
8大排序之-----(3)選擇排序與時間複雜度
選擇排序與時間複雜度
(一)選擇排序的基本思想:選擇排序就是每一次從待排序的資料中選出最小的元素,放到已經排好序的資料的最後位 置,直到全部元素排好序。
(二)解析過程:比如現在待排序的資料是int s[] = {3,1,5,4,6,8,7,9,0,2}
第一趟,首先s[0]的位置的元素挖空,賦給temp;接著找出最小的元素s[index],放進s[0]的位置。再把temp賦給s[
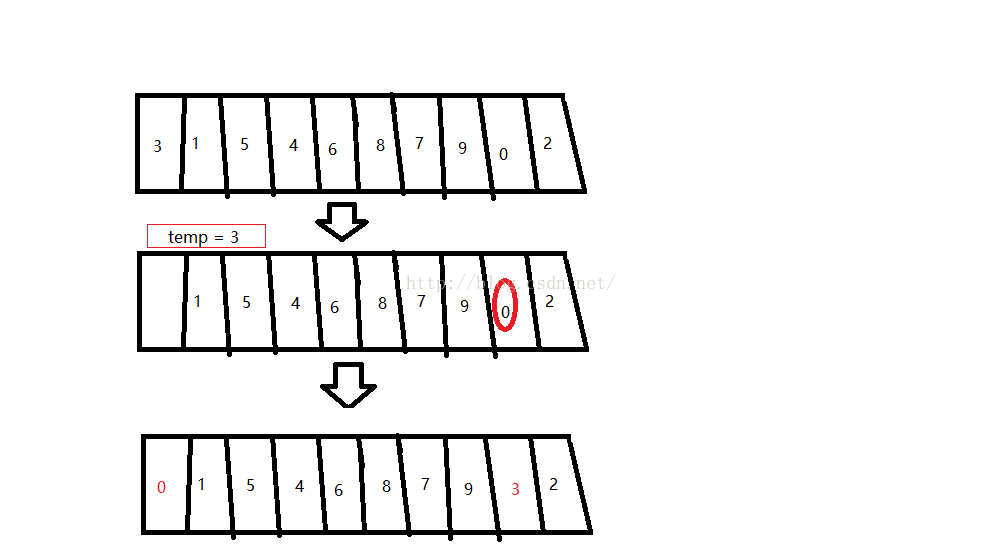
第二趟:把s[1]的位置的元素挖空,賦給temp;接著在剩餘元素(1,5,4,6,8,7,9,3,2)找出最小的元素s[index],放進s[1]的位置。再把temp賦給s[index]。
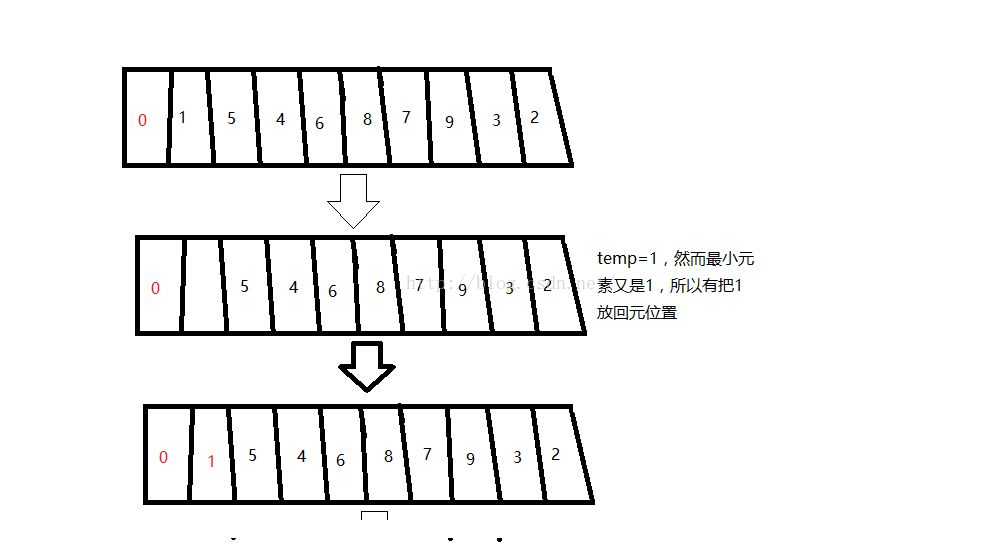
第三趟:把s[2]的位置的元素挖空,賦給temp;接著在剩餘元素(5,4,6,8,7,9,3,2)找出最小的元素s[index],放進s[2]的位置。再把temp賦給s[index]。
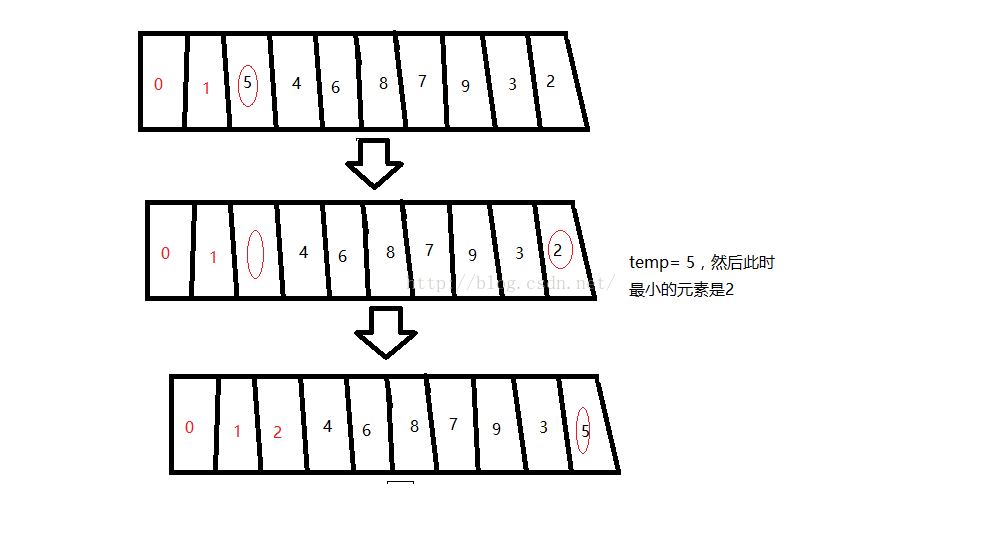
第3趟:把s[3]的位置的元素挖空,賦給temp;接著在剩餘元素(5,4,6,8,7,9,3)找出最小的元素s[index],放進s[2]的位置。再把temp賦給s[index]。
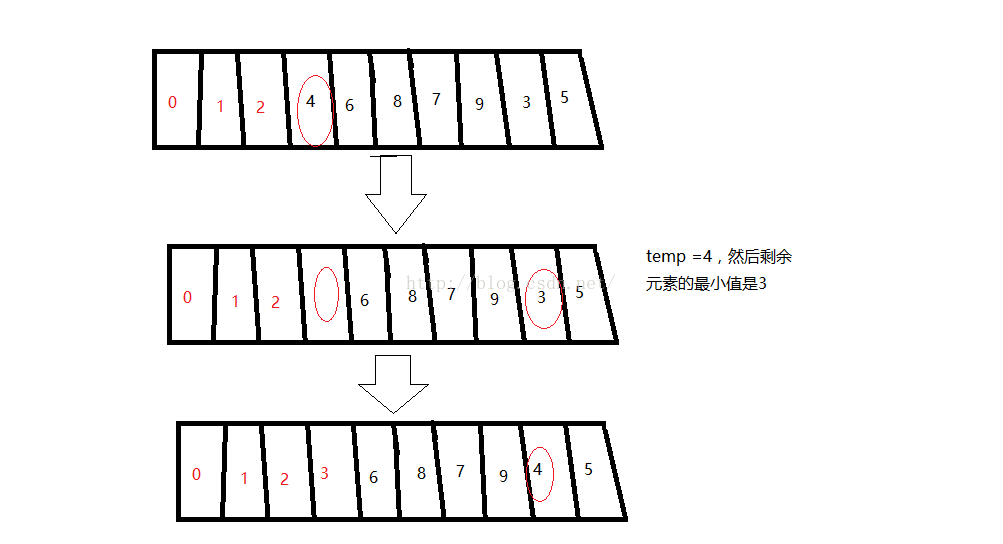
剩下的以此類推
(三)程式碼如下:
(四)時間複雜度分析:public class XuanZhe { public static void main(String args[]) { int a [] = {3,1,5,4,6,8,7,9,0,2}; xuanzhe(a); for(int m = 0;m < a.length;m++){ System.out.print(a[m]); } } public static void xuanzhe(int s[]){ int i; int j; int index;//用來存放找到的最小值的下標 int temp;//中間變數 for(i = 0;i < s.length-1; i++){ index = i;//先讓index和i相等,之後再通過比較找到最小的值,之後再把下標賦值給index /*通過這個迴圈找出後面所有數的最小值的下標 ,j=i+1,是第一個位於i後面的數,之後再j++,變為i後面的第二個數,第3個數.....*/ for(j = i + 1;j < s.length; j++){ if(s[index] > s[j]){ index = j;//小的數在s[j],所以把j賦給index,index就是小數值的下標,然後通過迴圈,就可以找到最小值的下標 } } temp = s[i]; s[i] = s[index]; s[index] = temp; } } }
簡單選擇排序的比較次數與序列的初始排序無關。 假設待排序的序列有 N 個元素,則比較次數總是N (N - 1) / 2。
而移動次數與序列的初始排序有關。當序列正序時,移動次數最少,為 0.
當序列反序時,移動次數最多,為3N (N - 1) / 2。
所以,綜合以上,簡單排序的時間複雜度為 O(N2)
相關推薦
8大排序之-----(3)選擇排序與時間複雜度
選擇排序與時間複雜度 (一)選擇排序的基本思想:選擇排序就是每一次從待排序的資料中選出最小的元素,放到已經排好序的資料的最後位
大資料之(3)Hadoop環境MapReduce程式驗證及hdfs常用命令
一、MapReduce驗證 本地建立一個test.txt檔案 vim test.txt 輸入一些英文句子如下: Beijing is the capital of China I love Beijing I love China 上傳test.txt
排序演算法之(二)選擇排序
原理: 每一次從待排序的資料元素中選出最小(或最大)的一個元素,存放在序列的起始位置,然後,再從剩餘未排序元素中繼續尋找最小(大)元素,然後放到已排序序列的末尾。以此類推,直到全部待排序的資料元素排完。 選擇排序是不穩定的排序方法。 思路: n個數進行n-1次排序 每一次排
java排序演算法(三)------選擇排序
選擇排序 基本思想:每一趟從待排序的資料元素中選擇最小(或最大)的一個元素作為首元素,直到所有元素排完為止,簡單選擇排序是不穩定排序。 選擇排序的時間複雜度和空間複雜度分別為 O(n2 ) 和 O(1) 程式碼實現: public static void s
java排序演算法(二)----選擇排序
選擇排序(Selection Sort) 選擇排序(Selection-sort)是一種簡單直觀的排序演算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然後,再從
排序演算法(六)——選擇排序
選擇排序(Selection sort)是一種簡單直觀的排序演算法。選擇排序的交換操作介於和次之間。選擇排序的比較操作為次。選擇排序的賦值操作介於和次之間。 運作方式如下: 1.首先從原始陣列中選擇最小的1個數據,將其和位於第1個位置的資料交換。 2.接著從剩下的n-1個數據中選擇次小的
八種排序方法(一)——選擇排序
編譯器:Xcode 程式語言:C++ 選擇排序的基本思想: 每一趟在n-i+1(i=1,2,3…,n-1)個記錄中選取關鍵字最小的記錄與第i個記錄交換,並作為有序序列中的第i個記錄。
排序演算法(一)選擇排序和氣泡排序
1. 選擇排序: 選擇排序是一種很簡單直觀的排序方法,就是在未排序的資料中挑選出最大或者最小的元素,存放到已排序資料的末尾。 簡單的講,就是每次都把最大或者最小的資料挑選出來,然後依次組成新的序列。 假設有資料{1,4,6,8,3,4,0,2,14},要按照從大到小進行
排序演算法(二)——選擇排序及改進
選擇排序 基本思想 氣泡排序中有一個缺點,比如,我們比較第一個數a1與第二個數a2的時候,只要a1比a2大就會交換位置,但是我們並不能確定a2是最小的元素,假如後面還有比它更小的,該元素還會與a2
8大排序之(五)------簡單理解 基數排序 與時間複雜度
什麼是基數排序? (一)基數排序的思想:把待排序的整數按位分,分為個位,十位.....從小到大依次將位數進行排序。實際上分為兩個 過程:分配和收集。
內部排序(3)——插入排序之折半插入排序
復雜 span oid pre 時間 查找 insert -1 順序 因為插入排序的基本思想是在一個有序序列中插入一個新的記錄,則能夠利用"折半查找"查詢插入位置,由此得到的插入排序算法為"折半插入排序"。算法例如以下: void BInsertSort () {
資料結構與演算法之排序(2)選擇排序 ——in dart
選擇排序的演算法複雜度與氣泡排序類似,其比較的時間複雜度仍然為O(N2),但減少了交換次數,交換的複雜度為O(N),相對氣泡排序提升很多。演算法的核心思想是每次選出一個最小的,然後與本輪迴圈中的第一個進行比較,如果需要則進行交換。 1 import 'dart:math' show Random
數據結構與算法之排序(2)選擇排序 ——in dart
排序 冒泡 next 時間復雜度 交換 imp print gen 循環 選擇排序的算法復雜度與冒泡排序類似,其比較的時間復雜度仍然為O(N2),但減少了交換次數,交換的復雜度為O(N),相對冒泡排序提升很多。算法的核心思想是每次選出一個最小的,然後與本輪循環中的第一個
八大排序演算法(3) 簡單選擇排序
基本思路 每次選出剩餘序列中最小/最大的數、與剩餘序列的第一個交換位置。 示例: // 升序,左起 /*初始值*/ 10, 7, 1, 8, 5, 12, 6, 3, 9 /*第1趟*
排序(五)選擇排序
單選 auto .com spl left 有關 img 時間復雜度 空間 參考文檔: 原理: 對於給定的一組記錄,經過第一輪比較後得到最小的記錄,然後將該記錄與第一個記錄的位置進行交換;接著對不包括第一個記錄以外的其他記錄進行第二輪比較,得到最小的記錄並與第二個記錄進
【算法】排序(一)選擇排序
如何 接下來 運行時 images 復雜度 分析 穩定性 stat ima 在排序算法中,最簡單的莫過於選擇排序了。 排序思路: 在選擇排序算法中分別有一個外循環和一個內循環,假設需要排序的序列共有n個元素,所以外循環的次數為n次,在n次交換(外循環)中,每次設置序列中的第
java算法----排序----(2)選擇排序
info arr ava osi package ram a算法 str oid 1 package log; 2 3 public class Test4 { 4 5 /** 6 * java算法---選擇排序 7 *
常用算法(二)選擇排序與冒泡排序
true .com sele mage ever 最終 不穩定排序 換來 ima 一、選擇排序 簡單選擇排序是最簡單直觀的一種算法,基本思想為每一趟從待排序的數據元素中選擇最小(或最大)的一個元素作為首元素,直到所有元素排完為止,簡單選擇排序是不穩定排序。 在算法實現時,每
小橙書閱讀指南(二)——選擇排序
sel alt 代碼示例 運行時間 mon cti override 和數 integer 算法描述:一種最簡單的排序算法是這樣的:首先,找到數組中最小的那個元素,其次,將它和數組的第一個元素交換位置。再次,再剩下的元素中找到最小的元素,將它與數組的第二個元素交換位置。如此
大資料入門(3)配置hadoop
1、上傳hadoop-2.4.1.tar.gz 2、解壓檔案到指定目錄(目錄:admin/app) mkdir app tar -zxvf hadoop-2.4.1.tar.gz -C /app 刪