Mapreduce例項---分割槽流量彙總
阿新 • • 發佈:2019-02-09
一:問題介紹
給一個數據檔案,檔案包含手機使用者的各種上網資訊,求每個手機使用者的總上行流量,總下行流量和總流量;並且按號碼歸屬地分省份彙總。
資料流程:
二:需要的jar包
hadoop-2.4.1\share\hadoop\hdfs\hadoop-hdfs-2.4.1.jar
hadoop-2.4.1\share\hadoop\hdfs\lib\所有jar包
hadoop-2.4.1\share\hadoop\common\hadoop-common-2.4.1.jar
hadoop-2.4.1\share\hadoop\common\lib\所有jar包
hadoop-2.4.1\share\hadoop\mapreduce\除hadoop-mapreduce-examples-2.4.1.jar之外的jar包
hadoop-2.4.1\share\hadoop\mapreduce\lib\所有jar包
三:程式碼
自定義流量類:
/* * 自定義的資料型別要在hadoop叢集中傳遞,需要實現hadoop的序列化框架,就是去實現一個介面 */ public class FlowBean implements Writable{ private long upFlow; private long downFlow; private long sumFlow; //因為反射機制的需要,必須定義一個無參建構函式 public FlowBean(){}; public FlowBean(long upFlow, long downFlow) { super(); this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow+downFlow; } public void set(long upFlow, long downFlow){ this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow+downFlow; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } /* * 反序列化方法:從資料位元組流中逐個恢復出各個欄位 */ @Override public void readFields(DataInput in) throws IOException { upFlow=in.readLong(); downFlow=in.readLong(); sumFlow=in.readLong(); } /* * 序列化方法:將我們要傳輸的資料序列成位元組流 */ @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } @Override public String toString() { return upFlow+"\t"+downFlow+"\t"+sumFlow; } }
mapper類實現:
public class ProviceFlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean>{ /* * 定義成成員變數,這樣可以提高效率,減少垃圾回收。 */ private Text k=new Text(); private FlowBean bean=new FlowBean(); @Override protected void map(LongWritable key, Text value,Context context)throws IOException, InterruptedException { String line = value.toString(); String[] fields = StringUtils.split(line, '\t'); String phone=fields[1]; long upFlow=Long.parseLong(fields[fields.length-3]); long downFlow=Long.parseLong(fields[fields.length-2]); k.set(phone); bean.set(upFlow, downFlow); context.write(k, bean); } }
reducer類實現:
public class ProvinceFlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean>{
private FlowBean bean=new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values,Context context)throws IOException, InterruptedException {
long upFlowSum=0;
long downFlowSum=0;
for(FlowBean value : values){
upFlowSum+=value.getUpFlow();
downFlowSum+=value.getDownFlow();
}
bean.set(upFlowSum, downFlowSum);
context.write(key, bean);
}
}job提交客戶端實現:
/*
* 用於提交本job的一個客戶端類
*/
public class ProvinceFlowCountJobSubmitter {
public static void main(String[] args) throws Exception {
if(args.length<2){
System.err.println("引數不正確:輸入資料路徑 輸出資料路徑");
System.exit(2);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(ProvinceFlowCountJobSubmitter.class);
job.setMapperClass(ProviceFlowCountMapper.class);
job.setReducerClass(ProvinceFlowCountReducer.class);
//map輸出的kv型別與reduce輸出的kv型別一致時,這兩行可以省略
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
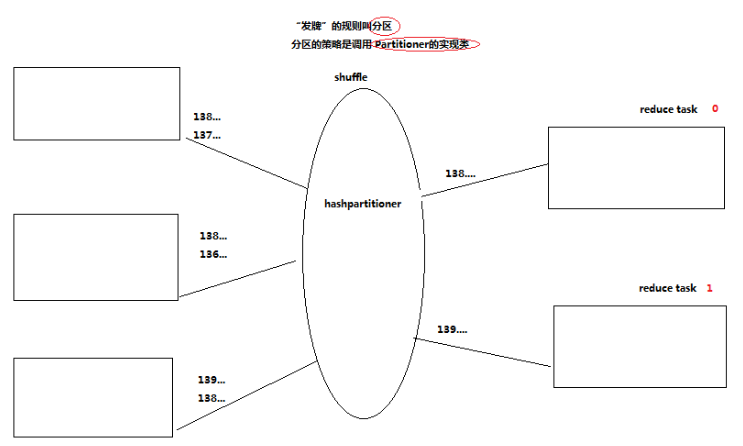
//通過顯示指定partitioner類來讓我們自定義的partitoner起作用,替換掉系統預設的hashpartitioner
job.setPartitionerClass(ProvincePartitioner.class);
/*
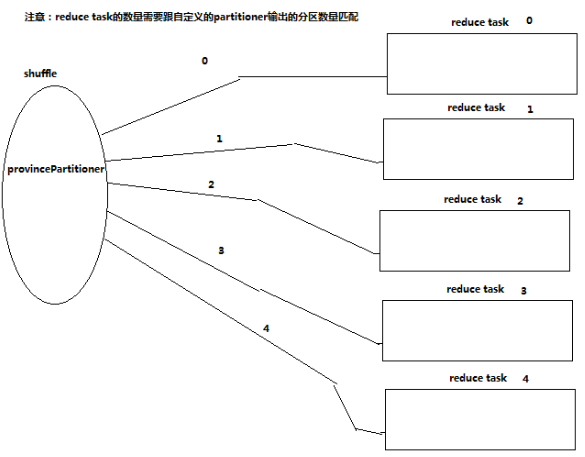
* 設定本次job執行時的reduce task程序數,數量應該跟partitioner的分割槽數匹配
* 預設情況下,reduce task的數量為1
* 如果不匹配:
* 當reduce task程序數大於partitioner的分割槽數,結果個數為reduce task程序數,但多餘的為空。
* 當reduce task程序數小於partitioner的分割槽數
* 如果reduce task程序數為1,則所有結果在一個檔案內,相當於未進行分割槽操作;
* 否則,報錯。
*/
job.setNumReduceTasks(5);
/*
* 處理的資料檔案地址
* 資料檔案處理後結果存放地址
* 從終端獲得引數
*/
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean success = job.waitForCompletion(true);
System.exit(success?0:1);
}
}自定義partitoner類實現
/*
* KEY為Mapper輸出的key
* VALUE為Mapper輸出的value
*/
public class ProvincePartitioner extends Partitioner<Text,FlowBean>{
private static HashMap<String, Integer> provinceMap = new HashMap<String, Integer>();
//在partitioner初始化的時候就將外部字典資料一次性載入到本地記憶體中
static{
//載入外部的字典資料到本地記憶體
provinceMap.put("136", 0);
provinceMap.put("137", 1);
provinceMap.put("138", 2);
provinceMap.put("139", 3);
}
//numReduceTasks為reduce task程序的數量
@Override
public int getPartition(Text key, FlowBean value, int numReduceTasks) {
//取手機號的字首
String prefix =key.toString().substring(0, 3);
//從字典資料中查詢歸屬地的分割槽號
Integer provinceNum = provinceMap.get(prefix);
if(provinceNum==null) provinceNum=4;
return provinceNum;
}
}四:操作流程
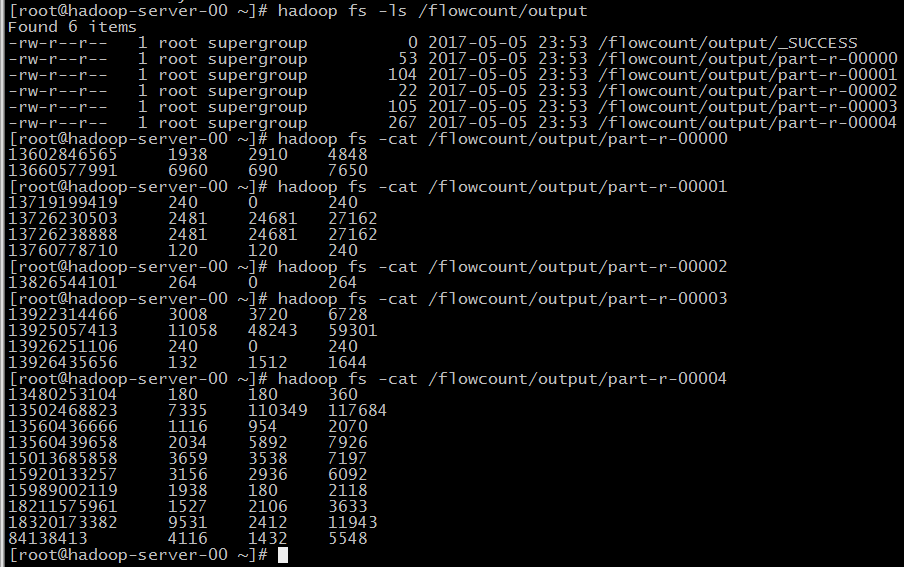
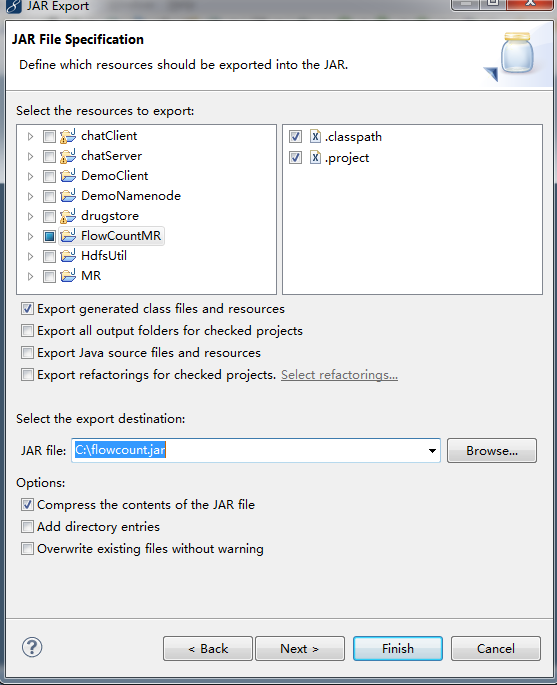
1、將專案打成jar包並上傳到虛擬機器上

2、把資料檔案上傳到hdfs上


3、執行jar檔案

4、結果