
使用MapReduce計算使用者流量使用情況

相關推薦
使用MapReduce計算使用者流量使用情況
mapreduce任務排程 理解map和reduce的資料流的資料結構 專案地址:https://github.com/mouday/MapReduceDemo 參考 使用Intellij Idea打包java為可執行jar包 Idea打包
基於MapReduce的手機流量統計分析
methods ica spec err reduce same new form sel 1,代碼 package mr; import java.io.IOException; import org.apache.commons.lang.StringUtils;
理解MapReduce計算構架
p s img 結果 info win 創建文件 AR wordcount image 用Python編寫WordCount程序任務 程序 WordCount 輸入 一個包含大量單詞的文本文件 輸出 文件中每個單詞及其出現次數(頻數),並
大資料入門(9)mapreduce計算wordcount的程式編寫
1、外部寫好的程式打Java jar 包,匯入jar sftp> put e:/wc.jar 2、建立文字進行計算 vi words.log hadoop fs -mkdir /wc hadoop fs -mkdir /wc/srcData/ 3、執行jar hadoop ja
Linux檢視實時頻寬流量情況 Linux檢視實時頻寬流量情況
Linux檢視實時頻寬流量情況 Linux中檢視網絡卡流量工具有iptraf、iftop以及nethogs等,iftop可以用來監控網絡卡的實時流量(可以指定網段)、反向解析IP、顯示埠資訊等。 安裝iftop的命令如下: CentOS系統為
MapReduce計算模型二 MapReduce框架Hadoop應用(一)
之前寫過關於Hadoop方面的MapReduce框架的文章MapReduce框架Hadoop應用(一) 介紹了MapReduce的模型和Hadoop下的MapReduce框架,此文章將進一步介紹mapreduce計算模型能用於解決什麼問題及有什麼巧妙優化。 MapReduce到底解決什麼問題?
MapReduce計算模型二
中間 比較 microsoft bsp += 磁盤io 一般來說 一次 sof 之前寫過關於Hadoop方面的MapReduce框架的文章MapReduce框架Hadoop應用(一) 介紹了MapReduce的模型和Hadoop下的MapReduce框架,此文章將進一步介紹
MapReduce計算ItemCF-2
推薦系統的基本架構: 實時推薦和離線推薦 注:以下所有資料之間都是以 \t 隔開的,部落格裡顯示效果不好 資料集: 1 101 5 1 102 3 1 103 3 2 101 2 2 102 3 2 103 5 2 104 2 3 101 2 3 104
Hadoop-MapReduce計算案例1:WordCount
案例描述:計算一個檔案中每個單詞出現的數量 程式碼: package com.jeff.mr.wordCount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem;
基於HDFS的MapReduce計算框架
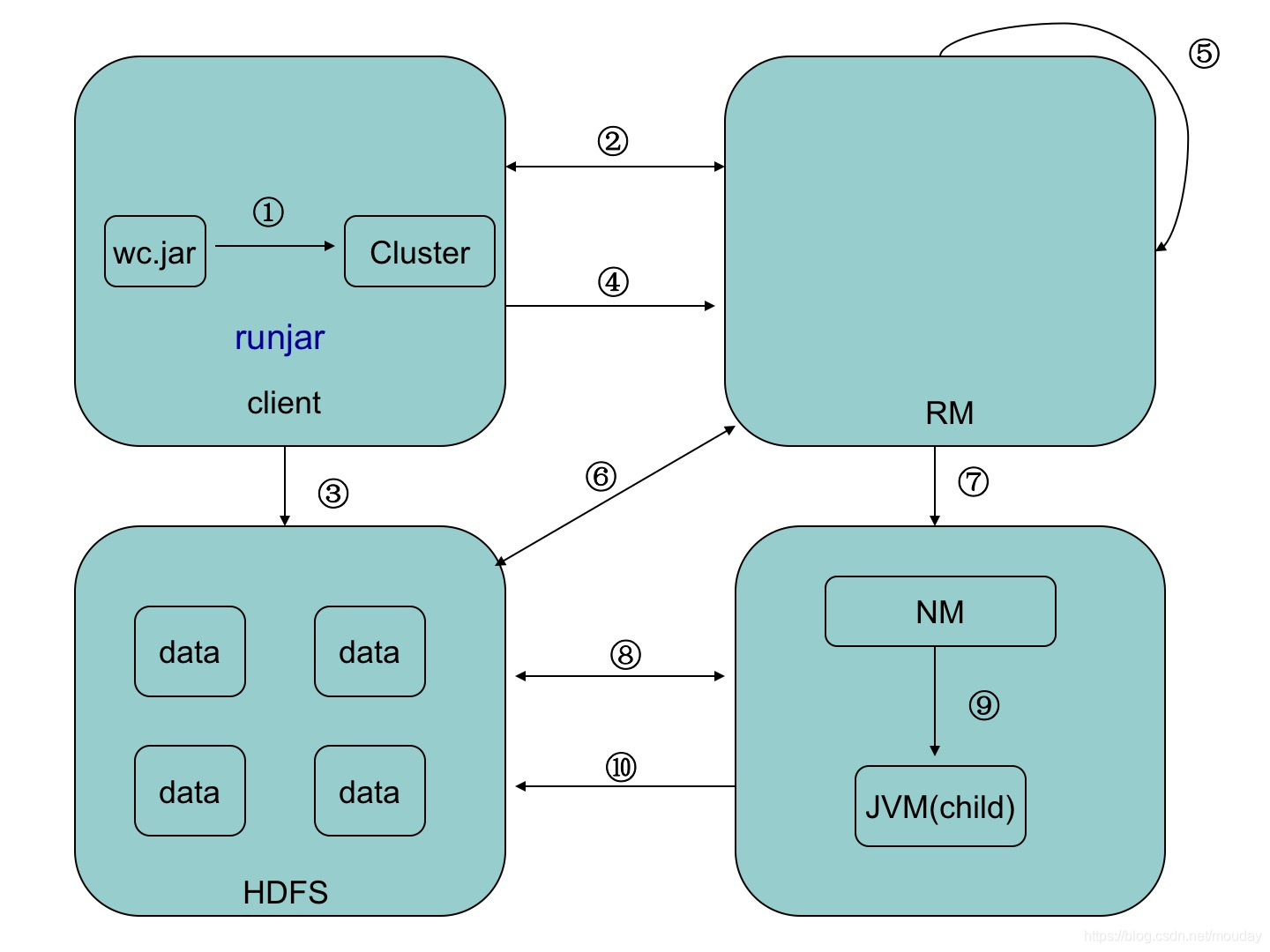
 學習MapReduce的原理(https://blog.csdn.net/Chris_MZJ/article/details/83099262)之後,我們來看看MapReduce是如何在HDFS叢集上實現的。分散式計算框架的思
日常運維管理技巧五(檢視網絡卡流量情況 nload)
nload的顯示資訊也是支援設定顯示單位的。我們可以加入-u 引數,例如下面我們輸入如命令"nload -u m",就是以MB為單位。 第一行就是網絡卡資訊,方向鍵上下切換網絡卡 預設上邊Inc
大資料SQL互動查詢 presto/spark/mapreduce 計算引擎對比
presto/spark/mapreduce 計算引擎對比 對比的表結構為146列, 15920816 行資料,資料壓縮前的大小15G。 對於執行語句的效率,單位秒 TextFile格式 執行的SQL presto spark mr SELECT COUNT
系統技術非業餘研究 » 詳解伺服器記憶體頻寬計算和使用情況測量
前段時間我們在MYSQL調優上發現有瓶頸,懷疑是過多拷貝記憶體,導致記憶體頻寬用完。在Linux下CPU的使用情況有top工具, IO裝置的使用情況有iostat工具,就是沒有記憶體使用情況的測量工具。 我們可以看到大量的memcpy和字串拷貝(可以用systemtap來測量),但是像簡單的資料移
android adb shell 查詢程序流量情況
本文僅僅是通過adb查詢應用的流量使用情況。當然在Android應用程式的Java程式碼中同樣可以獲得應用的流量使用情況。 1、獲得應用的Pid。 可以通過adb shell ps獲得所有程序資訊,裡面當然包含應用的pid和包名。然後對返回資訊
mapreduce計算平均值
當我們有每一位同學的每一科成績時,我們計算他們的平均成績,用傳統的方法比較麻煩,如果我們用hadoop中MapReduce元件的話就比較簡單了。 測試資料如下: 從上面的資料可以看到,計算每一位同學的平均成績,在map階段,我們可以用同學的姓名作為key
從 WordCount 到 MapReduce 計算模型
概述 雖然現在都在說大記憶體時代,不過記憶體的發展怎麼也跟不上資料的步伐吧。所以,我們就要想辦法減小資料量。這裡說的減小可不是真的減小資料量,而是讓資料分散開來。分開儲存、分開計算。這就是 MapReduce 分散式的核心。 版權說明 目錄
mapReduce計算 最大值-----
計算最大值,通過最後的cleanup函式,計算把所有的數目通過map , 最後的時候把最大的值放入cleanup函式中,通過這個函式返回。 -------------------------------------------------------------------
Mapreduce例項---分割槽流量彙總
一:問題介紹 給一個數據檔案,檔案包含手機使用者的各種上網資訊,求每個手機使用者的總上行流量,總下行流量和總流量;並且按號碼歸屬地分省份彙總。 資料流程: 二:需要的jar包 hadoop-2
MapReduce計算框架
默認 values 演示 有序 復雜 接下來 包括 用戶 com 2019/2/18 星期一 MapReduce計算框架Mapreduce 是一個分布式的運算編程框架,核心功能是將用戶編寫的核心邏輯代碼分布式地運行在一個集群的很多服務器上; 為什麽要MAPREDUCE(1)
自定義實現mapreduce計算的value型別
1. 在進行mapreduce程式設計時其Hadoop內建的資料型別不能滿足需求時,或針對用例優化自定義 資料型別可能執行的更好. 因此可以通過實現org.apache.hadoop.io.W