
flume+kafka+storm整合實現實時計算小案例
阿新 • • 發佈:2019-02-01
我們做資料分析的時候常常會遇到這樣兩個場景,一個是統計歷史資料,這個就是要分析歷史儲存的日誌。我們會使用hadoop,具體框架可以設計為:
1.flume收集日誌;
2.HDFS輸入路徑儲存日誌;
3.MapReduce計算,將結果輸出到HDFS輸出路徑;
4.hive+sqoop實現將結果轉儲到mysql
5.我們會使用crontab定時執行一個指令碼來做
使用flume採集日誌資料,flume是一個分散式、可靠和高可用的海量日誌採集、聚合和傳輸的系統。它的核心是一個agent,其中包含3個元件,source、channel和sink。Agent會監控日誌目錄,通過source元件將日誌蒐集到channel中快取起來,當sink處理完之後會將快取的記錄刪除,已經掃描過的檔案會新增.COMPLETED字尾,下次不會重新掃描該檔案。 
將他們上傳到storm目錄下,執行 nohup bin/storm jar Storm_DailyStatisticsAnalysis.jar com.wyd.kafkastorm.DailyStatisticsAnalysisTopology &
1.flume收集日誌;
2.HDFS輸入路徑儲存日誌;
3.MapReduce計算,將結果輸出到HDFS輸出路徑;
4.hive+sqoop實現將結果轉儲到mysql
5.我們會使用crontab定時執行一個指令碼來做
具體這裡就不展開來說了,我會在另一個帖子講到。這裡我們詳細介紹第二個場景:實時計算。這個用的比較多的如天貓雙十一實時展示交易額,還有比如說銀行等。
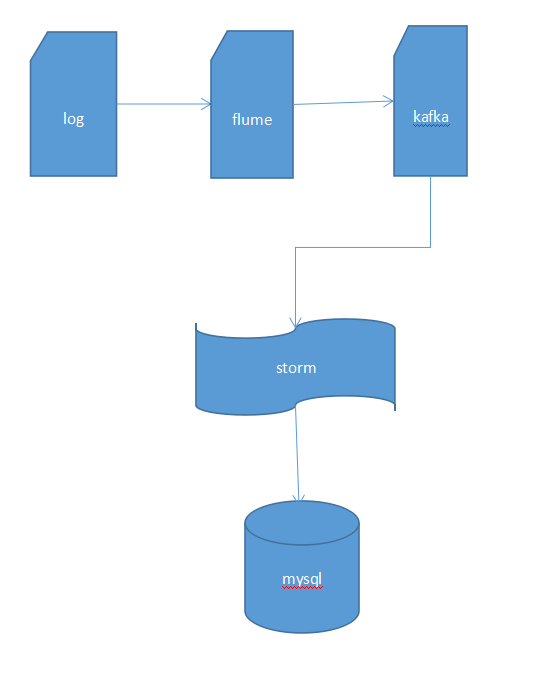
實現實時計算要用到storm或者spark等,這裡我介紹flume+kafka+storm方案。
使用flume採集日誌資料,flume是一個分散式、可靠和高可用的海量日誌採集、聚合和傳輸的系統。它的核心是一個agent,其中包含3個元件,source、channel和sink。Agent會監控日誌目錄,通過source元件將日誌蒐集到channel中快取起來,當sink處理完之後會將快取的記錄刪除,已經掃描過的檔案會新增.COMPLETED字尾,下次不會重新掃描該檔案。
將他們上傳到storm目錄下,執行 nohup bin/storm jar Storm_DailyStatisticsAnalysis.jar com.wyd.kafkastorm.DailyStatisticsAnalysisTopology &