版本和之前建立的容器
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f sudo apt-get purge -y nvidia-docker- 新增程式碼倉庫
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \ sudo apt-key add - distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \ sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update- 安裝docker 2
sudo apt-get install -y nvidia-docker2 sudo pkill -SIGHUP dockerd- 測試
docker run --runtime=nvidia --rm nvidia/cuda:9.0-base nvidia-smi -
安裝過程中遇到的問題
網上有的教程會設定阿里雲加速器,是因為官方Docker Hub網路速度較慢,所以使用阿里雲提供的Docker Hub,然後需要配置阿里雲加速器。具體步驟如下:
sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-‘EOF’ { “registry-mirrors”: [“https://fird1mfg.mirror.aliyuncs.com“] } EOF sudo systemctl daemon-reload sudo systemctl restart docker結果我在重啟docker服務的時候,產生了如下報錯:
docker.service - LSB: Create lightweight, portable, self-sufficient containers Loaded: loaded (/etc/init.d/docker; generated) Active: failed (Result: exit-code) since Wed 2018-09-26 10:11:16 CST; 28s ago Docs: man:systemd-sysv-generator(8) Process: 18639 ExecStart=/etc/init.d/docker start (code=exited, status=1/FAILULURE) Main PID: 15621 (code=exited, status=1/FAILURE) 9月 26 10:11:16 archlab-X10DRG systemd[1]: Starting LSB: Create lightweight, portable, self-sufficient containers.... 9月 26 10:11:16 archlab-X10DRG docker[18639]: * /usr/bin/dockerd not present or not executable 9月 26 10:11:16 archlab-X10DRG systemd[1]: docker.service: Control process exited, code=exited status=1 9月 26 10:11:16 archlab-X10DRG systemd[1]: docker.service: Failed with result 'exit-code'. 9月 26 10:11:16 archlab-X10DRG systemd[1]: Failed to start LSB: Create lightweight, portable, self-sufficient containers根絕報錯的第二行,發現是dockerd除了問題,dockerd是docker的守護程序,現在提示不存在或不可用,然後我執行了
sudo dockerd,打印出了以下報錯資訊unable to configure the Docker daemon with file /etc/docker/daemon.json: invalid character ‘h’ after object key
這說明docker的配置檔案除了問題,開啟daemon.json檔案,果然發現剛才設定阿里雲加速器的時候,寫入的語句有問題,應該是我直接複製貼上導致的問題,改正之後docker服務可以正常啟動了。
-
##用nvidia docker進行訓練
待續