
大資料筆記05--MapReduce
阿新 • • 發佈:2018-12-15
什麼是MapReduce
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner. MapReduce是一個軟體框架,用於簡單地書寫並行處理海量資料(數TB的資料)的應用,在標準伺服器搭建的大型的叢集(數千個節點)上,以一種可靠的,容錯的方式。
MR的主要思想
MR主要思想:分久必合
MapReduce是由兩個階段組成: Map端 Reduce端
MR核心思想:“相同”的key為一組,呼叫一次reduce方法,方法內迭代這一組資料進行計算
MR分散式計算原理
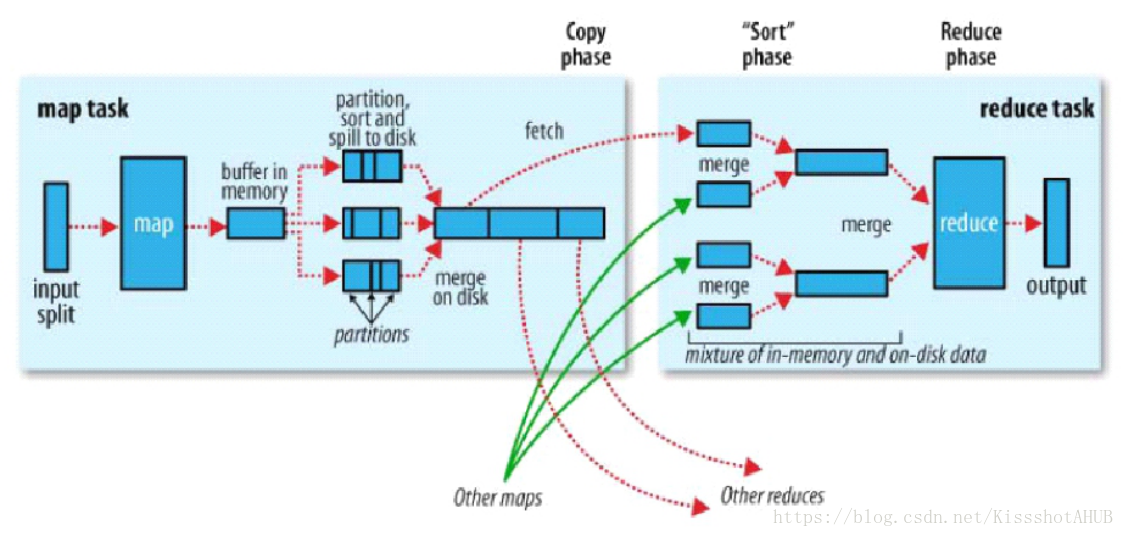
處理流程
map task
- 假設需要處理的檔案存在HDFS中(以block的形式)
- 檔案以split切片的形式輸入進map函式進行處理 split預設和block同樣大小,是一種邏輯上的儲存結構。實際在劃分時,一條資料可能被切分在兩個block中,split會將這條資料在下一個block中的部分抽取出來補充完整,所以實際的split大小可能略大或略小於block。
- map一條一條的讀取資料(以(偏移量,值)KV對的形式)偏移量,即索引號,從0開始,若第一條資料所佔位元組數N,則下一行的偏移量即key從N+1開始,以此類推
- map將處理後的結果輸出到memory的buffer中(自定義的key,處理後的value),並在輸出時為每一條記錄打上標籤,即分割槽號 目的:為了讓這條資料知道將來被哪一個reduce處理 分割槽是由分割槽器進行的,預設的分割槽器是HashPartitioner 分割槽的策略:根據key的hashcode與reduce的個數取模,根據取模結果分組
- 資料一條一條的寫入buffer,一旦寫入到80M,就會將資料溢寫到磁碟上 到80M時,記憶體會將這80M封鎖,對記憶體中的資料進行combiner(小聚合),並根據分割槽號、key進行排序,寫到磁碟上的是一個檔案內分好區,區內有序的小檔案。 封鎖記憶體時由剩餘的20M記憶體繼續接收map的輸出 每一次溢寫會產生一個小檔案
- map task全部計算完畢後,會將磁碟上的小檔案合併為一個大檔案 合併的時候會進行combiner,並採用歸併排序的演算法,將眾多小檔案合成一個內部分割槽且分割槽內有序的大檔案
reduce task
- reduce task從map端讀取對應分割槽的資料,寫入到記憶體中,記憶體寫滿就溢寫到磁碟上 寫策略與map端相同,預設情況下記憶體為660M,封鎖後可用記憶體為40M 。溢寫前也會進行排序,當把所有的資料取過來後,會將溢寫產生的小檔案歸併排序併合並。
- 每一組資料(key相同)呼叫一次reduce函式計算產生結果
總結
- 共執行兩次combiner,四次排序,目的都是為了最後提高分組的效率
- 資料從Map出到進入Reduce的過程稱為Shuffle Shuffle內包含combiner(小聚合)、spill(溢寫)、merge(合併)
- 在map task的階段稱為shuffle write,在reduce task的階段稱為shuffle read 即Map ==> Shuffle write | | Shuffle read ==> Reduce