
Python3中的requests模組
阿新 • • 發佈:2018-12-13
目錄
requests
requests庫是 python3 中非常優秀的第三方庫,它使用 Apache2 Licensed 許可證的 HTTP 庫,用 Python 編寫,真正的為人類著想。requests 使用的是 urllib3(python3.x中的urllib),因此繼承了它的所有特性。Requests 會自動實現持久連線keep-alive,Requests 支援 HTTP 連線保持和連線池,支援使用 cookie 保持會話,支援檔案上傳,支援自動確定響應內容的編碼,支援國際化的 URL 和 POST 資料自動編碼,現代、國際化、人性化。
Requests庫中有7個主要的函式,分別是 request() 、get() 、 head() 、post() 、put() 、patch() 、delete()
| 方法 | 說明 |
|---|---|
| requests.request() | 構造一個請求,支撐一下方法的基礎方法 |
| requests.get() | 獲取HTML網頁的主要方法,對應於HTTP的GET(請求URL位置的資源) |
| requests.head() | 獲取HTML網頁頭資訊的方法,對應於HTTP的HEAD(請求URL位置的資源的頭部資訊) |
| requests.post() | 向HTML網頁提交POST請求的方法,對應於HTTP的POST(請求向URL位置的資源附加新的資料) |
| requests.put() | 向HTML網頁提交PUT請求的方法,對應於HTTP的PUT(請求向URL位置儲存一個資源,覆蓋原來URL位置的資源) |
| requests.patch() | 向HTML網頁提交區域性修改的請求,對應於HTTP的PATCH(請求區域性更新URL位置的資源) |
| requests.delete() | 向HTML網頁提交刪除請求,對應於HTTP的DELETE(請求刪除URL位置儲存的資源) |
而這幾個函式中,最常用的又是 requests.get() 函式。get函式有很多的引數,我只舉幾個比較常用的引數
| 引數 | 說明 |
|---|---|
| url | 這個不用多說,就是網站的url |
| params | 將字典或位元組序列,作為引數新增到url中,get形式的引數 |
| data | 將字典或位元組序列,作為引數新增到url中,post形式的引數 |
| headers | 請求頭,可以修改User-Agent等引數 |
| timeout | 超時時間 |
| proxies | 設定代理 |
舉例:
import requests
##設定請求頭
header = { 'Host': 'www.baidu.com',
'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
'Referer' : 'http://www.baidu.com/login/',
'Accept' : '*/*' }
##設定提交的資料
values = {'name': 'Tom',
'sex' : 'Man',
'id' : '10' }
##設定代理
proxy={"http":"http://127.0.0.1:8080"}
##請求的url
requrl="http://www.baidu.com"
response=requests.get(url=requrl,params=values,headers=header,timeout=0.1,proxies=proxy)
響應內容的處理
import requests
import urllib
value={'username':'admin',
'password':'123' }
res=requests.get("http://www.baidu.com",params=value) //Get形式提交引數
data=urllib.parse.urlencode(value)
res=requests.get("http://www.baidu.com",data=data) //post形式提交引數
res.encoding="utf-8" #設定編碼
res.status_code ##狀態碼
res.url ##請求的url
res.request.headers ##請求頭資訊,返回的是一個字典物件,不修改的話,預設是python的請求頭
res.headers ##響應頭資訊,返回的是一個字典物件
res.headers['Content-Type'] #響應頭的具體的某個屬性的資訊
cookies=res.cookies ##cookie資訊,返回的是一個字典物件
print(';'.join(['='.join(item)for item in cookies.items()])) ##打印出具體的cookies資訊
res.text ##響應內容的字串形式,即返回的頁面內容
res.content ##響應內容的二進位制形式
res.encoding='utf-8' ##設定響應的編碼
res.apparent_encoding ##從內容中分析出的響應內容編碼方式(備選編碼方式)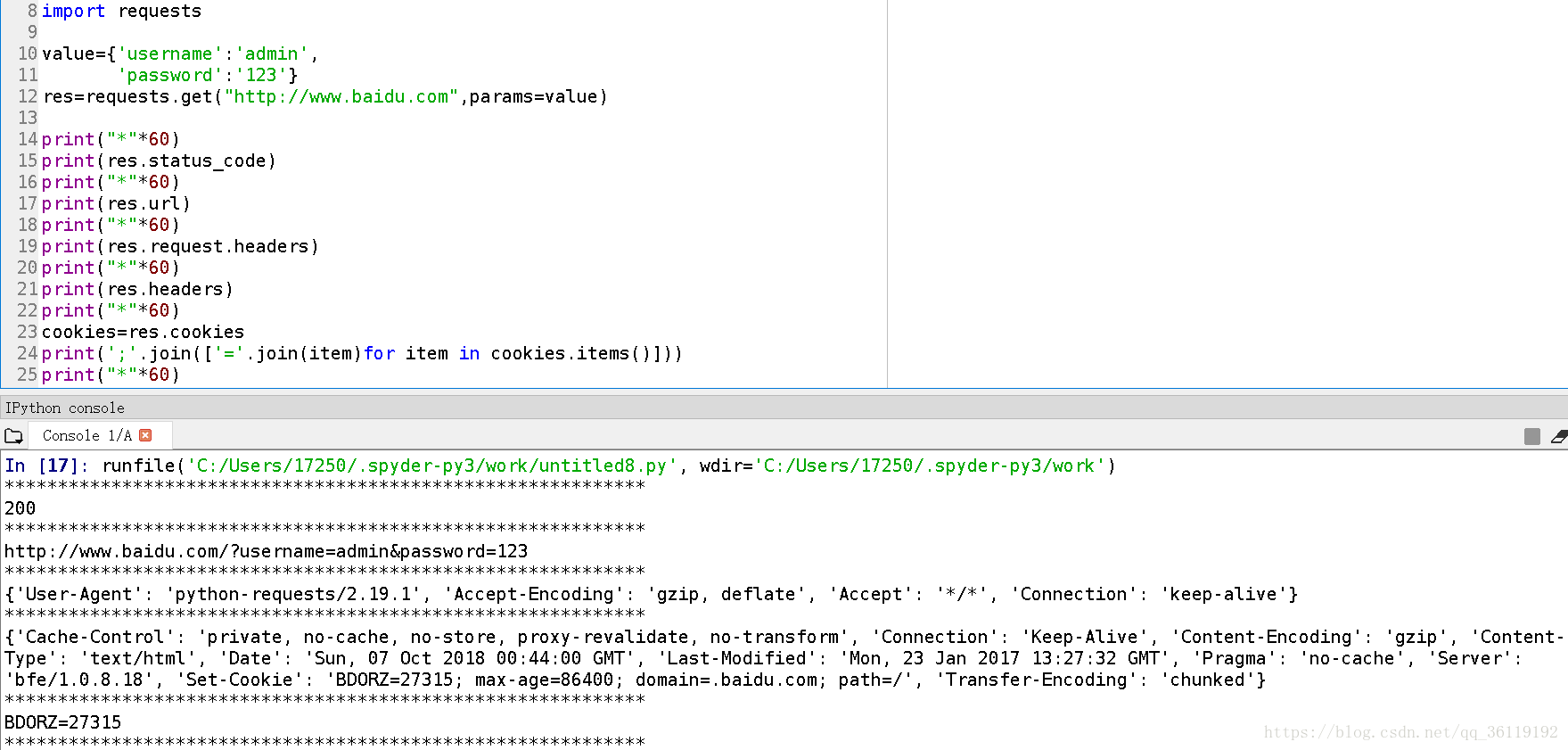
requests異常的處理
注意 requests 庫有時會產生異常,比如網路連線錯誤、http錯誤異常、重定向異常、請求url超時異常等等。所以我們需要判斷r.status_codes 是否是200,在這裡我們怎麼樣去捕捉異常呢?
這裡我們可以利用 r.raise_for_status() 語句去捕捉異常,該語句在方法內部判斷r.status_code是否等於200,如果不等於,則丟擲異常。
於是在這裡我們有一個爬取網頁的通用程式碼框架:
try:
response=requests.get(url)
r.raise_for_status() #如果狀態不是200,則引發異常
except:
print("產生異常")