
資料庫查詢優化技術(一):資料庫與關係代數
資料庫查詢優化技術 學習筆記(一)
我是看李海翔的《資料庫技術叢書·資料庫查詢優化器的藝術:原理解析與SQL效能優化》這本書的視訊講解學習的,因為資料庫的知識學的不多,直接看優化有些吃力,慢慢補吧。現在要用一些優化的知識只能先看著了。
本文大概內容:
1.1 What is the Database Management System ?
1.2 What is the Relation Database Management System?
1.3 Why do we need to learn MySQL/PostgreSQL ?
3 What is the technology Of Query Optimization ?
4 How to learn and master it ?
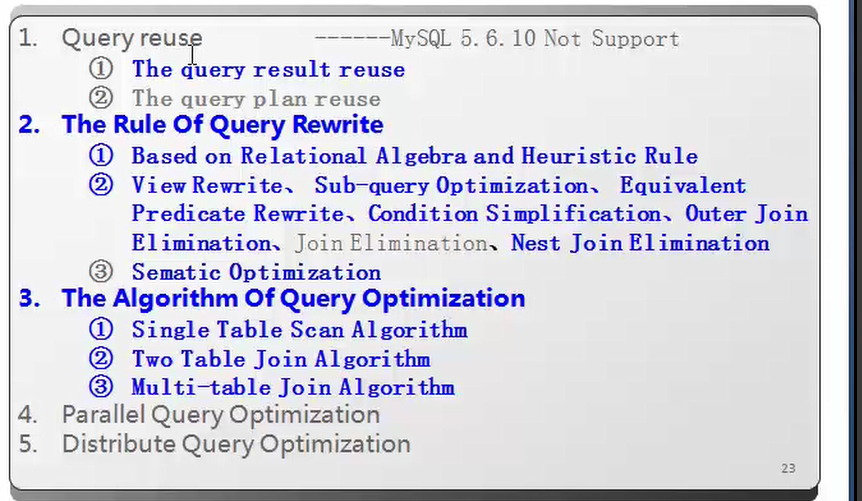
5.3Query Optimization Algorithm
5.4Parallel query optimization
5.5Distributrd Query Optimization
(。。英文是為了強行記憶這些單詞。。)
1.1 What is the Database Management System ?
資料庫管理系統(Database Management System):
1是一種操縱和管理資料的大型軟體,用於建立、使用和維護資料,簡稱DBMS。
2它對資料進行統一的管理和控制,以保證資料的安全性和完整性。
3使用者通過DBMS訪問資料庫中的資料,資料庫管理員也通過DBMS進行資料庫的維護工作。
4它可使多個應用程式和使用者用不同的方法在同時或不同時刻去建立,修改和詢問資料。
5DBMS提供資料定義語言DDL(Data Definition Language)和資料庫操作語言DML(Data Manipulation Language),供使用者定義資料庫的模式結構與許可權約束,實現對資料的追加、刪除等操作。
只要做資料處理,軟體規模達到一定程度,似乎都稱為資料庫。
衡量是否是資料庫的標準:
ACID,是指在資料庫管理系統(DBMS)中事務所具有的四個特性:
1)原子性(Atomicity)
2)一致性(Consistency)
3)隔離性(Isolation)
4)永續性(Durability)
1.2 What is the Relation Database Management System?
歷史上的幾種型別的資料庫
1層次性
2網狀型
3關係型
關係資料庫,是建立在關係資料庫模型基礎上的資料庫,藉助於關係代數等概念和方法來處理資料庫中的資料,同時也是一個被組織成一組擁有正式描述性的表格,該形式的表格作用的實質是裝載著資料項的特殊收集體,這些表格中的資料能以許多不同的方式被存取或重新召集而不需要重新組織資料庫表格。
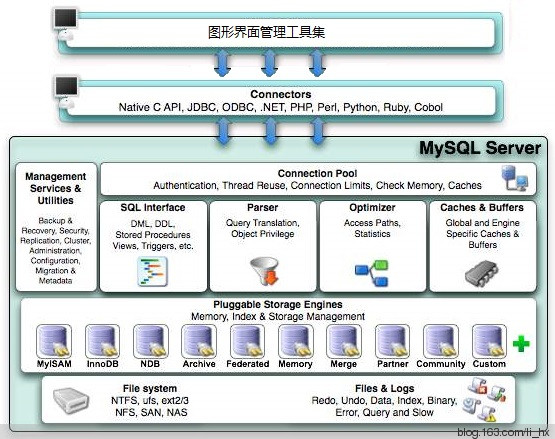
1.3 Why do we need to learn MySQL/PostgreSQL ?
趨勢1:雲端計算,淘汰大部分的運維人員
趨勢2:雲資料庫,淘汰大部分以商業資料庫為職業的DBA
趨勢3:電商等興起,對開源資料庫技術的人員需求增多
...
1.4 Why do we need to master Query Optimization Technology ?
資料庫查詢優化技術一直是DBMS實現技術中的精華,也是重點和難點。
...
2 What is the relational algebra ?
資料庫中,關係代數是一階邏輯的分支,是閉合於運算下的關係的集合。運算作用於一個或多個關係上來生成一個關係。關係代數是電腦科學的一部分。
在純數學中的關係代數是有關於數理邏輯和集合論的代數結構。
SQL的查詢語言鬆散的基於了關係代數,儘管SQL中的運算元(表)不完全是關係,很多有用的關係代數的理論在SQL對應者中不成立。

sql-01
關係代數是一種抽象的查詢語言,用對關係的運算來表達查詢,作為研究關係資料語言的數學工具。
關係代數的運算物件是關係,運算結果亦為關係。關係代數用到的運算子包括四類:
1)集合運算子
2)專門的關係運算符
3)算數比較符
4)邏輯運算子
比較運算子和邏輯運算子是用來輔助專門的關係運算符進行操作的,所以按照運算子不同,主要將關係代數分為傳統的集合運算和專門的關係運算兩類。
3 What is the technology Of Query Optimization ?
4 How to learn and master it ?
資料庫調優/Database Tuning
資料庫調優可以使資料庫應用執行得更快,其目標是:
使資料庫有更高的吞吐量,更短的響應時間,被調優的物件是整個資料庫管理系統總體。
查詢語句調優:被調優的物件是一條查詢語句。
資料庫調優的方式通常有如下幾種方式:
1)人工調優,主要依賴於人,效率低下;要求操作者完全理解常識所依賴的原理,還需要對應用、資料庫管理系統、作業系統以及硬體有廣泛而深刻的理解。最體現維護人員的價值。
2)基於案例的調優,總結典型應用案例情況中資料庫引數的推薦配置、資料邏輯層設計等情況,從而為使用者的調優工作提供一定的參考和借鑑。但這種方法忽略了系統的動態性和不同的系統間存在的差異。
3)自調優,為資料庫系統建立一個模型,根據“影響資料庫系統性能效率的因素”,資料庫系統自動進行引數的配置。一些商業資料庫,實現了部分自調優技術。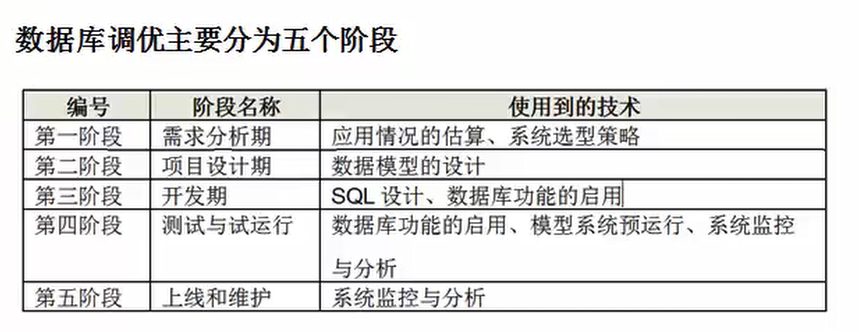
資料庫調優五個階段的主要技術
1應用情況的估算。
應用的使用方式(把業務邏輯轉換為資料庫的讀寫分佈邏輯,以是讀多寫少還是讀寫均衡等來區分OLTP和OLAP;應用對資料庫的併發情況、併發是否可以池化等)、資料量、對資料庫的壓力、峰值壓力等做一個預估。
2系統選項策略
確定什麼樣的資料庫可以適用應用需求,並確定資料庫是使用開源的還是商業的,是集使用群還是單機系統,同時對作業系統、中介軟體、硬體、網路等進行選型。
3資料模型的設計
主要是根據業務邏輯,從幾個角度考慮表的邏輯結構,如下:
3.1 E-R模型設計:遵循了E-R模型設計原理。偶爾的適當程度的非規範化可以改善系統查詢效能。
3.2 資料邏輯分佈策略:目的是減少資料請求的不必要的資料量,把使用者需要的資料返回;可用的技術如分割槽、用E-R模型分表等(如網際網路企業典型的用法,根據業務不同,進行分庫,分表等操作)。
3.3資料物理儲存策略:目的是減少IO,如啟用壓縮技術、把索引和表資料的儲存分開,不同的表資料分佈於不同的表空間,不同的表空間分佈在不同的物理儲存上(尤其是讀寫量大的表空間分佈在不同的物理儲存上)、日誌、索引和資料分佈在不同的物理儲存上等。
3.4索引:在查詢頻繁的物件上建立合適的索引,使索引的正效應大於負效應(索引的維護存在消耗)。
4SQL設計
編寫正確的、查詢效率高的SQL語句。這依據的主要是“查詢重寫規則”,編寫語句的過程中要注意,要有意識地保障SQL能利用到索引。
5資料庫功能的啟用
資料庫為提高效能提供了一些功能,可合理使用,具體如下:
5.1查詢重用:根據實際情況進項配置,可快取查詢執行計劃、查詢結果等。
5.2資料庫引數的設定:可設定系統上模擬實際執行環境,加大壓力進行系統測試,提前發現問題。
6系統監控與分析。在工業環境下,加強對系統的執行監控和日常的分析工作,具體如下:
6.1應用系統表現:收集使用者對應用系統的使用意見、系統存在問題等,因為這些可能是使用者在第一時間發現的。
6.2OS環境監控:實時監控CPU、記憶體、IO等,並對比實時情況與歷史正常情況。
6.3據庫內部裝況監控:一些資料庫提供系統表、檢視、工具等手段,向用戶提供資料庫執行過程中內部狀況的資訊,如鎖的情況,這些都需要實時監控,並對比實時情況與歷史正常情況。
6.4日誌分析:在資料庫的日誌、作業系統的日誌中找出異常事件,定位問題。
(二)
1.1 Query Reuse
查詢重用是指儘可能利用先前的執行結果,以達到節約查詢計算全過程的時間並減少資源消耗的目的。
目前查詢重用技術主要集中在兩個方面:
1查詢結果的重用。在快取區中分配一塊緩衝塊,存放該SQL語句文字和最後的結果集,當同樣的SQL輸入時,直接把結果返回。查詢結果的重用技術節約了查詢計劃生成時間,減少了查詢執行全過程的資源消耗。
2查詢計劃的重用。快取一條查詢語句的執行計劃及其相應語法樹結構。查詢計劃的重用技術減少了查詢計劃生成的時間和資源消耗。
查詢重用技術利弊:
1弊端:結果集很大會消耗很大的記憶體資源,同樣的SQL不同使用者應該獲取的結果集可能不同
2利端:節約了CPU和IO消耗。在實際使用的過程中,趨利避害,根據實際情況選用
1.2 Query Rewrite
查詢重寫:
是查詢語句的一種等價轉換,即對於任何相關模式的任意狀態都會產生相同的結果。
查詢重寫的兩個目標:
1將查轉換為等價的效率更高的形式,例如將效率低的謂詞轉換為效率高的謂詞、消除重複條件等。
2儘量將查詢重寫為等價、簡單且不受表順序限制的形式,為物理查詢優化階段提供更多的選擇,如檢視的重寫、子查詢的合併轉換等。
查詢重寫的依據:查詢重寫的依據,是關係代數。
1關係代數的等價變換規則對查詢重寫提供了理論上的支援。
2查詢重寫後,查詢優化器可能生成多個連線路徑,可以從候選者中擇優。
查詢優化技術型別:
1語法級:查詢語言層的優化,基於語法進行優化。
2代數級:查詢使用形式邏輯進行優化,運用關係代數的原理進行優化。
3語義級:根據完整性約束,對查詢語句進行語義理解,推知一些可優化的操作。
4物理級:物理優化技術,基於代價估算模型,比較得出各種執行方式中代價最小的。
查詢重寫是基於語法級、代數級、語義級的優化,可以統一歸屬到邏輯優化的範疇;基於代價估算模型是物理層面的優化,是從連線路徑中選擇代價最小的路徑的過程。
查詢重寫思路:
1將過程性查詢轉換為描述性的查詢,如檢視重寫。
2將複雜的查詢(如巢狀子查詢、外連線消除、巢狀連線消除)儘可能轉換為多表連線查詢
3將效率低的謂詞轉換為等價的效率高的謂詞(如等價謂詞重寫)。
4利用等式和不等式的性質,簡化WHERE、HAVING條件。
5如何改進現有查詢重寫規則的效率,如何發現更多更有效的重寫規則,是查詢優化的研究內容之一。
常見的查詢重寫技術型別,每一類都有自己的規則,這些規則沒有確定的、統一的規律,但重寫的核心一定是“等價轉換”,只有等價才能轉換,這是需要特別強調的。
1.3Query Optimization Algorithm
什麼是查詢優化演算法?
查詢優化,求解給定查詢語句的高效執行計劃的過程。這樣的過程,包括了多種子問題求解,不同的子問題,對應了不同的解決辦法,即演算法。
什麼是查詢計劃?
查詢計劃,也稱為查詢樹,它由一系列內部的操作符組成,這些操作符按一定的運算關係構成查詢的一個執行方案。
簡單說,就是表A和表B先連線得到中間結果,然後再和另外的表C連線得到新的中間方式,直至所有表都被連線完畢。

查詢計劃,二叉樹上的不同結點:
單表結點。考慮單表的資料獲取方式:
1直接通過IO獲得資料
2通過索引獲取資料
3通過索引定位資料的位置後再經過IO到資料塊中獲取資料
這是一個從物理儲存到記憶體解析成邏輯欄位的過程,即符合馮·諾依曼體系結構的要求(外存資料讀入記憶體才能被處理)
兩表結點(兩表連線結點)
考慮兩表以何種方式連線、代價有多大、連線路徑有哪些等。表示的是記憶體中的元祖,怎麼進行元祖間的連線。此時,元祖通常已經存在於記憶體,直接使用即可。這是一個完成使用者語義的邏輯操作,但是隻是區域性操作,只涉及兩個具體的關係。完成使用者全部語義(使用者連線的語義),需要配合多表的連線順序操作。
不同的連線演算法導致的連線效率不同,如資料量大可使用巢狀連線,資料如果有序可使用歸併連線等。
多表結點。
考慮多表連線順序如何構成代價最少的“執行計劃”。決定是AB先連線還是BC先連線,這是一個比較花費大小的運算。如果太多的連線方式被判斷,也會導致效率問題。
多個關係採用不同次序進行連線,花費的CPU資源、記憶體資源差異可能比較大。
許多資料庫採用左深樹、右深樹、緊密樹三種方式或其中一部分對多表進行連線得到多種連線路徑。
生成最優查詢計劃的策略:
1基於規則優化。
根據經驗或一些已經探知或被證明有效的方式,定義為“規則”(如根據關係代數得知的規則、根據經驗得知的規則等),用這些規則化簡單查詢計劃生成過程中符合可被化簡的操作,使用啟發式規則排除一些明顯不好的存取路徑,這就是基於規則的優化。
2基於代價優化
根據一個代價評估模型,在生成查詢計劃的過程中,計算每條儲存路徑(存取路徑主要包括上述三個”關係結點“)的花費,然後選擇代價最小的作為子路徑,這樣直至所有表連線完畢得到一個完整的路徑。
代價計算公式:
總代價=CPU代價+IO代價
主流資料庫都採用了基於代價策略進行優化的技術。
主流資料庫對於基於規則和基於代價的技術,都在使用~
基於規則優化具有操作簡單且能快速確定連線方式的優點,但這種方法只是排除了一部分不好的可能,所以得到的結果未必是最好的;
基於代價優化,是對各種可能的情況進行量化比較,從而可以得到花費最小的情況,但如果組合情況比較多則花費的判斷時間就會很多
查詢優化器的實現,多是兩種優化策略組合使用。
查詢優化為什麼要並行?
傳統單機資料庫系統中,給定一個查詢(Query),查詢優化演算法只需找到查詢的一個具有最小執行花費的執行計劃,這樣的計劃必定具有最快的響應時間。
在並行資料庫系統中,查詢優化的目標是尋找具有最小響應時間的查詢執行計劃。者需要把查詢工作分解為一些可以並行執行的子工作。一些商業資料庫提供了並行查詢功能,用以優化查詢執行操作。
查詢優化並行的條件:
一個查詢能否並行執行,取決於多種因素:
1系統中的可用資源(如記憶體、快取記憶體中的資料量等)。
2CPU的數目。
3運算中的特定代數運算子。
如A、B、C、D四個表進行連線,每個表的單表掃描可以並行進行;在生成四個表連線的查詢計劃過程中,可以選擇A和B連線的同時C和D進行連線,這樣連線操作能並行執行(操作間並行)。
不同商業資料庫,對查詢並行的實現也不盡相同。
在同一個SQL內,查詢並行可以分為:
1操作內並行。將同一操作如單表掃描操作、兩表連線操作、排序操作等分解成多個獨立的子操作,由不同的CPU同時執行。
2操作間並行。一條SQL查詢語句可以分解成多個子操作,由多個CPU執行。
Distributrd Query Optimization
在分散式資料庫系統中,查詢策略優化是查詢優化的重點。
主要是資料傳輸策略,A、B兩結點的資料進行連線,是A結點資料傳輸到B結點或者是從B到A或是先各自進行過濾然後再傳輸等,和區域性處理優化(傳統的單結點資料庫的查詢優化技術)
在查詢優化策略中,資料的通訊開銷是優化演算法考慮的主要因素。分散式查詢優化以減少傳輸的次數和資料量作為查詢優化的目標。
分散式資料庫系統中的代價估算模型,除了考慮CPU代價和I/O代價外,還要考慮通過網路在結點間傳輸資料的代價。這是分散式並行查詢優化技術與傳統單結點資料系統最大的不同之處。
在分散式資料庫系統中,代價估算模型為:總代價=I/O代價+CPU代價=通訊代價。