
dplyr:六個基本資料處理技法
摘要
本文簡介如何使用 dplyr 與 base R 語法進行六個基本資料處理技法,並支援初學者先從 dplyr 開始做基本資料處理技法這個論點。
論點起源
在 Tidyverse:R 語言學習之旅的新起點一文中我們提到過新興的 R 語言學習路徑可以從 tidyverse 這個套件起始,而非傳統的 Base R;這個論點其實源自於 DataCamp 現任的首席資料科學家 David Robinson,他的前一份工作是在 Stack Overflow 擔任資料科學家。
不過 tidyverse 是一個非常龐大的生態系,它有點像是懶人包,將未來可能
試試水溫
對於初學者,可以在安裝 tidyverse 之前,先嘗試看看 dplyr 這個 tidyverse 的敲門磚;假如 ggplot2 被譽為繪圖的文法(grammar of graphics),那麼 dplyr 就是資料處理的文法(grammar of data manipulation),如果喜歡,就可以接著走新興路徑,接著試 ggplot2;假如不喜歡,就改走 Base R 的傳統路徑。
那又該怎麼判斷自己是否會喜歡 dplyr 呢?在本篇文章中,我們會簡介 dplyr 的六個基本資料處理技法:篩選、選擇、新增、排序、摘要與分組,同時互動參照使用 base R 的寫法該怎麼實踐,初學者應當能夠在執行過後得到一個較喜歡的做法,又或者直接採納本文的觀點。
前置作業
需要安裝載入 dplyr,然後手動建立一個資料框 strawhat。
install.packages("dplyr") library(dplyr) strawhat <- data.frame( name = c("Monkey D. Luffy", "Roronoa Zoro", "Nami", "Usopp", "Vinsmoke Sanji", "Tony Tony Chopper", "Nico Robin", "Franky", "Brook"), gender = c("Male", "Male", "Female", "Male", "Male", "Male", "Female", "Male", "Male"), age = c(19, 21, 20, 19, 21, 17, 30, 36, 90), height = c(174, 181, 170, 176, 180, 90, 188, 240, 277), stringsAsFactors = FALSE ) View(strawhat)


One Piece, Google Search
篩選女性船員
dplyr 使用 filter 函式、base R 使用原生中括號。
# dplyr::filter() ---------
strawhat %>%
filter(gender == "Female")
# base R ------------------
strawhat[strawhat$gender == "Female", ]
選擇姓名與年紀
dplyr 使用 select 函式、base R 使用原生中括號。
# dplyr::select() ---------
strawhat %>%
select(name, age)
# base R ------------------
strawhat[, c("name", "age")]
新增兩年前的年紀
dplyr 使用 mutate 函式、base R 直接將衍生變數的算式指派給新變數。
# dplyr::mutate() ---------
strawhat %>%
mutate(age_before = age - 2)
# base R ------------------
strawhat$age_before <- strawhat$age - 2
strawhat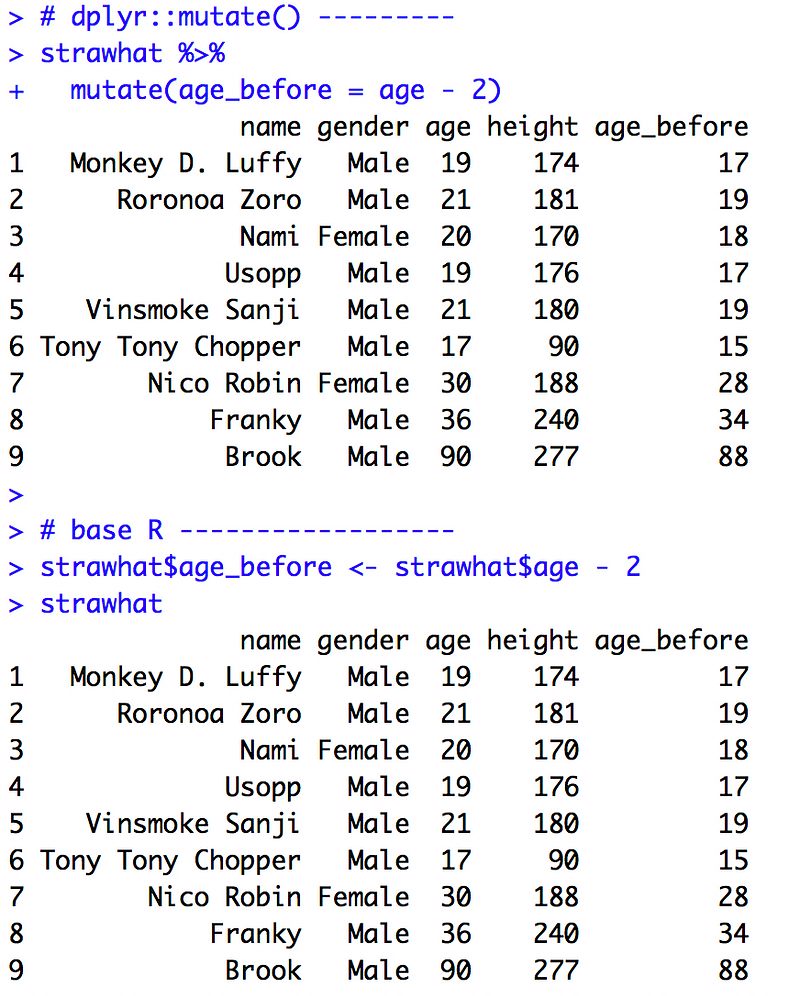
以身高遞減排序
dplyr 使用 arrange 函式、base R 則以 order 函式取得觀測值順序後以原生中括號擺放位置。
# dplyr::arrange() --------
strawhat %>%
arrange(desc(height))
# base R ------------------
strawhat[rev(order(strawhat$height)), ]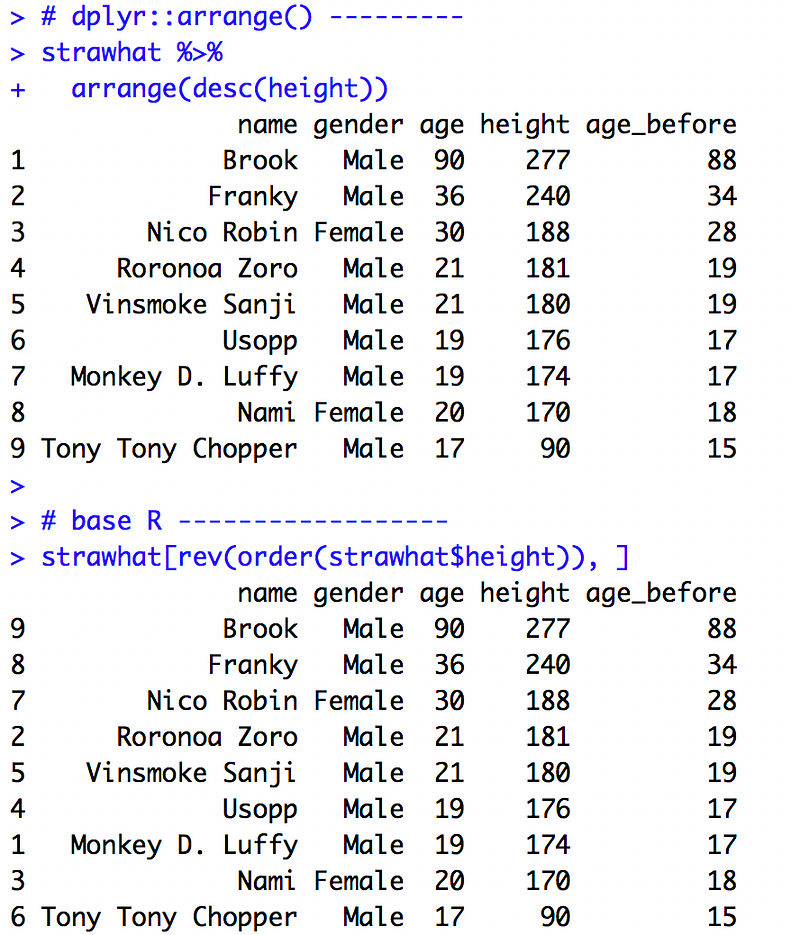
摘要平均年齡
dplyr 使用 summarise 函式、base R 直接對變數計算。
# dplyr::summarise() ------
strawhat %>%
summarise(avg_age = mean(age))
# base R ------------------
avg_age <- mean(strawhat$age)
avg_age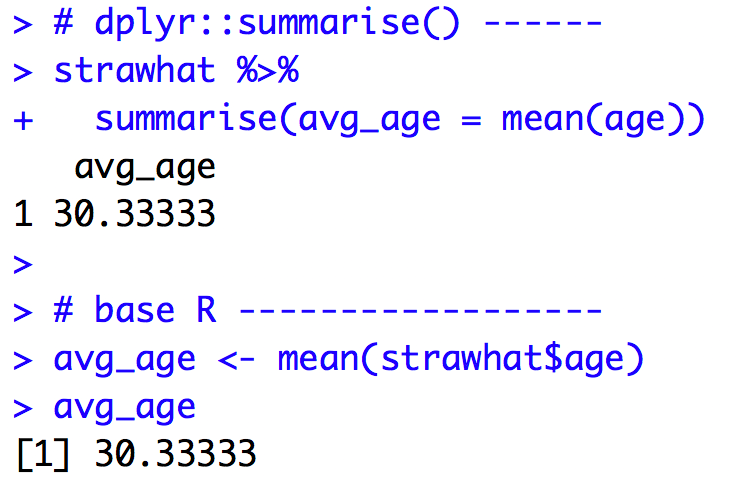
分性別摘要平均年齡
dplyr 使用 group_by 函式、base R 則使用 aggregate 函式。
# dplyr::group_by() -------
strawhat %>%
group_by(gender) %>%
summarise(avg_age = mean(age))
# base R ------------------
aggregate(strawhat$age, by = list(strawhat$gender), FUN = mean)
本文觀點
快速操作過 dplyr 與 Base R 語法後,不知道讀者是否已經心裡有譜?若還是拿不定主意,本文觀點是篩選、選擇、新增與摘要這四個技法上,dplyr 與 base R 算得上無差異,但是在排序及分組上,dplyr 的好用與直觀程度都勝過 base R,總結來說,我們支援初學者從 dplyr 做基本資料處理技法開始。