
大資料筆記-基於mapreduce的並行演算法
阿新 • • 發佈:2018-12-13
7.1 mapreduce


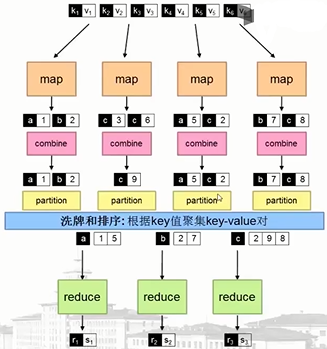
mapreduce程式設計:


同步工具:

實現時需要注意的地方:

本地聚合的重要性:

字數統計:

map進化1:引入陣列H(仍然需要combiner)

map進化2:把陣列H變為全域性變數,map結束後再將H輸出

(in-mapper的實現)本地聚合的設計模式:
將combiner的功能整合到mapper中(速度更快,in-mapper是記憶體上的操作->需要記憶體管理)

計算平均數:
combiner的設計:

example:
map version1:(此時reducer不能代替combiner)

version 2:(存在的問題:mapper的輸出不是reducer的輸入->影響了程式的正確性)

version 3:正確版本

in-mapper版本:(此時不需要combiner,可以減少通訊量)

單詞共現矩陣的計算:



方法1:詞對法

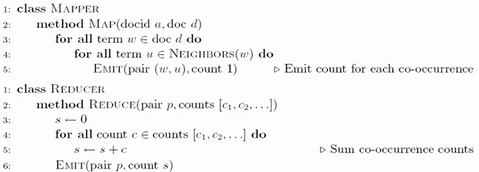
存在的問題:

估計相對頻率:


同步的實現:將同步變成一個排序問題

方法2:條紋法


存在的問題:

估計相對頻率:

同步的實現:構造資料結構使部分結果聚集到一起

再現概括總結:同步工具

tradeoff:
