
Elasticsearch初探(3)——簡單查詢與中文分詞
一、簡單查詢
1.1 查詢全部
請求方式: GET
請求路徑: ES服務的IP:埠/索引名/{分組,可省略}/_search
以上篇文章建立的索引為例,搜尋結果如下:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits" 預設情況下,是查詢出來10條資料,並且按照score的降序排列的(因為搜尋全部,這裡沒有score,當條件搜尋的時候,會出現)。其中部分屬性含義如下:
| 屬性 | 含義 |
|---|---|
| took | Elasticsearch執行搜尋的時間(ms) |
| timed_out | 請求是否超時 |
| _shards | 搜尋了碎片成功/失敗次數 |
| hits | 搜尋結果 |
| hits.total | 符合我們搜尋條件的檔案總數 |
| hits.hits | 實際的搜尋結果陣列 |
| hits.sort | 對結果進行排序的鍵(預設使用score排序時隱藏) |
| hits.hits._score與hits.max_score | 單個結果的匹配程度和最高的匹配程度 |
| hits.hits._source | 搜尋到的結果 |
1.2 單條件查詢
-
match:match查詢的時候,Elasticsearch會根據你給定的欄位提供合適的分析器,將查詢語句分詞之後去匹配含有分詞之後的詞語。 -
term:不進行分詞,直接完全匹配查詢。
需要注意的是:如果你搜索的欄位是keyword型別,那麼無論match和term都是一樣的,都不進行分詞(在上篇欄位資料型別中說過)。
//match進行查詢
GET user/novel/_search
{
"query": {
"match": {
"name": "jitwxs"
}
}
}
//term進行查詢
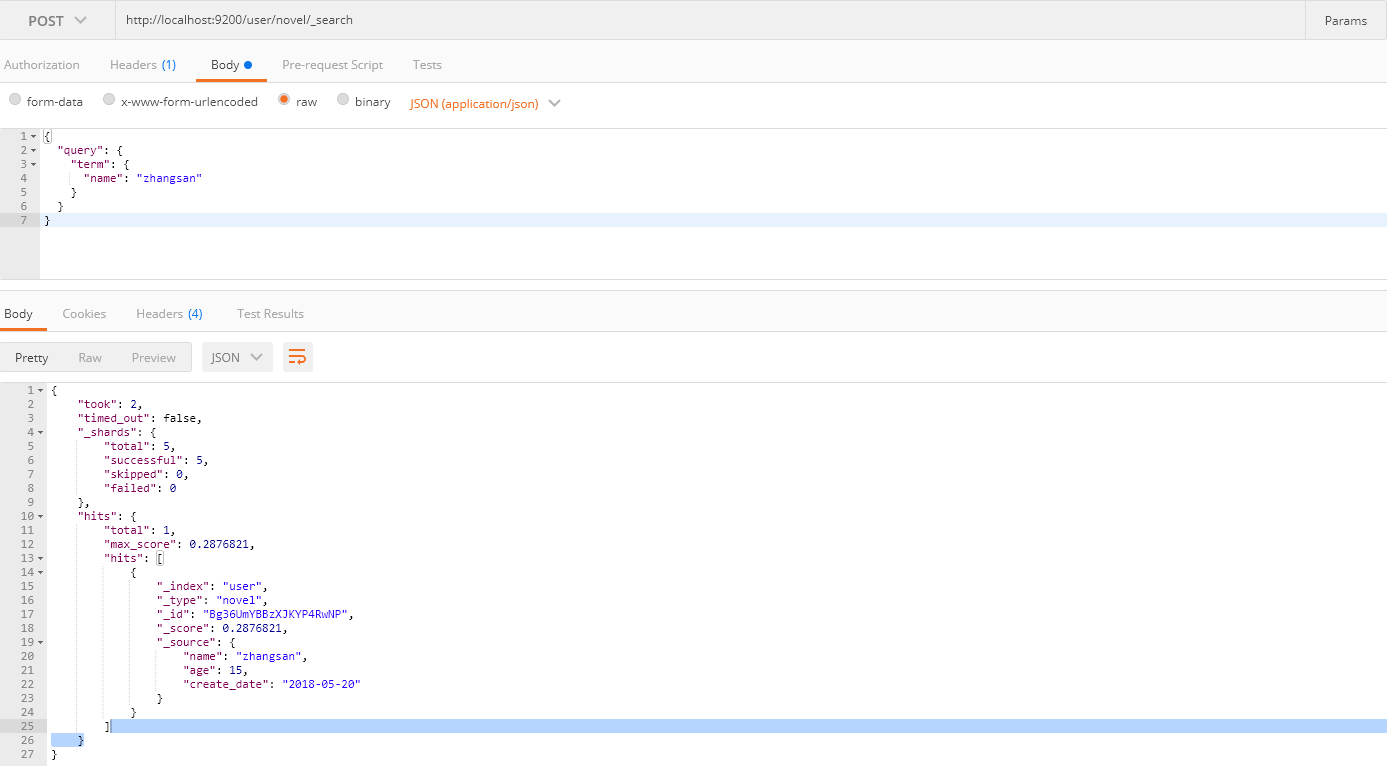
GET user/novel/_search
{
"query": {
"term": {
"name": "zhangsan"
}
}
}
你可能注意到我下面的截圖並沒有使用GET請求,這是因為我沒有找到Postman GET請求附帶請求體的方法,因此使用POST請求來查詢,當然官方推薦使用GET請求。如果你安裝有curl工具,可以使用這種方式請求:
curl 'localhost:9200/user/novel/_search' -d '{"query":{"match":{"name":"jitwxs"}}}'

1.3 多條件查詢
請求方式和單條件查詢一致,請求體形如:
{
"query": {
"bool": {
"must": {
"match": {
"email": "business opportunity"
}
},
"should": [{
"match": {
"starred": true
}
},
{
"bool": {
"must": {
"match": {
"folder": "inbox"
}
},
"must_not": {
"match": {
"spam": true
}
}
}
}
]
}
}
}
其中bool可以用來實現多條件查詢,bool包含的屬性如下:
| 屬性 | 含義 |
|---|---|
| must | 必須匹配的屬性,匹配這些條件才能被包含進來 |
| must_not | 不能匹配這些條件才能被包含進來 |
| should | 如果滿足這些語句中的任意語句,將增加 _score ,否則無任何影響。主要用於修正每個文件的相關性得分 |
| filter | 必須匹配,但它以不評分、過濾模式來進行。這些語句對評分沒有貢獻,只是根據過濾標準來排除或包含文件 |
1.4 排序、分頁
GET user/novel/_search
{
"query": {
"match": {
"name": "jitwxs"
}
},
"from": 0,
"size":10,
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
from表示分頁開始的條數(從0開始),size表示你要查詢的數量,sort表示排序的欄位,order表示排序方式。
二、中文分詞
2.1 下載IK分詞器
預設的分詞器對中文很差,這裡還是使用我們的老朋友——IK分詞器,到elasticsearch-analysis-ik下載與版本對應的IK分詞器。

解壓並將將檔案複製到Elasticsearch的安裝目錄/plugin/ik下面即可,完成之後效果如下:

重新啟動Elasticsearch服務。
以對“我是中國人”分詞為例,使用預設分詞結果:
POST http://localhost:9200/_analyze
{
"text":"我是中國人"
}
// 響應內容
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "中",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "國",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "人",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
}
]
}
IK分詞器結果:
POST http://localhost:9200/_analyze
{
"analyzer": "ik_max_word",
"text":"我是中國人"
}
// 響應內容
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中國人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "中國",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "國人",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}
對於上面兩個分詞效果的解釋:
-
如果未安裝IK分詞器,那麼,你如果寫 “analyzer”: “ik_max_word”,那麼程式就會報錯,因為你沒有安裝IK分詞器
-
如果你安裝了IK分詞器之後,你不指定分詞器,不加上 “analyzer”: “ik_max_word” 這句話,那麼其分詞效果跟你沒有安裝IK分詞器是一致的,也是分詞成每個漢字。
2.2 建立指定分詞器的索引
索引建立之後就可以使用IK進行分詞了,當你使用ES搜尋的時候也會使用ik對搜尋語句進行分詞,進行匹配。
下面給出一個例子以供參考:
PUT http://localhost:9200/book
{
"settings":{
"number_of_shards": "6",
"number_of_replicas": "1",
"analysis":{
"analyzer":{
"ik":{
"tokenizer":"ik_max_word"
}
}
}
},
"mappings":{
"novel":{
"properties":{
"author":{
"type":"text"
},
"wordCount":{
"type":"integer"
},
"publishDate":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss || yyyy-MM-dd"
},
"bookName":{
"type":"text"
}
}
}
}
}
關於IK分詞器的分詞型別(可以根據需求進行選擇):
-
ik_max_word:會將文字做最細粒度的拆分,比如會將“中華人民共和國國歌”拆分為“中華人民共和國,中華人民,中華,華人,人民共和國,人民,人,民,共和國,共和,和,國國,國歌”,會窮盡各種可能的組合; -
ik_smart:會做最粗粒度的拆分,比如會將“中華人民共和國國歌”拆分為“中華人民共和國,國歌”。