
MySQL now()/sysdate()效率對比
今天優化sql,遇到一個查詢很慢的sql:
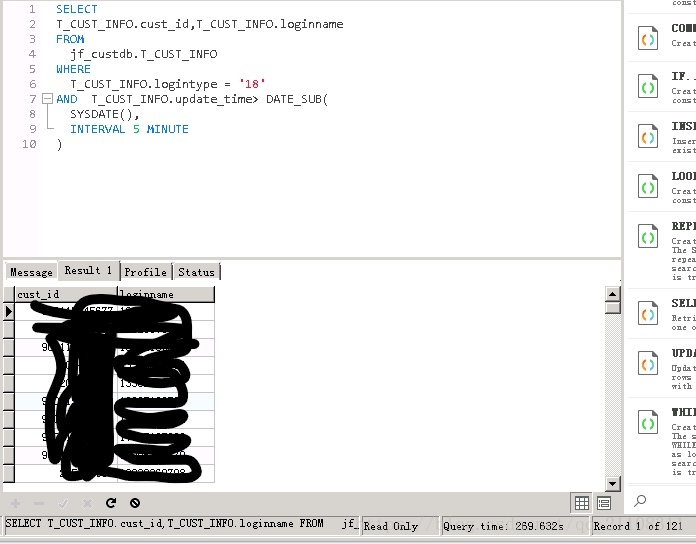
查詢時間花了接近5分鐘,檢視發現時間欄位都是有索引的,於是查看了下執行計劃
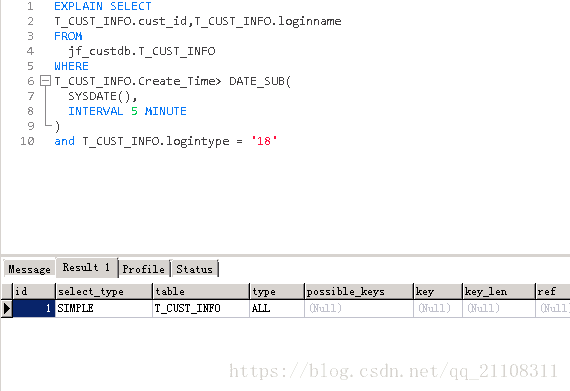
發現走的是全表掃描,一臉懵,明明有索引啊,為啥沒走。
查詢官方文件:

所以這裡看出,sysdate()不會走索引,於是改為now():
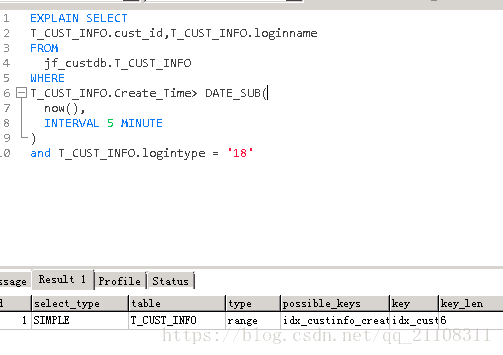
結果走了索引,秒級出現值,所以在MySQL取當前時間的時候,記得一定要用now。
相關推薦
MySQL now()/sysdate()效率對比
今天優化sql,遇到一個查詢很慢的sql: 查詢時間花了接近5分鐘,檢視發現時間欄位都是有索引的,於是查看了下執行計劃 發現走的是全表掃描,一臉懵,明明有索引啊,為啥沒走。 查詢官方文件: 所以這裡看出
mysql:distinct與group by 效率對比
在一個有10w條記錄的表中進行查詢, distict耗時: 0.078ms group by 耗時:0.031ms 給查詢的列新增索引之後: distict耗時: 0.00072550ms group by 耗時:0.00071650ms 所以不管咋滴,
mysql中in與exists的效能與效率對比
有一種說法,說exists效能比in要好,其實不全然。哪個效能更好,需要看具體的需求場景。1、如何選擇使用in 或者 exists?1)子表資料量比外表資料量少,使用in。2)子表資料量比外表資料量大
mysql union all與子查詢結合效率對比
SELECT * FROM baidu_day_2014_1 WHERE account = 'xxx' UNION ALL SELECT * FROM baidu_day_2014_2 WHERE account = 'xxx' UNION ALL SELECT *
『Python』MachineLearning機器學習入門_效率對比
cnblogs 新的 arange 學習 nump 部分 運行 orm blog 效率對比: 老生常談了,不過這次用了個新的模塊, 運行時間測試模塊timeti: 1 import timeit 2 3 normal = timeit.timeit(‘sum(x*
golang 浮點數 取精度的效率對比
浮點數 pre span now() 其他 shift pow 效率 log 需求 浮點數取2位精度輸出 實現 代碼 package main import ( "time" "log" "strconv" "fmt" )
AGG第三十四課 stroke_aa和outline_aa渲染線段效率對比
agg outline_aa stroke1 渲染代碼 void TestStrokeAAPerformance() { agg::rendering_buffer &rbuf = rbuf_window(); agg::pixfmt_bgr24 pixf(rbuf); typedef
MySQL引擎各個引擎對比介紹
不同類 wps windows 用途 環境 lba 逗號 擴展 .frm 1.什麽是存儲引擎? 存儲引擎類似於錄制的視頻文件,可以轉換成不同的格式,如MP4,avi等格式,而存儲在我們的磁盤上也會存在於不同類型的文件系統中如:Windows裏常見的NTFS,fa
字節流的三種操作方法效率對比
copyfile ndt 文件 流復制 share pri file input time public class IOStream { public static void main(String[] args) throws IOException {
Java字符串連接的多種實現方法及效率對比
nan style time net println 毫秒 修改 nbsp 多種實現 JDK 1.8(Java 8)裏新增String.join()方法用於字符串連接。本文基於《Java實現String.join()和效率比較》一文,分析和比較四種自定義實現與Str
Mysql 定位執行效率低的sql 語句
optimize 用處 pen 啟用 很快 空間 復制 man pac 一、通過MySQL慢查詢日誌定位執行效率低的SQL語句。 MySQL通過慢查詢日誌定位那些執行效率較低的SQL 語句,用--log-slow-queries[=file_name]選項啟動時,mysql
Java文件操作類效率對比
字符 name mem http .get space data args 內容 前言 眾所周知,Java中有多種針對文件的操作類,以面向字節流和字符流可分為兩大類,這裏以寫入為例: 面向字節流的:FileOutputStream 和 BufferedOutputStr
python列表處理效率對比測試
() ima 測試結果 結果 name com lis for cto Python列表添加元素效率測試 #!/usr/bin/env import datetime class adair: def test1(n): lst=[]
numpy數組及處理:效率對比
class etime 數組 for start 處理 .com import 圖片 def pySum(n): a = list(range(n)) b = list(range(0,3*n,3)) c = [] for i in ran
Matlab運算效率對比
首先,推薦一篇比較,分析了四種執行函式效率對比。 Ref:https://zhuanlan.zhihu.com/p/35808505?group_id=969873960783101952 結果:直接呼叫>匿名>feval>eval。但不是說就不用eval了,eval是個很靈活
【小家Java】Future、FutureTask、CompletionService、CompletableFuture解決多執行緒併發中歸集問題的效率對比
相關閱讀 【小家java】java5新特性(簡述十大新特性) 重要一躍 【小家java】java6新特性(簡述十大新特性) 雞肋升級 【小家java】java7新特性(簡述八大新特性) 不溫不火 【小家java】java8新特性(簡述十大新特性) 飽受讚譽 【小家java】java9
關於R與Python效率對比的問題
久聞世界上最慢的語言是Python, 比Python還要慢的語言是R 聽聞numpy是舉世聞名的高效科學計算庫? 來我們來看看100萬次迴圈後的結果... Python import numpy as np import matplotlib.pyplot as plt import
Python中遍歷pandas資料的幾種方法介紹和效率對比說明
前言 Pandas是python的一個數據分析包,提供了大量的快速便捷處理資料的函式和方法。其中Pandas定義了Series 和 DataFrame兩種資料型別,這使資料操作變得更簡單。Series 是一種一維的資料結構,類似於將列表資料值與索引值相結合。DataFrame 是一種二維
java中String字串拼接“+”和StringBuffer的效率對比
1、前言 (1)最近在做資料傳輸時,由於接收的資料量較大,在字串拼接時使用了以前感覺方便的“+”進行字串拼接,最後拼接到最後時間越來越多,導致效率變慢。 2、String拼接 首先來看一下兩個String用“+”號拼接需要的時間 String aa="E0 00 00 00 00
SqlServer的兩種插入方式效率對比
protected void button1_Click(object sender, EventArgs e) { &n