
機器學習學習筆記 第十七章 支援向量機
阿新 • • 發佈:2018-12-14
支援向量機(Support Vector Machine)
以前非常厲害的一個演算法,不過後來遇到了對手——神經網路
這個也是面試的時候經常會問到的非常重要的一個演算法
- SVM要解決的問題:什麼樣的決策邊界才是最好的,如下圖中兩堆點怎麼區分
- 不過這裡不是要區分這兩堆點,而是舉個例子,後面會進行支援向量機的推導

- 不過這裡不是要區分這兩堆點,而是舉個例子,後面會進行支援向量機的推導
-
那麼我們來討論一下決策邊界
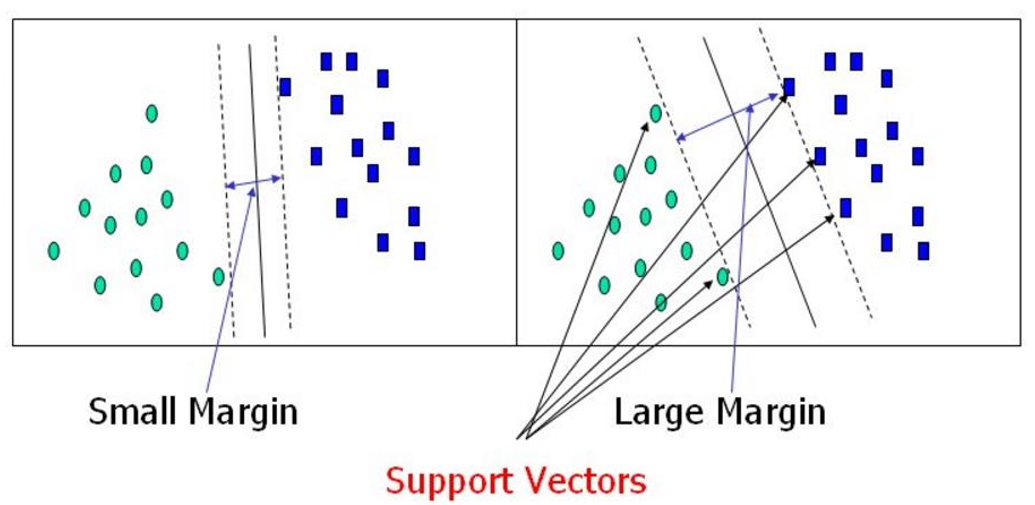
- 這兩個圖分別用不同的決策邊界
- 可見,第二個圖的決策邊界更好,與兩邊的距離更寬,區分度越明顯
為了更好理解邊界的劃分過程,我們先推導一下點到平面的距離公式
引用百度百科的一張圖

- 我們簡化一下:這裡我們設是平面的法向量,則平面可以表示為,我們假設空間中一點座標為我們推匯出來
下面再來說說資料標籤的定義,因為後面我們要利用支援向量機對資料進行分析,我們先來熟悉一下資料
- 先假設資料集
- 其中是資料的類別,定義如下:
- 注意設定的是和,而不是和
- 那麼,我們利用上面定義好的資料後,就可以定義決策方程了
-
決策方程的定義:
- 基於上面的距離公式,並且將轉換為函式,有如下公式:
- 基於上面的距離公式,並且將轉換為函式,有如下公式:
有了以上的公式之後,我們就可以確立我們的優化目標了
- 我們看回去第二個圖,我們就是要找一條直線,離兩邊的點都足夠遠,越遠越好,這樣能最好地區分出兩邊的點
- 我們先將點到直線的距離都化簡一下:
- 因為,因此這裡將分子的絕對值去掉了,其實這個純粹是因為加上去讓後面好處理的
通過這個公式,我們可以得出我們的優化目標
- 上式的意思是首先尋找最小距離,也即即兩邊的點到你要求的那條分割線的最小距離,然後再給這個最小距離求最大值,也即外面的
- 但其實我們還是不方便求解這個函式,那麼我們換一個思路,先進行放縮變換試試:
- 對於方程,我們可以嘗試通過放縮使,也即(注意,沒通過放縮之前是的)
- 通過放縮之後,我們是不是就可以通過而認為了,因為我們放縮的目的就是想讓最小值變成1,這樣後面直接把當做是1而忽略掉
- 至此,原優化目標簡化為
如何求解極大值呢
- 線上性迴歸的時候我們試過求極小值,卻沒試過求極大值,那我們是不是可以取一個倒數變成求最小值的問題呢
- 上式還帶有絕對值,用著很不爽,那我們轉換成求
- 之所以前面帶一個是因為後面求導的時候正好能把