
LSTM時間序列預測及網路層搭建
1. LSTM預測未來一年某航空公司的客運流量
這裡的問題是:給你一個數據集,只有一列資料,這是一個關於時間序列的資料,從這個時間序列中預測未來一年某航空公司的客運流量。
資料形式:
time passengers
0 1949-01 112
1 1949-02 118
2 1949-03 132
3 1949-04 129
4 1949-05 121
5 1949-06 135
6 1949-07 148
7 1949-08 148 下面的程式碼主要分為以下幾步:
- LSTM資料預處理
- 搭建LSTM模型訓練
- 模型預測
資料預處理這塊參考上面的連結就可以,而模型的搭建是基於keras的模型,稍微有點疑惑的地方就是資料的構建(訓練集和測試集),還有資料的預處理方法的問題。
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn. 執行結果:
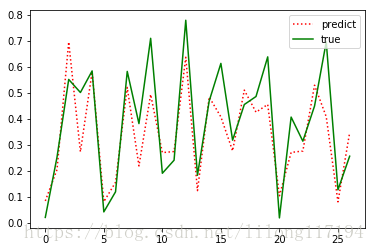
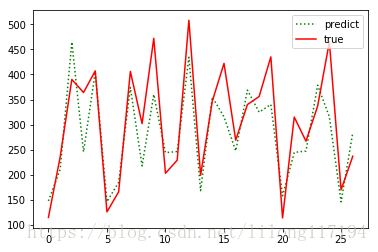
從結果可以看出預測效果還可以,但是理論上存在諸多問題:
- 在normalize data的時候,直接拿所有的data, data_all 去normalize, 但合理的做法應該是normalize train, 然後用train的parameter 去normalize test。因為用整個data set 去normalize 的話相當於提前獲取了未來的資訊。
- 就是原始碼中的打亂資料順序,本質上造成了歷史和未來的混淆,實際是用到了未來的資料預測趨勢,overfitting了。
基於以上的主要問題,在完全沒有未來資料參與下進行訓練,進行修改後的資料處理過程如下:全集—分割—訓練集歸一訓練—驗證集使用訓練集std&mean進行歸一完成預測。
這裡就是先試下沒有打亂資料的情況,就是按照順序的資料集構建進行訓練和預測:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import LSTM, Dense, Activation
# 資料集的構建
def dataset_func(data_pro,sequence_length=10):
data = []
# 構造資料集:構造送入lstm的3D資料
for i in range(len(data_pro) - sequence_length - 1):
data.append(data_pro[i: i + sequence_length + 1])
reshaped_data = np.array(data).astype('float64')
print('here:',reshaped_data.shape)
# 打亂資料集
#np.random.shuffle(reshaped_data)
print('reshaped_data:',reshaped_data[0])
# 資料集的特徵和標籤分開:樣本中的每11個數據中的第11個作為樣本標籤
x = reshaped_data[:, :-1]
print('samples:',x.shape)
y = reshaped_data[:, -1]
print('labels:',y.shape)
return x,y
def load_data(file_name, sequence_length=10, split=0.8):
# 提取資料一列
df = pd.read_csv(file_name, sep=',', usecols=[1])
# 把資料轉換為陣列
data_all = np.array(df).astype(float)
print('length of data_all:',data_all.shape)
# 全集劃分:80%的訓練資料
split_boundary = int(data_all.shape[0] * split)
print(split_boundary)
train_x = data_all[: split_boundary]
print(train_x.shape)
# 訓練集的歸一化:將資料縮放至給定的最小值與最大值之間,這裡是0與1之間,資料預處理
scaler = MinMaxScaler()
data_train = scaler.fit_transform(train_x)
print('length:',len(data_train))
train_x,train_y=dataset_func(data_train,sequence_length=10)
# 全集劃分:20%的驗證資料
test_x = data_all[split_boundary:]
print(test_x.shape)
data_test = scaler.transform(test_x)
print('length:',len(data_test))
test_x,test_y=dataset_func(data_test,sequence_length=10)
# 返回處理好的資料
return train_x, train_y, test_x, test_y, scaler
# 模型建立
def build_model():
# input_dim是輸入的train_x的最後一個維度,train_x的維度為(n_samples, time_steps, input_dim)
model = Sequential()
model.add(LSTM(input_dim=1, output_dim=50, return_sequences=True))
print(model.layers)
model.add(LSTM(100, return_sequences=False))
model.add(Dense(output_dim=1))
model.add(Activation('linear'))
model.compile(loss='mse', optimizer='rmsprop')
return model
def train_model(train_x, train_y, test_x, test_y):
model = build_model()
try:
model.fit(train_x, train_y, batch_size=512, nb_epoch=30, validation_split=0.1)
predict = model.predict(test_x)
predict = np.reshape(predict, (predict.size, ))
except KeyboardInterrupt:
print(predict)
print(test_y)
print('predict:\n',predict)
print('test_y:\n',test_y)
# 預測的散點值和真實的散點值畫圖
try:
fig1 = plt.figure(1)
plt.plot(predict, 'r:')
plt.plot(test_y, 'g-')
plt.legend(['predict', 'true'])
except Exception as e:
print(e)
return predict, test_y
if __name__ == '__main__':
# 載入資料
train_x, train_y, test_x, test_y, scaler = load_data('international-airline-passengers.csv')
train_x = np.reshape(train_x, (train_x.shape[0], train_x.shape[1], 1))
test_x = np.reshape(test_x, (test_x.shape[0], test_x.shape[1], 1))
# 模型訓練
predict_y, test_y = train_model(train_x, train_y, test_x, test_y)
# 對標準化處理後的資料還原
predict_y = scaler.inverse_transform([[i] for i in predict_y])
test_y = scaler.inverse_transform(test_y)
# 把預測和真實資料對比
fig2 = plt.figure(2)
plt.plot(predict_y, 'g:')
plt.plot(test_y, 'r-')
plt.legend(['predict', 'true'])
plt.show()
主要就是資料的構建改變了,執行結果如下:
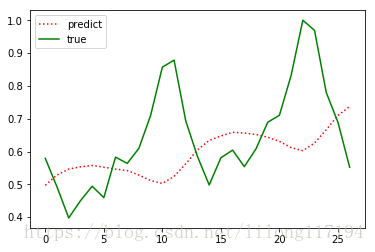
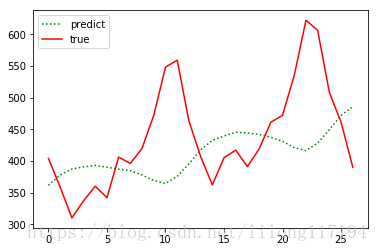
可以看出效果很差,具體為什麼按照常規的順序資料構建(不打亂)預測效果那麼差,還在思考中。。。。
下面又嘗試了:全集—分割—訓練集歸一shuffle並記錄std&mean—訓練—驗證集使用訓練集std&mean進行歸一完成預測。
僅僅把上面程式碼中資料順序打亂的註釋去掉就可以了:
#np.random.shuffle(reshaped_data)
再次訓練得到:
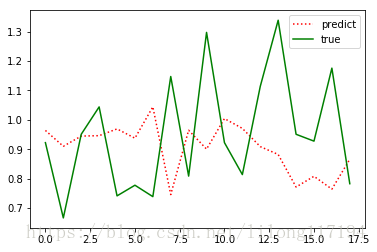
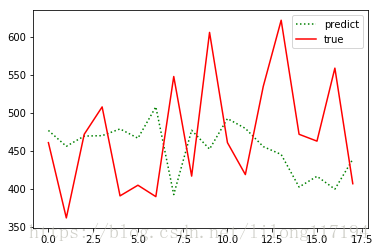
效果還是不理想,所以這裡僅僅作為學習的過程,以後再研究。
2. keras的lstm層函式
keras.layers.recurrent.LSTM(units, activation='tanh', recurrent_activation='hard_sigmoid', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0)
2.1 引數說明:
- units:輸出維度
- input_dim:輸入維度,當使用該層為模型首層時,應指定該值(或等價的指定input_shape)
- return_sequences:布林值,預設False,控制返回型別。若為True則返回整個序列,否則僅返回輸出序列的最後一個輸出
- input_length:當輸入序列的長度固定時,該引數為輸入序列的長度。當需要在該層後連線Flatten層,然後又要連線Dense層時,需要指定該引數,否則全連線的輸出無法計算出來。
2.2 輸入shape :
形如(samples,timesteps,input_dim)的3D張量
2.3 輸出shape:
如果return_sequences=True:返回形如(samples,timesteps,output_dim)的3D張量,否則返回形如(samples,output_dim)的2D張量。
2.4 輸入和輸出的型別 :
相對之前的tensor,這裡多了個引數timesteps,其表示什麼意思?假如我們輸入有100個句子,每個句子都由5個單片語成,而每個單詞用64維的詞向量表示。那麼samples=100,timesteps=5,input_dim=64,可以簡單地理解timesteps就是輸入序列的長度input_length(視情而定)
2.5 units :
假如units=128,就一個單詞而言,你可以把LSTM內部簡化看成 :
,X為上面提及的詞向量比如64維,W中的128就是units,也就是說通過LSTM,把詞的維度由64轉變成了128
2.6 return_sequences
我們可以把很多LSTM層串在一起,但是最後一個LSTM層return_sequences通常為false,具體看下面的例子:
句子:you are really a genius
model = Sequential()
model.add(LSTM(128, input_dim=64, input_length=5, return_sequences=True))
model.add(LSTM(256, return_sequences=False))
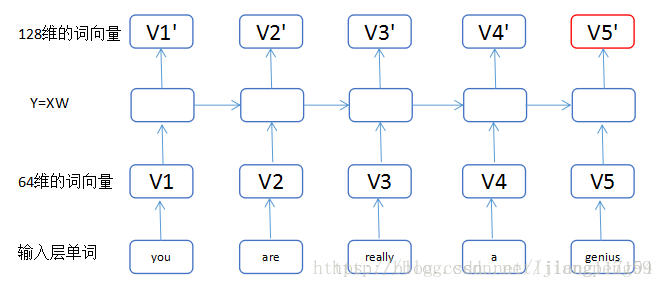
(1)我們把輸入的單詞,轉換為維度64的詞向量,最下面一層的小矩形的數目即單詞的個數input_length(每個句子的單詞個數)。
(2)通過第一個LSTM中的Y=XW,這裡輸入為維度64,輸出為維度128,而return_sequences=True,我們可以獲得5個128維的詞向量
(3)通過第二個LSTM(這裡上圖沒有顯示出來,最上面應該還有一層),此時輸入為都為128維,經轉換後得到為256維,最後因為return_sequences=False,所以只輸出了最後一個紅色的詞向量。
下面是一個動態圖,有助於理解:

2.7 在實際應用中,有如下的表示形式:
- 輸入維度 input_dim=1
- 輸出維度 output_dim=6
- 滑動視窗 input_length=10
model.add(LSTM(input_dim=1, output_dim=6,input_length=10, return_sequences=True))
model.add(LSTM(6, input_dim=1, input_length=10, return_sequences=True))
model.add(LSTM(6, input_shape=(10, 1),return_sequences=True))