
機器學習學習筆記 第十九章 聚類演算法-K-MEANS
阿新 • • 發佈:2018-12-31
聚類演算法
聚類的概念:
- 主要用來處理無監督問題,因為我們手上沒有標籤了,靠電腦自己進行分類
- 聚類是指把相似的東西分到一組
- 難點
- 如何評估呢(因為沒有了標籤,難以對比正確與否,很多評估方法失效了)
- 如何調參呢
K-MEANS的概念
- K是指要得到的簇的數量,如下圖所示應該要得到三個簇,K值需要我們自己指定
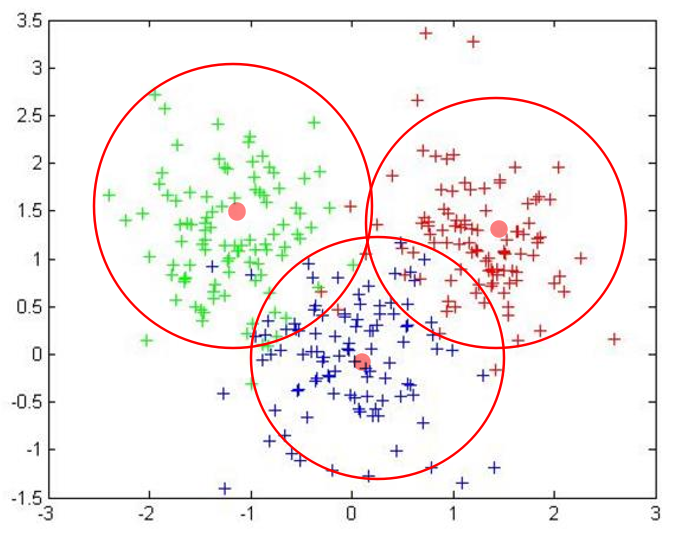
- 質心
- 其實是均值,如上圖中的小紅點,取向量各位的平均值
- 距離的度量
- 常常使用歐氏距離和預先相似度,不過要先進行標準化,令不同座標的取值都在0~1之間
- 優化目標
- 說白了就是想讓每個簇中所有的點到中心點的距離越小越好
- 公式如下:
K-MEANS演算法的工作流程
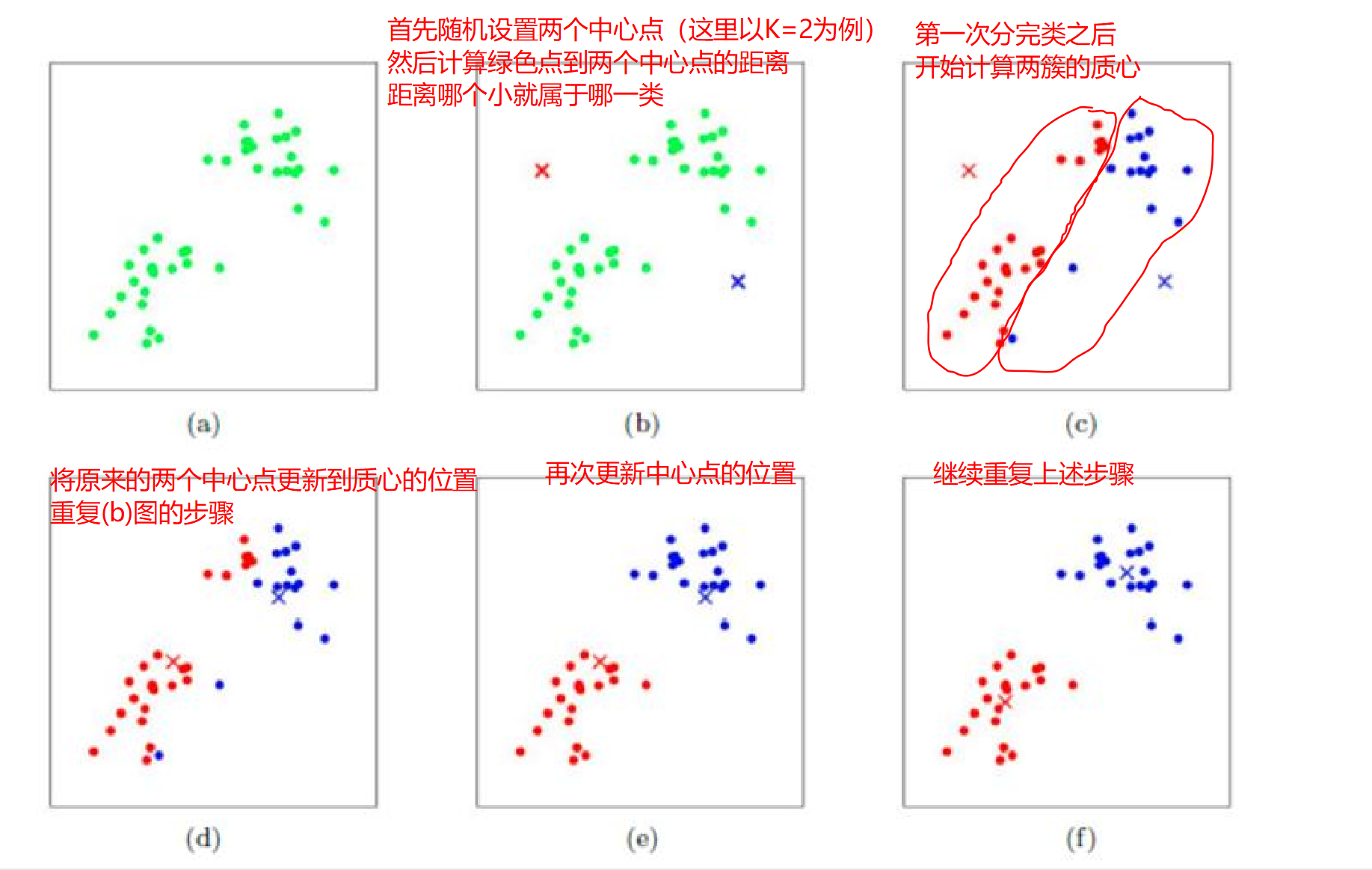
優勢
- 簡單快速,比較適合於常規的資料集
劣勢
- K值很難確定,有時候需要大量的嘗試
- 複雜度於樣本呈線性關係(其實我感覺複雜度也不是很高,不知道是不是我理解上出了問題)
- 很難發現任意形狀的簇,比如兩個簇呈環形的關係
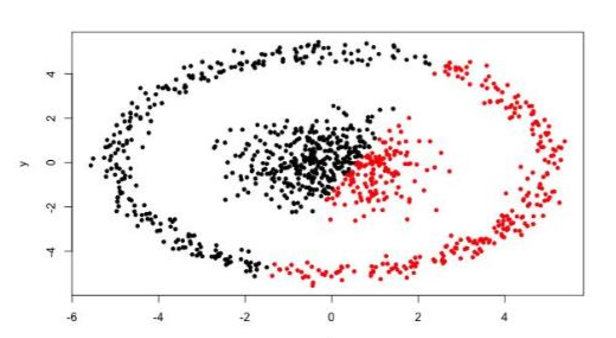
推薦一個視覺化展示K-MEANS的網站,大家通過嘗試可以更加直觀地理解聚類K-MEANS演算法的工作流程
- 一開啟網站如下
- 隨機選一個型別進入,這裡我試試Gaussian Mixture
- 他給隨機分好了三堆,那我們嘗試一下新增中心點,比如此處我們新增三個中心點吧
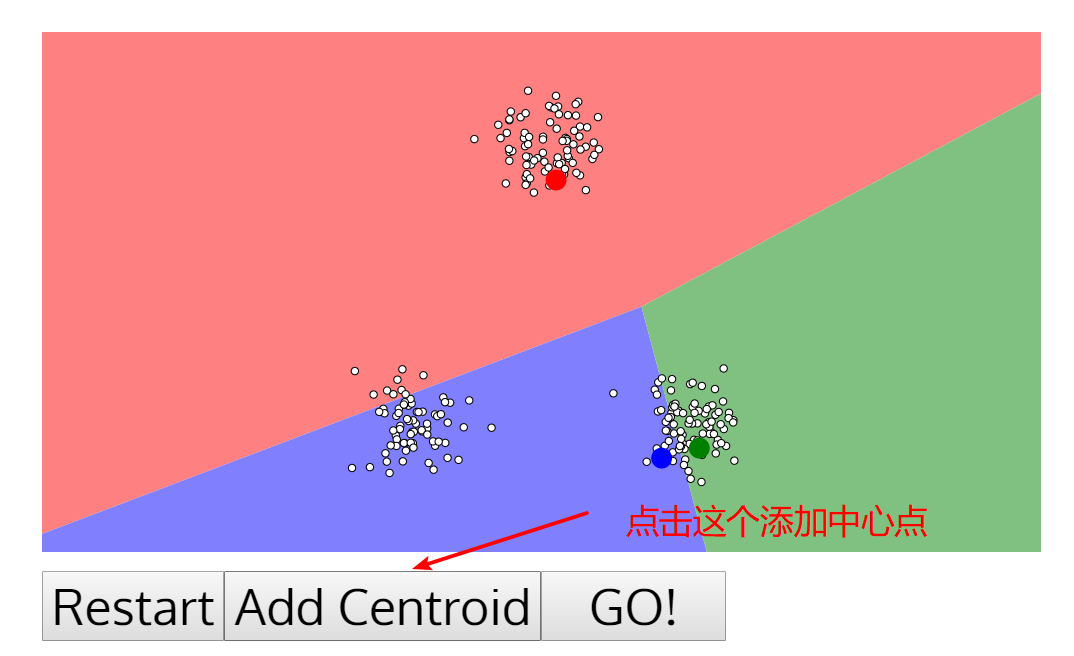
- 我們再點選Go就好,就能模擬出上述講過的流程了
通過K-MEANS聚類演算法實現影象的壓縮
- 這個壓縮很暴力
- 壓縮出來是一個面目全非的灰度圖,而且建議大家拿個小圖去試,大圖要跑好久好久
from skimage import io
from sklearn.cluster import KMeans
import numpy as np
image = io.imread('1.jpg')
io.imshow(image)
io.show()

row = image.shape[0]
col = image. 1080
1920
kmeans = KMeans(n_clusters=128, n_init=10, max_iter=200)#分成128個簇了,因為一開始影象的rgb顏色通道數值取值範圍是0~255,此處想壓縮一到原來的一半,因此分成128個簇,原本畫素靠近哪個就歸類於哪個簇中,歸類到的簇當成是最後的rgb值,其餘兩個引數都沒那麼重要,max_iter是最大的迭代次數
kmeans.fit(image)
clusters = np.asarray(kmeans.cluster_centers_, dtype=np.uint8)
labels = np.asarray(kmeans.labels_, dtype=np.uint8)
labels = labels.reshape(row, col)
io.imshow(labels)
io.show()
對唐宇迪老師的機器學習教程進行筆記整理
編輯日期:2018-10-12
小白一枚,請大家多多指教