
【爬蟲初探】新浪微博搜尋爬蟲實現
全文概述
功能:爬取新浪微博的搜尋結果,支援高階搜尋中對搜尋時間的限定
網址:http://s.weibo.com/
實現:採取selenium測試工具,模擬微博登入,結合PhantomJS/Firefox,分析DOM節點後,採用Xpath對節點資訊進行獲取,實現重要資訊的抓取,並存儲至Excel中。
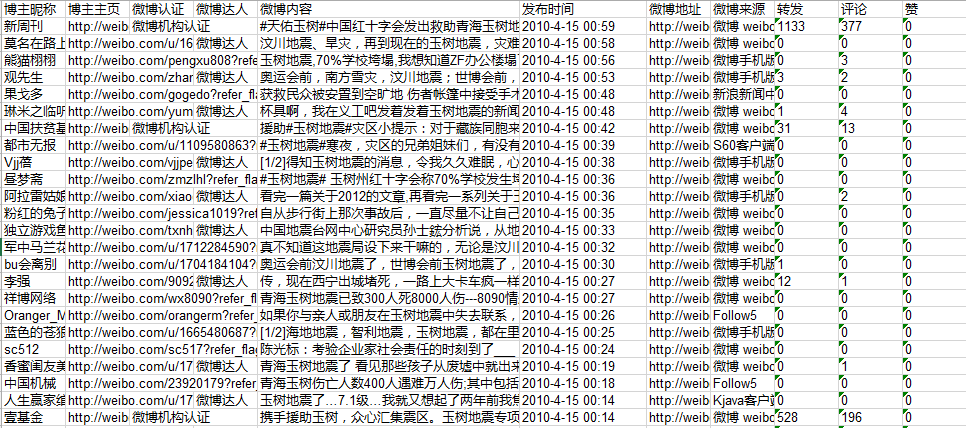
獲取的微博資訊包括:博主暱稱, 博主主頁, 微博認證, 微博達人, 微博內容, 釋出時間, 微博地址, 微博來源, 轉發, 評論, 贊
實現
一、微博登陸
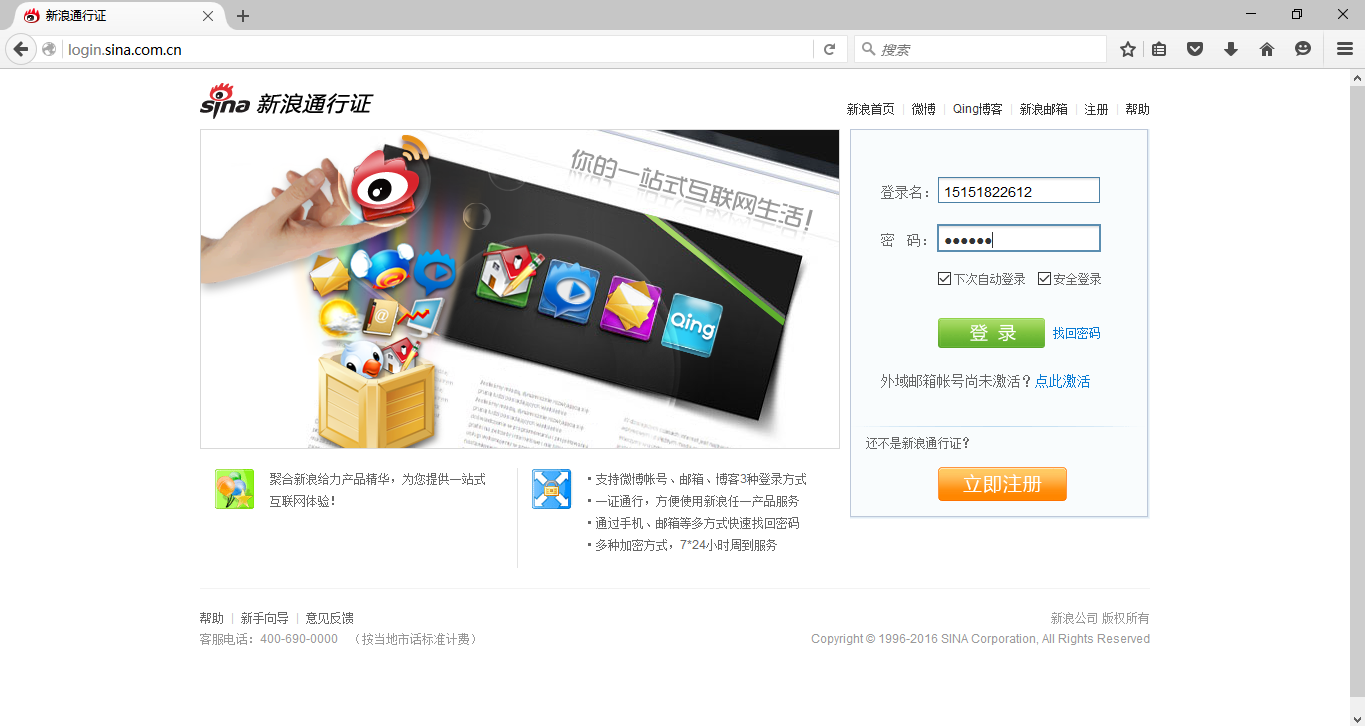
一般的微博模擬登陸向伺服器傳送cookies,但是selenium可以通過模擬點選實現登陸,登陸時需要輸入驗證碼。通過登陸新浪通行證(
driver = webdriver.Firefox()
def LoginWeibo(username, password):
try:
#輸入使用者名稱/密碼登入
print u'準備登陸Weibo.cn網站...'
driver.get("http://login.sina.com.cn/")
elem_user = driver.find_element_by_name("username")
elem_user.send_keys(username) #使用者名稱 注意:Firefox登陸時是否需要輸入驗證碼在不同機器上表現不一,譬如在我電腦上無需輸入驗證碼即可登入而在另一臺伺服器上需要輸入驗證碼。所以如果需要輸入驗證碼, 則只能通過Firefox實現,因為PhantomJS作為headless瀏覽器,無法實現輸入驗證碼的功能。
二、搜尋並處理結果
訪問http://s.weibo.com/頁面,輸入關鍵詞,點選搜尋後,限定搜尋的時間範圍,處理頁面的搜尋結果。
總體排程
搜尋的總排程程式如下:
def GetSearchContent(key):
driver.get("http://s.weibo.com/")
print '搜尋熱點主題:', key.decode('utf-8')
#輸入關鍵詞並點選搜尋
item_inp = driver.find_element_by_xpath("//input[@class='searchInp_form']")
item_inp.send_keys(key.decode('utf-8'))
item_inp.send_keys(Keys.RETURN) #採用點選回車直接搜尋
#獲取搜尋詞的URL,用於後期按時間查詢的URL拼接
current_url = driver.current_url
current_url = current_url.split('&')[0] #http://s.weibo.com/weibo/%25E7%258E%2589%25E6%25A0%2591%25E5%259C%25B0%25E9%259C%2587
global start_stamp
global page
#需要抓取的開始和結束日期
start_date = datetime.datetime(2010,4,13,0)
end_date = datetime.datetime(2010,4,26,0)
delta_date = datetime.timedelta(days=1)
#每次抓取一天的資料
start_stamp = start_date
end_stamp = start_date + delta_date
global outfile
global sheet
outfile = xlwt.Workbook(encoding = 'utf-8')
while end_stamp <= end_date:
page = 1
#每一天使用一個sheet儲存資料
sheet = outfile.add_sheet(str(start_stamp.strftime("%Y-%m-%d-%H")))
initXLS()
#通過構建URL實現每一天的查詢
url = current_url + '&typeall=1&suball=1×cope=custom:' + str(start_stamp.strftime("%Y-%m-%d-%H")) + ':' + str(end_stamp.strftime("%Y-%m-%d-%H")) + '&Refer=g'
driver.get(url)
handlePage() #處理當前頁面內容
start_stamp = end_stamp
end_stamp = end_stamp + delta_date構造搜尋時間
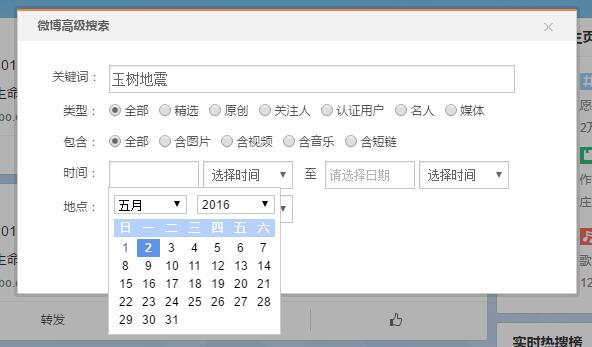
在搜尋時間的構造方面,實際上有高階搜尋-搜尋時間選擇按鈕可以進行搜尋時間的選擇。但是對所有的行為進行selenium點選模擬似乎有些太過複雜,而且在實現的過程中發現由於兩個日期的選擇公用一個calendar,不知是何原因導致截至日期選擇時會出錯。
單個頁面資料處理
每一個頁面載入完畢之後,需要經過一系列判斷,最終決定是否有內容可以獲取
#頁面載入完成後,對頁面內容進行處理
def handlePage():
while True:
#之前認為可能需要sleep等待頁面載入,後來發現程式執行會等待頁面載入完畢
#sleep的作用是對付微博的反爬蟲機制,抓取太快可能會判定為機器人,需要輸入驗證碼
time.sleep(2)
#先行判定是否有內容
if checkContent():
print "getContent"
getContent()
#先行判定是否有下一頁按鈕
if checkNext():
#拿到下一頁按鈕
next_page_btn = driver.find_element_by_xpath("//a[@class='page next S_txt1 S_line1']")
next_page_btn.click()
else:
print "no Next"
break
else:
print "no Content"
break頁面載入結果判斷
在這裡,點選搜尋按鈕之後的搜尋結果可能有以下幾種情況
1、頁面無搜尋結果
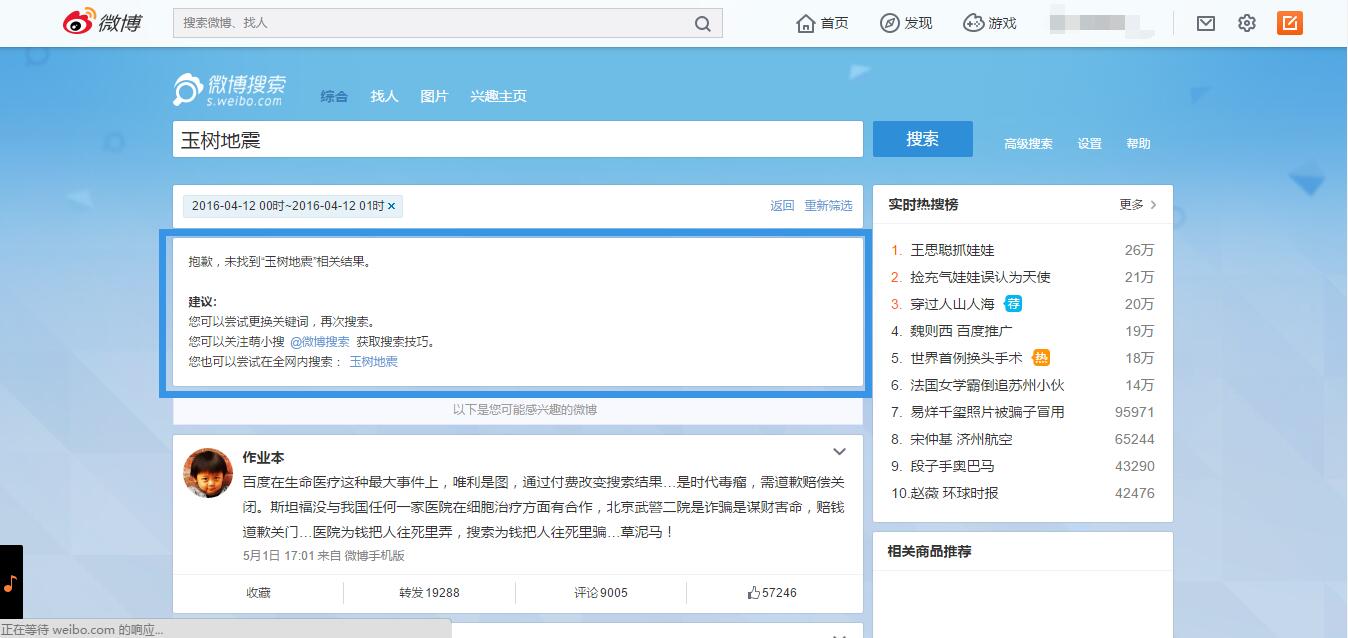
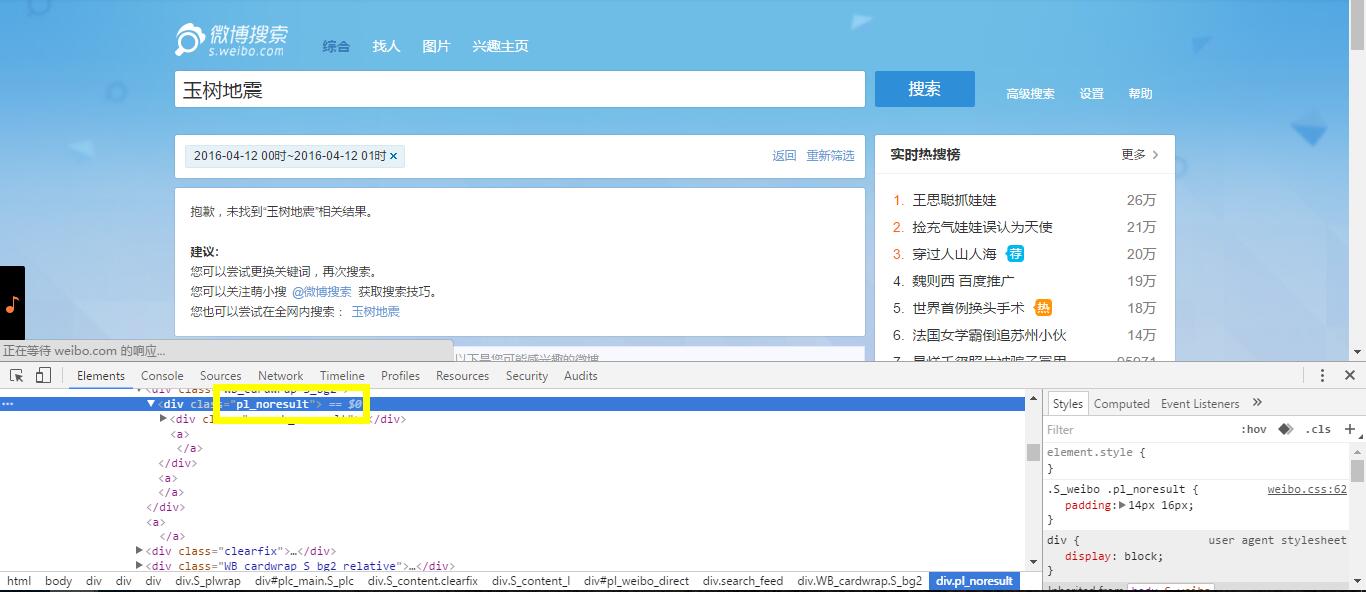
如圖中所示,如果在指定時間內,關鍵詞無搜尋結果(此時,頁面中會有推薦微博,推薦微博很容易被當作是正常微博)。通過與有搜尋結果的頁面比較,此類頁面最典型的特徵是擁有"class = pl_noresult"的div,可以通過Xpath查詢"//div[@class='pl_noresult']"的節點是否存在來判定有搜尋結果,具體判定如下:
#判斷頁面載入完成後是否有內容
def checkContent():
#有內容的前提是有“導航條”?錯!只有一頁內容的也沒有導航條
#但沒有內容的前提是有“pl_noresult”
try:
driver.find_element_by_xpath("//div[@class='pl_noresult']")
flag = False
except:
flag = True
return flag
2、頁面有搜尋結果,且只有一頁
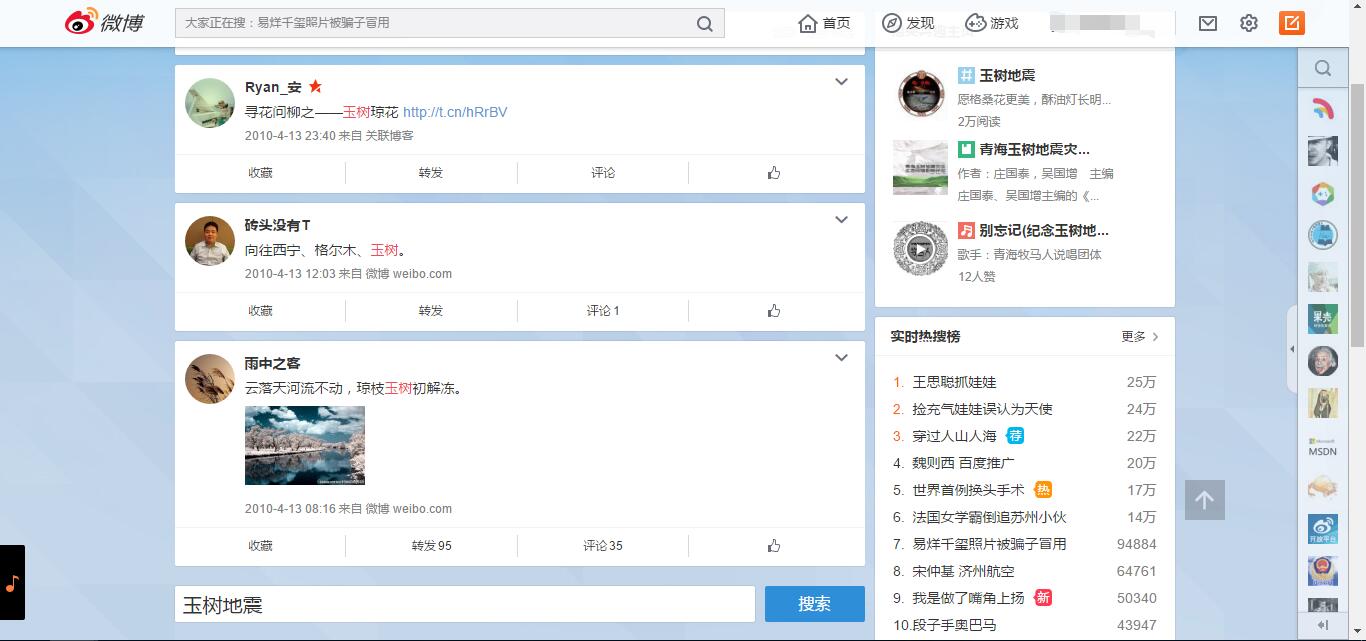
通過仔細分析,這樣的頁面最典型的特徵是沒有導航條,即沒有“下一頁”按鈕
3、頁面有搜尋結果,且有不止一頁
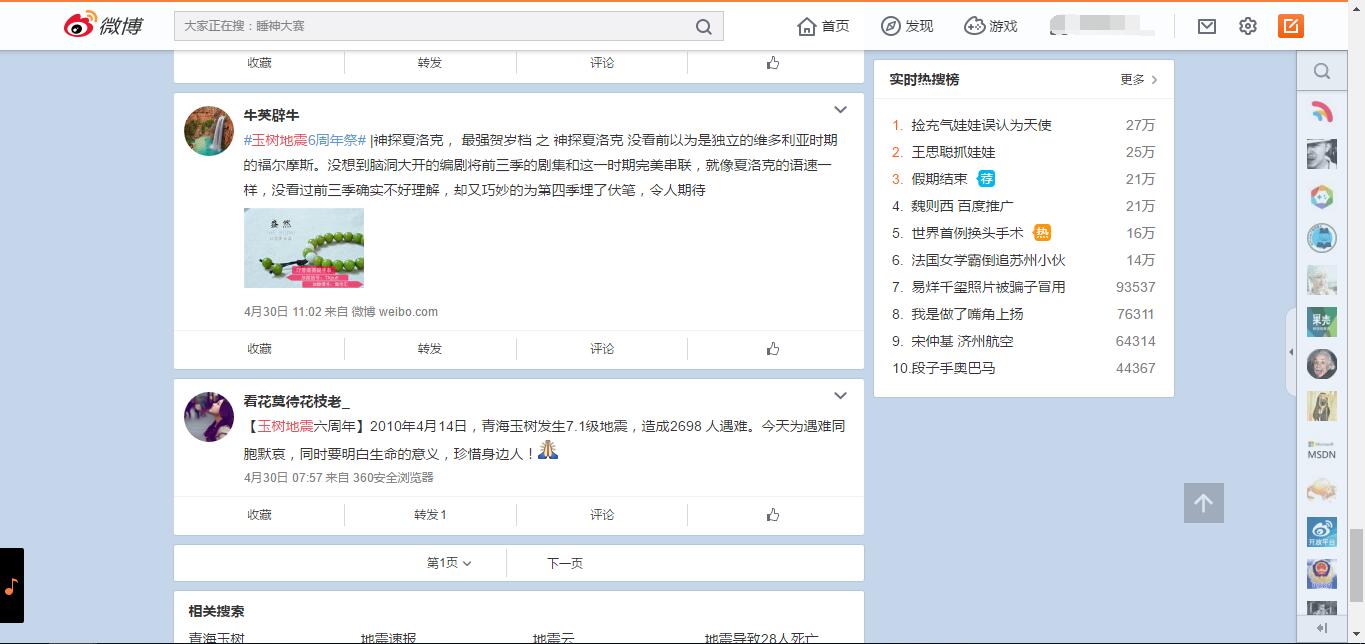
類似這樣的情況,最典型的特徵是有“下一頁”按鈕,那麼2和3判斷的標準就可以是是否有“下一頁”按鈕。如果有,就可以點選進入下一頁啦!
#判斷是否有下一頁按鈕
def checkNext():
try:
driver.find_element_by_xpath("//a[@class='page next S_txt1 S_line1']")
flag = True
except:
flag = False
return flag獲取頁面內容
在判定頁面有內容的前提下,頁面內容的獲取是最重要的一部分,通過分析頁面DOM節點,逐一獲取需要的資訊:
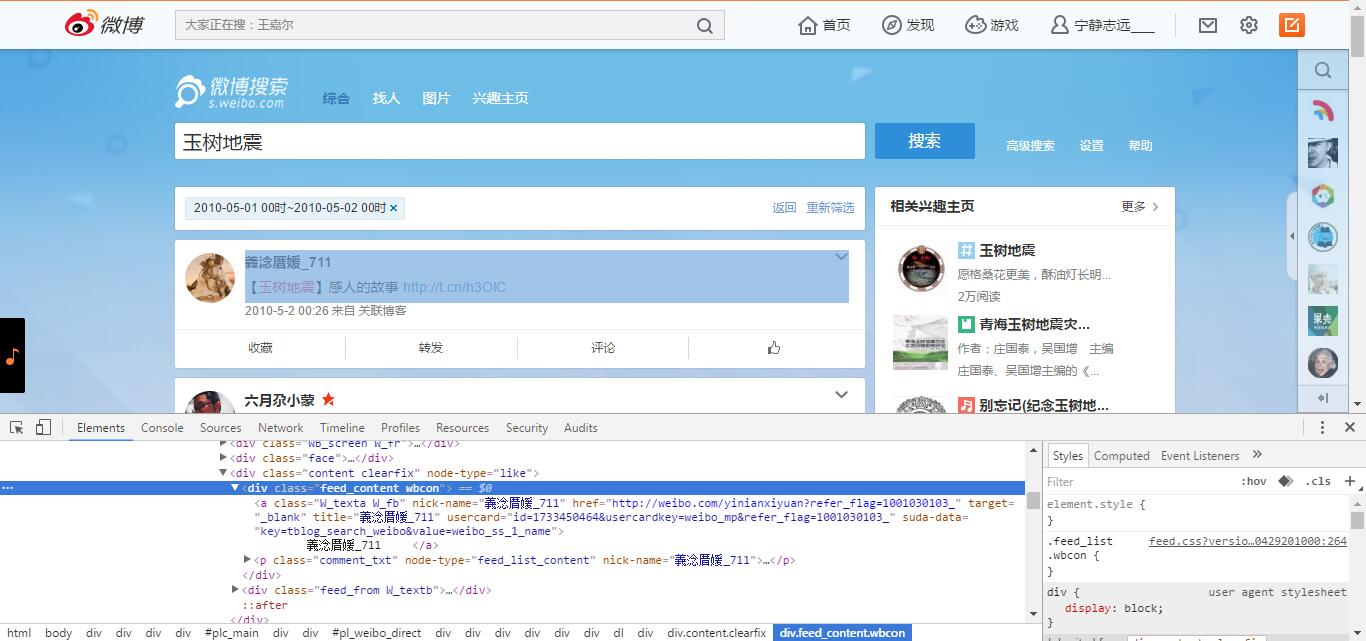
#在頁面有內容的前提下,獲取內容
def getContent():
#尋找到每一條微博的class
nodes = driver.find_elements_by_xpath("//div[@class='WB_cardwrap S_bg2 clearfix']")
#在執行過程中微博數==0的情況,可能是微博反爬機制,需要輸入驗證碼
if len(nodes) == 0:
raw_input("請在微博頁面輸入驗證碼!")
url = driver.current_url
driver.get(url)
getContent()
return
dic = {}
global page
print str(start_stamp.strftime("%Y-%m-%d-%H"))
print u'頁數:', page
page = page + 1
print u'微博數量', len(nodes)
for i in range(len(nodes)):
dic[i] = []
try:
BZNC = nodes[i].find_element_by_xpath(".//div[@class='feed_content wbcon']/a[@class='W_texta W_fb']").text
except:
BZNC = ''
print u'博主暱稱:', BZNC
dic[i].append(BZNC)
try:
BZZY = nodes[i].find_element_by_xpath(".//div[@class='feed_content wbcon']/a[@class='W_texta W_fb']").get_attribute("href")
except:
BZZY = ''
print u'博主主頁:', BZZY
dic[i].append(BZZY)
try:
WBRZ = nodes[i].find_element_by_xpath(".//div[@class='feed_content wbcon']/a[@class='approve_co']").get_attribute('title')#若沒有認證則不存在節點
except:
WBRZ = ''
print '微博認證:', WBRZ
dic[i].append(WBRZ)
try:
WBDR = nodes[i].find_element_by_xpath(".//div[@class='feed_content wbcon']/a[@class='ico_club']").get_attribute('title')#若非達人則不存在節點
except:
WBDR = ''
print '微博達人:', WBDR
dic[i].append(WBDR)
try:
WBNR = nodes[i].find_element_by_xpath(".//div[@class='feed_content wbcon']/p[@class='comment_txt']").text
except:
WBNR = ''
print '微博內容:', WBNR
dic[i].append(WBNR)
try:
FBSJ = nodes[i].find_element_by_xpath(".//div[@class='feed_from W_textb']/a[@class='W_textb']").text
except:
FBSJ = ''
print u'釋出時間:', FBSJ
dic[i].append(FBSJ)
try:
WBDZ = nodes[i].find_element_by_xpath(".//div[@class='feed_from W_textb']/a[@class='W_textb']").get_attribute("href")
except:
WBDZ = ''
print '微博地址:', WBDZ
dic[i].append(WBDZ)
try:
WBLY = nodes[i].find_element_by_xpath(".//div[@class='feed_from W_textb']/a[@rel]").text
except:
WBLY = ''
print '微博來源:', WBLY
dic[i].append(WBLY)
try:
ZF_TEXT = nodes[i].find_element_by_xpath(".//a[@action-type='feed_list_forward']//em").text
if ZF_TEXT == '':
ZF = 0
else:
ZF = int(ZF_TEXT)
except:
ZF = 0
print '轉發:', ZF
dic[i].append(str(ZF))
try:
PL_TEXT = nodes[i].find_element_by_xpath(".//a[@action-type='feed_list_comment']//em").text#可能沒有em元素
if PL_TEXT == '':
PL = 0
else:
PL = int(PL_TEXT)
except:
PL = 0
print '評論:', PL
dic[i].append(str(PL))
try:
ZAN_TEXT = nodes[i].find_element_by_xpath(".//a[@action-type='feed_list_like']//em").text #可為空
if ZAN_TEXT == '':
ZAN = 0
else:
ZAN = int(ZAN_TEXT)
except:
ZAN = 0
print '贊:', ZAN
dic[i].append(str(ZAN))
print '\n'
#寫入Excel
writeXLS(dic)寫在最後
上一篇部落格中我提到過:一般來說,資料抓取工作主要有兩種方式:一是通過抓包工具(Fiddle)進行抓包分析,獲取ajax請求的URL,通過URL抓取資料,這也是更為通用、推薦的方法;另外一種方法就是後面要使用的模擬瀏覽器行為的爬蟲。
我深知,本文所使用的資料抓取方法是一種效率較為低下的方式,但另外一方面來看,也是入門較快的一種方式,只需要掌握selenium、xpath的基礎語法,便可以快速地構建爬蟲程式。接下來會更加深入地研究高效率的爬蟲方法。
希望這種簡單的思想和方法能夠幫助到你,也歡迎多多交流多多指教。
(By MrHammer 2016-05-02 下午6點 @Bin House Rainy)