
Flume+Kafka+Storm+Redis實時分析系統基本架構
阿新 • • 發佈:2018-12-14
今天作者要在這裡通過一個簡單的電商網站訂單實時分析系統和大家一起梳理一下大資料環境下的實時分析系統的架構模型。當然這個架構模型只是實時分析技術的一 個簡單的入門級架構,實際生產環境中的大資料實時分析技術還涉及到很多細節的處理, 比如使用Storm的ACK機制保證資料都能被正確處理, 叢集的高可用架構, 消費資料時如何處理重複資料或者丟失資料等問題,根據不同的業務場景,對資料的可靠性要求以及系統的複雜度的要求也會不同。這篇文章的目的只是帶大家入個門,讓大家對實時分析技術有一個簡單的認識,並和大家一起做學習交流。
文章的最後還有Troubleshooting,分享了作者在部署本文示例程式過程中所遇到的各種問題和解決方案。
系統基本架構
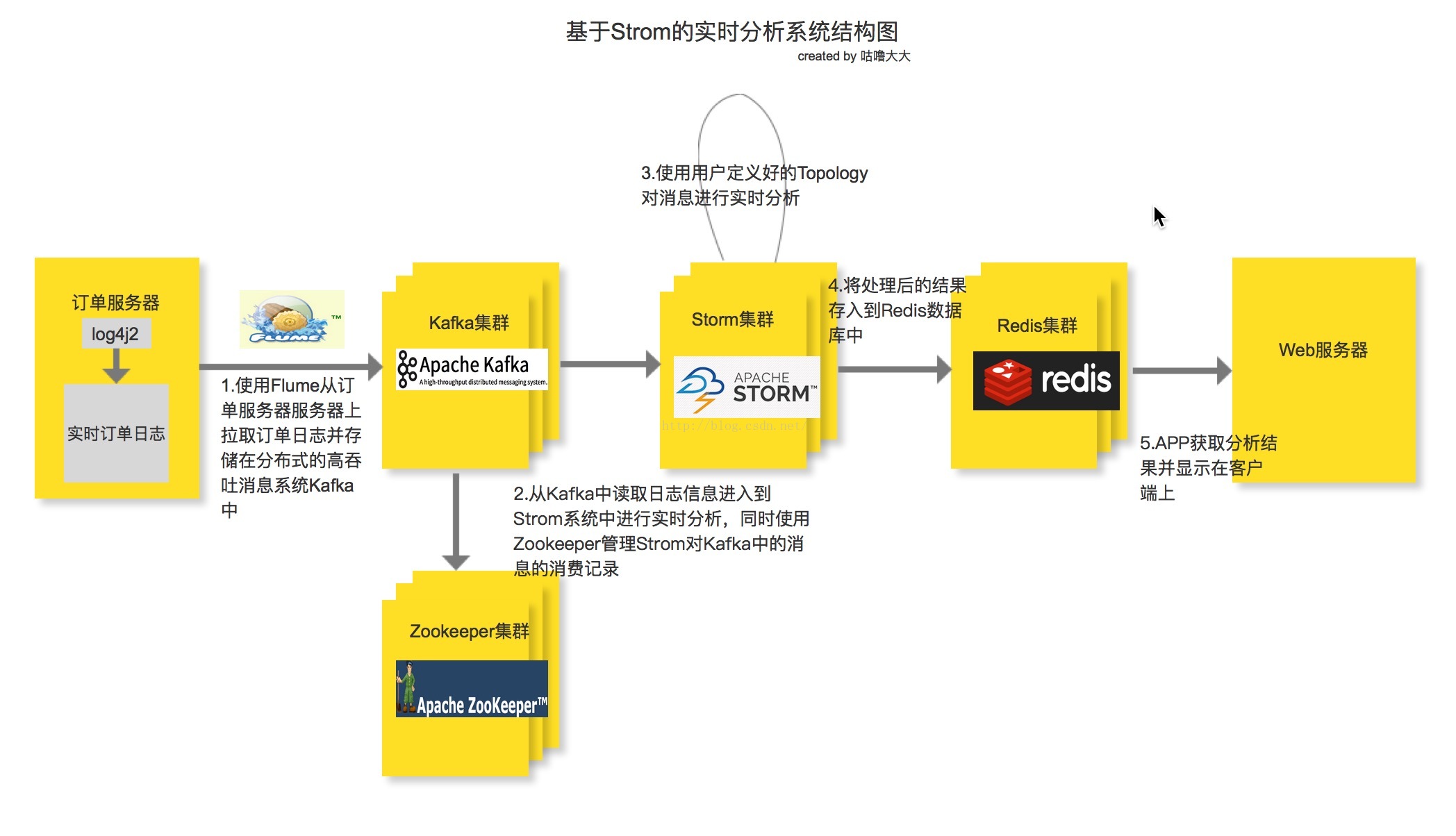
整個實時分析系統的架構就是先由電商系統的訂單伺服器產生訂單日誌, 然後使用Flume去監聽訂單日誌,並實時把每一條日誌資訊抓取下來並存進Kafka訊息系統中, 接著由Storm系統消費Kafka中的訊息,同時消費記錄由Zookeeper叢集管理,這樣即使Kafka宕機重啟後也能找到上次的消費記錄,接著從上次宕機點繼續從Kafka的Broker中進行消費。但是由於存在先消費後記錄日誌或者先記錄後消費的非原子操作,如果出現剛好消費完一條訊息並還沒將資訊記錄到Zookeeper的時候就宕機的類似問題,或多或少都會存在少量資料丟失或重複消費的問題, 其中一個解決方案就是Kafka的Broker和Zookeeper都部署在同一臺機子上。接下來就是使用使用者定義好的Storm Topology去進行日誌資訊的分析並輸出到Redis快取資料庫中(也可以進行持久化),最後用Web APP去讀取Redis中分析後的訂單資訊並展示給使用者。之所以在Flume和Storm中間加入一層Kafka訊息系統,就是因為在高併發的條件下, 訂單日誌的資料會井噴式增長,如果Storm的消費速度(Storm的實時計算能力那是最快之一,但是也有例外, 而且據說現在Twitter的開源實時計算框架Heron比Storm還要快)慢於日誌的產生速度,加上Flume自身的侷限性,必然會導致大量資料滯後並丟失,所以加了Kafka訊息系統作為資料緩衝區,而且Kafka是基於log File的訊息系統,也就是說訊息能夠持久化在硬碟中,再加上其充分利用Linux的I/O特性,提供了可觀的吞吐量。架構中使用Redis作為資料庫也是因為在實時的環境下,Redis具有很高的讀寫速度。
業務背景
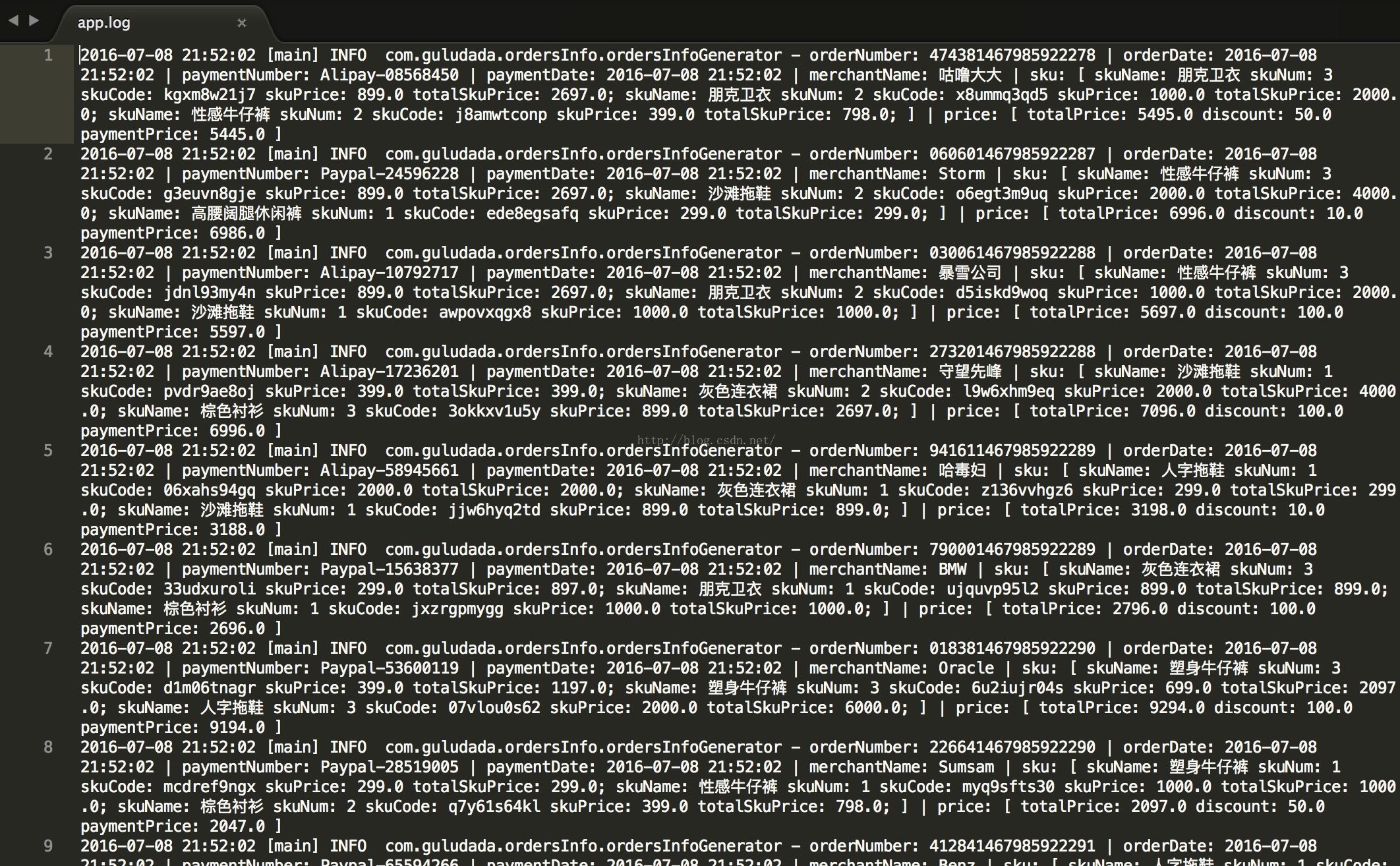
既然要分析訂單資料,那必然在訂單產生的時候要把訂單資訊記錄在日誌檔案中。本文中,作者通過使用log4j2,以及結合自己之前開發電商系統的經驗,寫了一個訂單日誌生成模擬器,程式碼如下,能幫助大家隨機產生訂單日誌。下面所展示的訂單日誌檔案格式和資料就是我們本文中的分析目標,本文的案例中用來分析所有商家的訂單總銷售額並找出銷售額錢20名的商家。
訂單資料格式:
orderNumber: XX | orderDate: XX | paymentNumber: XX | paymentDate: XX | merchantName: XX | sku: [ skuName: XX skuNum: XX skuCode: XX skuPrice: XX totalSkuPrice: XX;skuName: XX skuNum: XX skuCode: XX skuPrice: XX totalSkuPrice: XX;
訂單日誌生成程式:
使用log4j2將日誌資訊寫入檔案中,每小時滾動一次日誌檔案
[plain] view plain copy

[plain] view plain copy
收集日誌資料
採集資料的方式有多種,一種是通過自己編寫shell指令碼或Java程式設計採集資料,但是工作量大,不方便維護,另一種就是直接使用第三方框架去進行日誌的採集,一般第三方框架的健壯性,容錯性和易用性都做得很好也易於維護。本文采用第三方框架Flume進行日誌採集,Flume是一個分散式的高效的日誌採集系統,它能把分佈在不同伺服器上的海量日誌檔案資料統一收集到一個集中的儲存資源中,Flume是Apache的一個頂級專案,與Kafka也有很好的相容性。不過需要注意的是Flume並不是一個高可用的框架,這方面的優化得使用者自己去維護。
Flume的agent是執行在JVM上的,所以各個伺服器上的JVM環境必不可少。每一個Flume agent部署在一臺服務器上,Flume會收集web server產生的日誌資料,並封裝成一個個的事件傳送給Flume Agent的Source,Flume Agent Source會消費這些收集來的資料事件(Flume Event)並放在Flume Agent Channel,Flume Agent Sink會從Channel中收集這些採集過來的資料,要麼儲存在本地的檔案系統中要麼作為一個消費資源分給下一個裝在分散式系統中其它伺服器上的Flume Agent進行處理。Flume提供了點對點的高可用的保障,某個伺服器上的Flume Agent Channel中的資料只有確保傳輸到了另一個伺服器上的Flume Agent Channel裡或者正確儲存到了本地的檔案儲存系統中,才會被移除。
在本文中,Flume的Source我們選擇的是Exec Source,因為是實時系統,直接通過tail 命令來監聽日誌檔案,而在Kafka的Broker叢集端的Flume我們選擇Kafka Sink 來把資料下沉到Kafka訊息系統中。
下圖是來自Flume官網裡的Flume拉取資料的架構圖:

圖片來源:http://flume.apache.org/FlumeUserGuide.html
訂單日誌產生端的Flume配置檔案如下:
[plain] view plain copy
Kafka 訊息系統端Flume配置檔案
[plain] view plain copy
這裡需要注意的是,在日誌伺服器端的Flume agent中我們配置了一個interceptors,這個是用來為Flume Event(Flume Event就是拉取到的一行行的日誌資訊)的頭部新增key為“topic”的K-V鍵值對,這樣這條抓取到的日誌資訊就會根據topic的值去到Kafka中指定的topic訊息池中,當然還可以為Flume Event額外配置一個key為“Key”的鍵值對,Kafka Sink會根據key“Key”的值將這條日誌資訊下沉到不同的Kafka分片上,否則就是隨機分配。在Kafka叢集端的Flume配置裡,有幾個重要的引數需要注意,“topic”是指定抓取到的日誌資訊下沉到Kafka哪一個topic池中,如果之前Flume傳送端為Flume Event添加了帶有topic的頭資訊,則這裡可以不用配置;brokerList就是配置Kafka叢集的主機地址和埠;requireAcks=1是配置當下沉到Kafka的訊息儲存到特定partition的leader中成功後就返回確認訊息,requireAcks=0是不需要確認訊息成功寫入Kafka中,requireAcks=-1是指不光需要確認訊息被寫入partition的leander中,還要確認完成該條訊息的所有備份;batchSize配置每次下沉多少條訊息,每次下沉的數量越多延遲也高。
Kafka訊息系統
這一部分我們將談談Kafka的配置和使用,Kafka在我們的系統中實際上就相當於起到一個數據緩衝池的作用, 有點類似於ActiveQ的訊息佇列和Redis這樣的快取區的作用,但是更可靠,因為是基於log File的訊息系統,資料不容易丟失,以及能記錄資料的消費位置並且使用者還可以自定義訊息消費的起始位置,這就使得重複消費訊息也可以得以實現,而且同時具有佇列和釋出訂閱兩種訊息消費模式,十分靈活,並且與Storm的契合度很高,充分利用Linux系統的I/O提高讀寫速度等等。另一個要提的方面就是Kafka的Consumer是pull-based模型的,而Flume是push-based模型。push-based模型是儘可能大的消費資料,但是當生產者速度大於消費者時資料會被覆蓋。而pull-based模型可以緩解這個壓力,消費速度可以慢於生產速度,有空餘時再拉取那些沒拉取到的資料。
Kafka是一個分散式的高吞吐量的訊息系統,同時兼有點對點和釋出訂閱兩種訊息消費模式。Kafka主要由Producer,Consumer和Broker組成。Kafka中引入了一個叫“topic”的概念,用來管理不同種類的訊息,不同類別的訊息會記錄在到其對應的topic池中,而這些進入到topic中的訊息會被Kafka寫入磁碟的log檔案中進行持久化處理。Kafka會把訊息寫入磁碟的log file中進行持久化對於每一個topic 裡的訊息log檔案,Kafka都會對其進行分片處理,而每一個 訊息都會順序寫入中log分片中,並且被標上“offset”的標量來代表這條訊息在這個分片中的順序,並且這些寫入的訊息無論是內容還是順序都是不可變的。所以Kafka和其它訊息佇列系統的一個區別就是它能做到分片中的訊息是能順序被消費的,但是要做到全域性有序還是有侷限性的,除非整個topic只有一個log分片。並且無論訊息是否有被消費,這條訊息會一直儲存在log檔案中,當留存時間足夠長到配置檔案中指定的retention的時間後,這條訊息才會被刪除以釋放空間。對於每一個Kafka的Consumer,它們唯一要存的Kafka相關的元資料就是這個“offset”值,記錄著Consumer在分片上消費 到了哪一個位置。通常Kafka是使用Zookeeper來為每一個Consumer儲存它們的offset資訊,所以在啟動Kafka之前需要有一個Zookeeper叢集;而且Kafka預設採用的是先記錄offset再讀取資料的策略,這種策略會存在少量資料丟失的可能。不過使用者可以靈活設定Consumer的“offset”的位置,在加上訊息記錄在log檔案中,所以是可以重複消費訊息的。log的分片和它們的備份會分散儲存在叢集的伺服器上,對於每一個partition,在叢集上都會有一臺這個partition存在的伺服器作為leader,而這個partitionpartition的其它備份所在的伺服器做為follower,leader負責處理關於這個partition的所有請求,而follow er負責這個partition的其它備份的同步工作,當leader伺服器宕機時,其中一個follower伺服器就會被選舉為新的leader。
一般的訊息系統分為兩種模式,一種是點對點的消費模式,也就是queuing模式,另一種是釋出訂閱模式,也就是publish-subscribe模式,而Kafka引入了一個Consumer Group的概念,使得其能兼有兩種模式。在Kafka中,每一個consumer都會標明自己屬於哪個consumer group,每個topic的訊息都會分發給每一個subscribe了這個topic的所有consumer group中的一個consumer例項。所以當所有的consumers都在同一個consumer group中,那麼就像queuing的訊息系統,一個message一次只被一個consumer消費。如果每一個consumer都有不同consumer group,那麼就像public-subscribe訊息系統一樣,一個訊息分發給所有的consumer例項。對於普通的訊息佇列系統,可能存在多個consumer去同時消費message,雖然message是有序地分發出去的,但是由於網路延遲的時候到達不同的consumer的時間不是順序的,這時就失去了順序性,解決方案是隻用一個consumer去消費message,但顯然不太合適。而對於Kafka來說,一個partiton只分發給每一個consumer group中的一個consumer例項,也就是說這個partition只有一個consumer例項在消費,所以可以保證在一個partition內部資料的處理是有序的,不同之處就在於Kafka內部對訊息進行了分片處理,雖然看上去也是單consumer的做法,但是分片機制保證了併發消費。如果要做到全域性有序,那麼整個topic中的訊息只有一個分片,並且每一個consumer group中只能有一個consumer例項。這實際上就是徹底犧牲了訊息消費時的併發度。
Kafka的配置和部署十分簡單
1. 首先啟動Zookeeper叢集,Kafka需要Zookeeper叢集來幫助記錄每一個Consumer的offset
2. 為叢集上的每一臺Kafka伺服器單獨配置配置檔案,比如我們需要設定有兩個節點的Kafka叢集,那麼節點1和節點2的最基本的配置如下:
[plain] view plain copy
3. 配置完上面的配置檔案後,只要分別在節點上輸入下面命令啟動Kafka程序就可以使用了
Storm實時計算框架 接下來開始介紹本篇文章要使用的實時計算框架 Storm 。 Strom 是一個非常快的實時計算框架,至於快到什麼程度呢?官網首頁給出的資料是每一個 Storm 叢集上的節點每一秒能處理一百萬條資料。相比 Hadoop 的 “Mapreduce” 計算框架, Storm 使用的是 "Topology" ; Mapreduce 程式在計算完成後最終會停下來,而 Topology 則是會永遠執行下去除非你顯式地使用 “kill -9 XXX” 命令停掉它。和大多數的集群系統一樣, Storm 叢集也存在著 Master 節點和 Worker 節點,在 Master 節點上執行的一個守護程序叫 “Nimbus” ,類似於 Hadoop 的 “JobTracker” 的功能,負責叢集中計算程式的分發,任務的分發,監控任務和工作節點的執行情況等; Worker 節點上執行的守護程序叫 “Supervisor” ,負責接收 Nimbus 分發的任務並執行,每一個 Worker 上都會執行著 Topology 程式的一部分,而一個 Topology 程式的執行就是由叢集上多個 Worker 一起協同工作的。值得注意的是 Nimubs 和 Supervisor 之間的協調工作也是通過 Zookeeper 來管理的, Nimbus 和 Supervisor 自己本身在叢集上都是無狀態的,它們的狀態都儲存在 Zookeeper 上,所以任何節點的宕機和動態擴容都不會影響整個叢集的工作執行,並支援 fast-fail 機制。
Storm 有一個很重要的對資料的抽象概念,叫做 “Stream” ,我們姑且稱之為資料流,資料流 Stream 就是由之間沒有任何關係的鬆散的一個一個的資料元組 “tuples” 所組成的序列。要在 Storm 上做實時計算,首先你得有一個計算程式,這就是 “Topology” ,一個 Topology 程式由 “Spout” 和 “Bolt” 共同組成。 Storm 就是通過 Topology 程式將資料流 Stream 通過可靠 (ACK 機制 ) 的分散式計算生成我們的目標資料流 Stream ,就比如說把婚戀網站上當日註冊的所有使用者資訊資料流 Stream 通過 Topology 程式計算出月收入上萬年齡在 30 歲以下的新的使用者資訊流 Stream 。在我們的文章中, Spout 就是實現了特定介面的 Java 類,它相當於資料來源,用於產生資料或者從外部接收資料;而 Bolt 就是實現了 Storm Bolt 介面的 Java 類,用於消費從 Spout 傳送出來的資料流並實現使用者自定義的資料處理邏輯;對於複雜的資料處理,可以定義多個連續的 Bolt 去協同處理。最後在程式中通過 Spout 和 Bolt 生成 Topology 物件並提交到 Storm 叢集上執行。
tuples是Storm的資料模型,,由值和其所對應的field所組成,比如說在Spout或Bolt中定義了發出的元組的field為:(name,age,gender),那麼從這個Spout或Bolt中發出的資料流的每一個元組值就類似於(''咕嚕大大",27,"中性")。 在 Storm 中還有一個 Stream Group 的概念,它用來決定從 Spout 或或或 Bolt 元件中發出的 tuples 接下來應該傳到哪一個元件中或者更準確地說在程式裡設定某個元件應該接收來自哪一個元件的 tuples; 並且在 Storm 中提供了多個用於資料流分組的機制,比如說 shuffleGrouping ,用來將當前元件產生的 tuples 隨機分發到下一個元件中,或者 fieldsGrouping ,根據 tuples 的 field 值來決定當前元件產生的 tuples 應該分發到哪一個元件中。
另一部分需要了解的就是 Storm 中 tasks 和 workers 的概念。每一個 worker 都是一個執行在物理機器上的 JVM 程序,每個 worker 中又執行著多個 task 執行緒,這些 task 執行緒可能是 Spout 任務也可能是 Bolt 任務,由 Nimbus 根據 RoundRobin 負載均衡策略來分配,而至於在整個 Topology 程式裡要起幾個 Spout 執行緒或 Bolt 執行緒,也就是 <
文章的最後還有Troubleshooting,分享了作者在部署本文示例程式過程中所遇到的各種問題和解決方案。
系統基本架構
整個實時分析系統的架構就是先由電商系統的訂單伺服器產生訂單日誌, 然後使用Flume去監聽訂單日誌,並實時把每一條日誌資訊抓取下來並存進Kafka訊息系統中, 接著由Storm系統消費Kafka中的訊息,同時消費記錄由Zookeeper叢集管理,這樣即使Kafka宕機重啟後也能找到上次的消費記錄,接著從上次宕機點繼續從Kafka的Broker中進行消費。但是由於存在先消費後記錄日誌或者先記錄後消費的非原子操作,如果出現剛好消費完一條訊息並還沒將資訊記錄到Zookeeper的時候就宕機的類似問題,或多或少都會存在少量資料丟失或重複消費的問題, 其中一個解決方案就是Kafka的Broker和Zookeeper都部署在同一臺機子上。接下來就是使用使用者定義好的Storm Topology去進行日誌資訊的分析並輸出到Redis快取資料庫中(也可以進行持久化),最後用Web APP去讀取Redis中分析後的訂單資訊並展示給使用者。之所以在Flume和Storm中間加入一層Kafka訊息系統,就是因為在高併發的條件下, 訂單日誌的資料會井噴式增長,如果Storm的消費速度(Storm的實時計算能力那是最快之一,但是也有例外, 而且據說現在Twitter的開源實時計算框架Heron比Storm還要快)慢於日誌的產生速度,加上Flume自身的侷限性,必然會導致大量資料滯後並丟失,所以加了Kafka訊息系統作為資料緩衝區,而且Kafka是基於log File的訊息系統,也就是說訊息能夠持久化在硬碟中,再加上其充分利用Linux的I/O特性,提供了可觀的吞吐量。架構中使用Redis作為資料庫也是因為在實時的環境下,Redis具有很高的讀寫速度。
業務背景
既然要分析訂單資料,那必然在訂單產生的時候要把訂單資訊記錄在日誌檔案中。本文中,作者通過使用log4j2,以及結合自己之前開發電商系統的經驗,寫了一個訂單日誌生成模擬器,程式碼如下,能幫助大家隨機產生訂單日誌。下面所展示的訂單日誌檔案格式和資料就是我們本文中的分析目標,本文的案例中用來分析所有商家的訂單總銷售額並找出銷售額錢20名的商家。
訂單資料格式:
orderNumber: XX | orderDate: XX | paymentNumber: XX | paymentDate: XX | merchantName: XX | sku: [ skuName: XX skuNum: XX skuCode: XX skuPrice: XX totalSkuPrice: XX;skuName: XX skuNum: XX skuCode: XX skuPrice: XX totalSkuPrice: XX;
訂單日誌生成程式:
使用log4j2將日誌資訊寫入檔案中,每小時滾動一次日誌檔案
[plain] view plain copy
- <?xml version="1.0" encoding="UTF-8"?>
- <Configuration status="INFO">
- <Appenders>
- <Console name="myConsole" target="SYSTEM_OUT">
- <PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss} [%t] %-5level %logger{36} - %msg%n"/>
- </Console>
- <RollingFile name="myFile" fileName="/Users/guludada/Desktop/logs/app.log"
- filePattern="/Users/guludada/Desktop/logs/app-%d{yyyy-MM-dd-HH}.log">
- <PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss} [%t] %-5level %logger{36} - %msg%n"/>
- <Policies>
- <TimeBasedTriggeringPolicy />
- </Policies>
- </RollingFile>
- </Appenders>
- <Loggers>
- <Root level="Info">
- <AppenderRef ref="myConsole"/>
- <AppenderRef ref="myFile"/>
- </Root>
- </Loggers>
- </Configuration>
[plain] view plain copy
- package com.guludada.ordersInfo;
- import java.text.SimpleDateFormat;
- import java.util.Date;
- import java.util.Random;
- // Import log4j classes.
- import org.apache.logging.log4j.LogManager;
- import org.apache.logging.log4j.Logger;
- public class ordersInfoGenerator {
- public enum paymentWays {
- Wechat,Alipay,Paypal
- }
- public enum merchantNames {
- 優衣庫,天貓,淘寶,咕嚕大大,快樂寶貝,守望先峰,哈毒婦,Storm,Oracle,Java,CSDN,跑男,路易斯威登,
- 暴雪公司,Apple,Sumsam,Nissan,Benz,BMW,Maserati
- }
- public enum productNames {
- 黑色連衣裙, 灰色連衣裙, 棕色襯衫, 性感牛仔褲, 圓腳牛仔褲,塑身牛仔褲, 朋克衛衣,高腰闊腿休閒褲,人字拖鞋,
- 沙灘拖鞋
- }
- float[] skuPriceGroup = {299,399,699,899,1000,2000};
- float[] discountGroup = {10,20,50,100};
- float totalPrice = 0;
- float discount = 0;
- float paymentPrice = 0;
- private static final Logger logger = LogManager.getLogger(ordersInfoGenerator.class);
- private int logsNumber = 1000;
- public void generate() {
- for(int i = 0; i <= logsNumber; i++) {
- logger.info(randomOrderInfo());
- }
- }
- public String randomOrderInfo() {
- SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
- Date date = new Date();
- String orderNumber = randomNumbers(5) + date.getTime();
- String orderDate = sdf.format(date);
- String paymentNumber = randomPaymentWays() + "-" + randomNumbers(8);
- String paymentDate = sdf.format(date);
- String merchantName = randomMerchantNames();
- String skuInfo = randomSkus();
- String priceInfo = calculateOrderPrice();
- return "orderNumber: " + orderNumber + " | orderDate: " + orderDate + " | paymentNumber: " +
- paymentNumber + " | paymentDate: " + paymentDate + " | merchantName: " + merchantName +
- " | sku: " + skuInfo + " | price: " + priceInfo;
- }
- private String randomPaymentWays() {
- paymentWays[] paymentWayGroup = paymentWays.values();
- Random random = new Random();
- return paymentWayGroup[random.nextInt(paymentWayGroup.length)].name();
- }
- private String randomMerchantNames() {
- merchantNames[] merchantNameGroup = merchantNames.values();
- Random random = new Random();
- return merchantNameGroup[random.nextInt(merchantNameGroup.length)].name();
- }
- private String randomProductNames() {
- productNames[] productNameGroup = productNames.values();
- Random random = new Random();
- return productNameGroup[random.nextInt(productNameGroup.length)].name();
- }
- private String randomSkus() {
- Random random = new Random();
- int skuCategoryNum = random.nextInt(3);
- String skuInfo ="[";
- totalPrice = 0;
- for(int i = 1; i <= 3; i++) {
- int skuNum = random.nextInt(3)+1;
- float skuPrice = skuPriceGroup[random.nextInt(skuPriceGroup.length)];
- float totalSkuPrice = skuPrice * skuNum;
- String skuName = randomProductNames();
- String skuCode = randomCharactersAndNumbers(10);
- skuInfo += " skuName: " + skuName + " skuNum: " + skuNum + " skuCode: " + skuCode
- + " skuPrice: " + skuPrice + " totalSkuPrice: " + totalSkuPrice + ";";
- totalPrice += totalSkuPrice;
- }
- skuInfo += " ]";
- return skuInfo;
- }
- private String calculateOrderPrice() {
- Random random = new Random();
- discount = discountGroup[random.nextInt(discountGroup.length)];
- paymentPrice = totalPrice - discount;
- String priceInfo = "[ totalPrice: " + totalPrice + " discount: " + discount + " paymentPrice: " + paymentPrice +" ]";
- return priceInfo;
- }
- private String randomCharactersAndNumbers(int length) {
- String characters = "abcdefghijklmnopqrstuvwxyz0123456789";
- String randomCharacters = "";
- Random random = new Random();
- for (int i = 0; i < length; i++) {
- randomCharacters += characters.charAt(random.nextInt(characters.length()));
- }
- return randomCharacters;
- }
- private String randomNumbers(int length) {
- String characters = "0123456789";
- String randomNumbers = "";
- Random random = new Random();
- for (int i = 0; i < length; i++) {
- randomNumbers += characters.charAt(random.nextInt(characters.length()));
- }
- return randomNumbers;
- }
- public static void main(String[] args) {
- ordersInfoGenerator generator = new ordersInfoGenerator();
- generator.generate();
- }
- }
收集日誌資料
採集資料的方式有多種,一種是通過自己編寫shell指令碼或Java程式設計採集資料,但是工作量大,不方便維護,另一種就是直接使用第三方框架去進行日誌的採集,一般第三方框架的健壯性,容錯性和易用性都做得很好也易於維護。本文采用第三方框架Flume進行日誌採集,Flume是一個分散式的高效的日誌採集系統,它能把分佈在不同伺服器上的海量日誌檔案資料統一收集到一個集中的儲存資源中,Flume是Apache的一個頂級專案,與Kafka也有很好的相容性。不過需要注意的是Flume並不是一個高可用的框架,這方面的優化得使用者自己去維護。
Flume的agent是執行在JVM上的,所以各個伺服器上的JVM環境必不可少。每一個Flume agent部署在一臺服務器上,Flume會收集web server產生的日誌資料,並封裝成一個個的事件傳送給Flume Agent的Source,Flume Agent Source會消費這些收集來的資料事件(Flume Event)並放在Flume Agent Channel,Flume Agent Sink會從Channel中收集這些採集過來的資料,要麼儲存在本地的檔案系統中要麼作為一個消費資源分給下一個裝在分散式系統中其它伺服器上的Flume Agent進行處理。Flume提供了點對點的高可用的保障,某個伺服器上的Flume Agent Channel中的資料只有確保傳輸到了另一個伺服器上的Flume Agent Channel裡或者正確儲存到了本地的檔案儲存系統中,才會被移除。
在本文中,Flume的Source我們選擇的是Exec Source,因為是實時系統,直接通過tail 命令來監聽日誌檔案,而在Kafka的Broker叢集端的Flume我們選擇Kafka Sink 來把資料下沉到Kafka訊息系統中。
下圖是來自Flume官網裡的Flume拉取資料的架構圖:
圖片來源:http://flume.apache.org/FlumeUserGuide.html
訂單日誌產生端的Flume配置檔案如下:
[plain] view plain copy
- agent.sources = origin
- agent.channels = memorychannel
- agent.sinks = target
- agent.sources.origin.type = exec
- agent.sources.origin.command = tail -F /export/data/trivial/app.log
- agent.sources.origin.channels = memorychannel
- agent.sources.origin.interceptors = i1
- agent.sources.origin.interceptors.i1.type = static
- agent.sources.origin.interceptors.i1.key = topic
- agent.sources.origin.interceptors.i1.value = ordersInfo
- agent.sinks.loggerSink.type = logger
- agent.sinks.loggerSink.channel = memorychannel
- agent.channels.memorychannel.type = memory
- agent.channels.memorychannel.capacity = 10000
- agent.sinks.target.type = avro
- agent.sinks.target.channel = memorychannel
- agent.sinks.target.hostname = 172.16.124.130
- agent.sinks.target.port = 4545
Kafka 訊息系統端Flume配置檔案
[plain] view plain copy
- agent.sources = origin
- agent.channels = memorychannel
- agent.sinks = target
- agent.sources.origin.type = avro
- agent.sources.origin.channels = memorychannel
- agent.sources.origin.bind = 0.0.0.0
- agent.sources.origin.port = 4545
- agent.sinks.loggerSink.type = logger
- agent.sinks.loggerSink.channel = memorychannel
- agent.channels.memorychannel.type = memory
- agent.channels.memorychannel.capacity = 5000000
- agent.channels.memorychannel.transactionCapacity = 1000000
- agent.sinks.target.type = org.apache.flume.sink.kafka.KafkaSink
- #agent.sinks.target.topic = bigdata
- agent.sinks.target.brokerList=localhost:9092
- agent.sinks.target.requiredAcks=1
- agent.sinks.target.batchSize=100
- agent.sinks.target.channel = memorychannel
這裡需要注意的是,在日誌伺服器端的Flume agent中我們配置了一個interceptors,這個是用來為Flume Event(Flume Event就是拉取到的一行行的日誌資訊)的頭部新增key為“topic”的K-V鍵值對,這樣這條抓取到的日誌資訊就會根據topic的值去到Kafka中指定的topic訊息池中,當然還可以為Flume Event額外配置一個key為“Key”的鍵值對,Kafka Sink會根據key“Key”的值將這條日誌資訊下沉到不同的Kafka分片上,否則就是隨機分配。在Kafka叢集端的Flume配置裡,有幾個重要的引數需要注意,“topic”是指定抓取到的日誌資訊下沉到Kafka哪一個topic池中,如果之前Flume傳送端為Flume Event添加了帶有topic的頭資訊,則這裡可以不用配置;brokerList就是配置Kafka叢集的主機地址和埠;requireAcks=1是配置當下沉到Kafka的訊息儲存到特定partition的leader中成功後就返回確認訊息,requireAcks=0是不需要確認訊息成功寫入Kafka中,requireAcks=-1是指不光需要確認訊息被寫入partition的leander中,還要確認完成該條訊息的所有備份;batchSize配置每次下沉多少條訊息,每次下沉的數量越多延遲也高。
Kafka訊息系統
這一部分我們將談談Kafka的配置和使用,Kafka在我們的系統中實際上就相當於起到一個數據緩衝池的作用, 有點類似於ActiveQ的訊息佇列和Redis這樣的快取區的作用,但是更可靠,因為是基於log File的訊息系統,資料不容易丟失,以及能記錄資料的消費位置並且使用者還可以自定義訊息消費的起始位置,這就使得重複消費訊息也可以得以實現,而且同時具有佇列和釋出訂閱兩種訊息消費模式,十分靈活,並且與Storm的契合度很高,充分利用Linux系統的I/O提高讀寫速度等等。另一個要提的方面就是Kafka的Consumer是pull-based模型的,而Flume是push-based模型。push-based模型是儘可能大的消費資料,但是當生產者速度大於消費者時資料會被覆蓋。而pull-based模型可以緩解這個壓力,消費速度可以慢於生產速度,有空餘時再拉取那些沒拉取到的資料。
Kafka是一個分散式的高吞吐量的訊息系統,同時兼有點對點和釋出訂閱兩種訊息消費模式。Kafka主要由Producer,Consumer和Broker組成。Kafka中引入了一個叫“topic”的概念,用來管理不同種類的訊息,不同類別的訊息會記錄在到其對應的topic池中,而這些進入到topic中的訊息會被Kafka寫入磁碟的log檔案中進行持久化處理。Kafka會把訊息寫入磁碟的log file中進行持久化對於每一個topic 裡的訊息log檔案,Kafka都會對其進行分片處理,而每一個 訊息都會順序寫入中log分片中,並且被標上“offset”的標量來代表這條訊息在這個分片中的順序,並且這些寫入的訊息無論是內容還是順序都是不可變的。所以Kafka和其它訊息佇列系統的一個區別就是它能做到分片中的訊息是能順序被消費的,但是要做到全域性有序還是有侷限性的,除非整個topic只有一個log分片。並且無論訊息是否有被消費,這條訊息會一直儲存在log檔案中,當留存時間足夠長到配置檔案中指定的retention的時間後,這條訊息才會被刪除以釋放空間。對於每一個Kafka的Consumer,它們唯一要存的Kafka相關的元資料就是這個“offset”值,記錄著Consumer在分片上消費 到了哪一個位置。通常Kafka是使用Zookeeper來為每一個Consumer儲存它們的offset資訊,所以在啟動Kafka之前需要有一個Zookeeper叢集;而且Kafka預設採用的是先記錄offset再讀取資料的策略,這種策略會存在少量資料丟失的可能。不過使用者可以靈活設定Consumer的“offset”的位置,在加上訊息記錄在log檔案中,所以是可以重複消費訊息的。log的分片和它們的備份會分散儲存在叢集的伺服器上,對於每一個partition,在叢集上都會有一臺這個partition存在的伺服器作為leader,而這個partitionpartition的其它備份所在的伺服器做為follower,leader負責處理關於這個partition的所有請求,而follow er負責這個partition的其它備份的同步工作,當leader伺服器宕機時,其中一個follower伺服器就會被選舉為新的leader。
一般的訊息系統分為兩種模式,一種是點對點的消費模式,也就是queuing模式,另一種是釋出訂閱模式,也就是publish-subscribe模式,而Kafka引入了一個Consumer Group的概念,使得其能兼有兩種模式。在Kafka中,每一個consumer都會標明自己屬於哪個consumer group,每個topic的訊息都會分發給每一個subscribe了這個topic的所有consumer group中的一個consumer例項。所以當所有的consumers都在同一個consumer group中,那麼就像queuing的訊息系統,一個message一次只被一個consumer消費。如果每一個consumer都有不同consumer group,那麼就像public-subscribe訊息系統一樣,一個訊息分發給所有的consumer例項。對於普通的訊息佇列系統,可能存在多個consumer去同時消費message,雖然message是有序地分發出去的,但是由於網路延遲的時候到達不同的consumer的時間不是順序的,這時就失去了順序性,解決方案是隻用一個consumer去消費message,但顯然不太合適。而對於Kafka來說,一個partiton只分發給每一個consumer group中的一個consumer例項,也就是說這個partition只有一個consumer例項在消費,所以可以保證在一個partition內部資料的處理是有序的,不同之處就在於Kafka內部對訊息進行了分片處理,雖然看上去也是單consumer的做法,但是分片機制保證了併發消費。如果要做到全域性有序,那麼整個topic中的訊息只有一個分片,並且每一個consumer group中只能有一個consumer例項。這實際上就是徹底犧牲了訊息消費時的併發度。
Kafka的配置和部署十分簡單
1. 首先啟動Zookeeper叢集,Kafka需要Zookeeper叢集來幫助記錄每一個Consumer的offset
2. 為叢集上的每一臺Kafka伺服器單獨配置配置檔案,比如我們需要設定有兩個節點的Kafka叢集,那麼節點1和節點2的最基本的配置如下:
[plain] view plain copy
- config/server-1.properties:
- broker.id=1
- listeners=PLAINTEXT://:9093
- log.dir=export/data/kafka
- zookeeper.connect=localhost:2181
- config/server-2.properties:
- broker.id=2
- listeners=PLAINTEXT://:9093
- log.dir=/export/data/kafka
- zookeeper.connect=localhost:2181
3. 配置完上面的配置檔案後,只要分別在節點上輸入下面命令啟動Kafka程序就可以使用了
> bin/kafka-server-start.sh config/server-1.properties & ... > bin/kafka-server-start.sh config/server-2.properties & ...
Storm實時計算框架 接下來開始介紹本篇文章要使用的實時計算框架 Storm 。 Strom 是一個非常快的實時計算框架,至於快到什麼程度呢?官網首頁給出的資料是每一個 Storm 叢集上的節點每一秒能處理一百萬條資料。相比 Hadoop 的 “Mapreduce” 計算框架, Storm 使用的是 "Topology" ; Mapreduce 程式在計算完成後最終會停下來,而 Topology 則是會永遠執行下去除非你顯式地使用 “kill -9 XXX” 命令停掉它。和大多數的集群系統一樣, Storm 叢集也存在著 Master 節點和 Worker 節點,在 Master 節點上執行的一個守護程序叫 “Nimbus” ,類似於 Hadoop 的 “JobTracker” 的功能,負責叢集中計算程式的分發,任務的分發,監控任務和工作節點的執行情況等; Worker 節點上執行的守護程序叫 “Supervisor” ,負責接收 Nimbus 分發的任務並執行,每一個 Worker 上都會執行著 Topology 程式的一部分,而一個 Topology 程式的執行就是由叢集上多個 Worker 一起協同工作的。值得注意的是 Nimubs 和 Supervisor 之間的協調工作也是通過 Zookeeper 來管理的, Nimbus 和 Supervisor 自己本身在叢集上都是無狀態的,它們的狀態都儲存在 Zookeeper 上,所以任何節點的宕機和動態擴容都不會影響整個叢集的工作執行,並支援 fast-fail 機制。
Storm 有一個很重要的對資料的抽象概念,叫做 “Stream” ,我們姑且稱之為資料流,資料流 Stream 就是由之間沒有任何關係的鬆散的一個一個的資料元組 “tuples” 所組成的序列。要在 Storm 上做實時計算,首先你得有一個計算程式,這就是 “Topology” ,一個 Topology 程式由 “Spout” 和 “Bolt” 共同組成。 Storm 就是通過 Topology 程式將資料流 Stream 通過可靠 (ACK 機制 ) 的分散式計算生成我們的目標資料流 Stream ,就比如說把婚戀網站上當日註冊的所有使用者資訊資料流 Stream 通過 Topology 程式計算出月收入上萬年齡在 30 歲以下的新的使用者資訊流 Stream 。在我們的文章中, Spout 就是實現了特定介面的 Java 類,它相當於資料來源,用於產生資料或者從外部接收資料;而 Bolt 就是實現了 Storm Bolt 介面的 Java 類,用於消費從 Spout 傳送出來的資料流並實現使用者自定義的資料處理邏輯;對於複雜的資料處理,可以定義多個連續的 Bolt 去協同處理。最後在程式中通過 Spout 和 Bolt 生成 Topology 物件並提交到 Storm 叢集上執行。
tuples是Storm的資料模型,,由值和其所對應的field所組成,比如說在Spout或Bolt中定義了發出的元組的field為:(name,age,gender),那麼從這個Spout或Bolt中發出的資料流的每一個元組值就類似於(''咕嚕大大",27,"中性")。 在 Storm 中還有一個 Stream Group 的概念,它用來決定從 Spout 或或或 Bolt 元件中發出的 tuples 接下來應該傳到哪一個元件中或者更準確地說在程式裡設定某個元件應該接收來自哪一個元件的 tuples; 並且在 Storm 中提供了多個用於資料流分組的機制,比如說 shuffleGrouping ,用來將當前元件產生的 tuples 隨機分發到下一個元件中,或者 fieldsGrouping ,根據 tuples 的 field 值來決定當前元件產生的 tuples 應該分發到哪一個元件中。
另一部分需要了解的就是 Storm 中 tasks 和 workers 的概念。每一個 worker 都是一個執行在物理機器上的 JVM 程序,每個 worker 中又執行著多個 task 執行緒,這些 task 執行緒可能是 Spout 任務也可能是 Bolt 任務,由 Nimbus 根據 RoundRobin 負載均衡策略來分配,而至於在整個 Topology 程式裡要起幾個 Spout 執行緒或 Bolt 執行緒,也就是 <