
MyBatis(8)延遲載入&快取
阿新 • • 發佈:2018-12-14
什麼是延遲載入?
resultMap可以實現高階對映,association,collection具有延遲載入的功能。
當我們需要查詢某個資訊的時候,再去查詢,達到按需查詢,就是延遲載入
可以大大提高資料庫的效能
那麼我們程式碼擼起來把:
延遲載入我們首先要在全域性配置檔案中開啟:
SQlMapConfig.xml:
 在操作資料庫時需構造sqlsession物件,在物件中有一個數據結構(HashMap)用於儲存資料
不同的sqlsession之間的快取資料區域時互不影響的
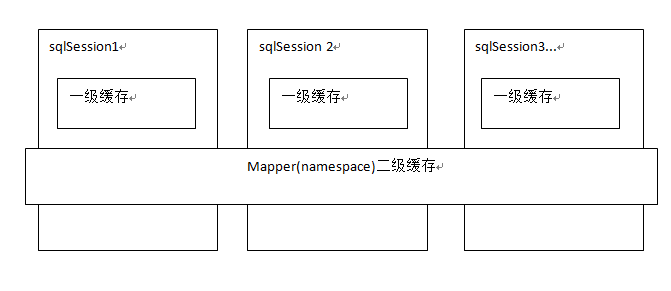
一級快取:是sqlsession級別的快取
二級快取:是mapper級別的快取多個SqlSession去操作同一個Mapper的sql語句,多個SqlSession可以共用二級快取,二級快取是跨SqlSession的。
為什麼需要快取:
如果快取中有資料就不需要從資料庫中獲取,提高系統性能。
一級快取:
工作原理:
在操作資料庫時需構造sqlsession物件,在物件中有一個數據結構(HashMap)用於儲存資料
不同的sqlsession之間的快取資料區域時互不影響的
一級快取:是sqlsession級別的快取
二級快取:是mapper級別的快取多個SqlSession去操作同一個Mapper的sql語句,多個SqlSession可以共用二級快取,二級快取是跨SqlSession的。
為什麼需要快取:
如果快取中有資料就不需要從資料庫中獲取,提高系統性能。
一級快取:
工作原理:

 首先開啟mybatis的二級快取。
sqlSession1去查詢使用者id為1的使用者資訊,查詢到使用者資訊會將查詢資料儲存到二級快取中。
如果SqlSession3去執行相同 mapper下sql,執行commit提交,清空該 mapper下的二級快取區域的資料。
sqlSession2去查詢使用者id為1的使用者資訊,去快取中找是否存在資料,如果存在直接從快取中取出資料
。
二級快取與一級快取區別,二級快取的範圍更大,多個sqlSession可以共享一個UserMapper的二級快取區域。
UserMapper有一個二級快取區域(按namespace分) ,其它mapper也有自己的二級快取區域(按namespace分)。
每一個namespace的mapper都有一個二快取區域,兩個mapper的namespace如果相同,這兩個mapper執行sql查詢到資料將存在相同 的二級快取區域中。
開啟二級快取:
首先開啟mybatis的二級快取。
sqlSession1去查詢使用者id為1的使用者資訊,查詢到使用者資訊會將查詢資料儲存到二級快取中。
如果SqlSession3去執行相同 mapper下sql,執行commit提交,清空該 mapper下的二級快取區域的資料。
sqlSession2去查詢使用者id為1的使用者資訊,去快取中找是否存在資料,如果存在直接從快取中取出資料
。
二級快取與一級快取區別,二級快取的範圍更大,多個sqlSession可以共享一個UserMapper的二級快取區域。
UserMapper有一個二級快取區域(按namespace分) ,其它mapper也有自己的二級快取區域(按namespace分)。
每一個namespace的mapper都有一個二快取區域,兩個mapper的namespace如果相同,這兩個mapper執行sql查詢到資料將存在相同 的二級快取區域中。
開啟二級快取:
 不使用分佈快取,快取的資料在各各服務單獨儲存,不方便系統 開發。所以要使用分散式快取對快取資料進行集中管理。
mybatis無法實現分散式快取,需要和其它分散式快取框架進行整合。
整和方法:
mybatis提供了cache介面,如果要實現自己的快取邏輯,實現cache介面即可
在mybatis包裡的cache類裡面
不使用分佈快取,快取的資料在各各服務單獨儲存,不方便系統 開發。所以要使用分散式快取對快取資料進行集中管理。
mybatis無法實現分散式快取,需要和其它分散式快取框架進行整合。
整和方法:
mybatis提供了cache介面,如果要實現自己的快取邏輯,實現cache介面即可
在mybatis包裡的cache類裡面
 二級快取應用場景:
對於訪問多的查詢請求且使用者對查詢結果實時性要求不高,此時可採用mybatis二級快取技術降低資料庫訪問量,提高訪問速度,業務場景比如:耗時較高的統計分析sql、電話賬單查詢sql等。
實現方法如下:通過設定重新整理間隔時間,由mybatis每隔一段時間自動清空快取,根據資料變化頻率設定快取重新整理間隔flushInterval,比如設定為30分鐘、60分鐘、24小時等,根據需求而定。
二級快取的侷限性:
mybatis二級快取對細粒度的資料級別的快取實現不好,比如如下需求:對商品資訊進行快取,由於商品資訊查詢訪問量大,但是要求使用者每次都能查詢最新的商品資訊,此時如果使用mybatis的二級快取就無法實現當一個商品變化時只重新整理該商品的快取資訊而不重新整理其它商品的資訊,因為mybaits的二級快取區域以mapper為單位劃分,當一個商品資訊變化會將所有商品資訊的快取資料全部清空。解決此類問題需要在業務層根據需求對資料有針對性快取。
二級快取應用場景:
對於訪問多的查詢請求且使用者對查詢結果實時性要求不高,此時可採用mybatis二級快取技術降低資料庫訪問量,提高訪問速度,業務場景比如:耗時較高的統計分析sql、電話賬單查詢sql等。
實現方法如下:通過設定重新整理間隔時間,由mybatis每隔一段時間自動清空快取,根據資料變化頻率設定快取重新整理間隔flushInterval,比如設定為30分鐘、60分鐘、24小時等,根據需求而定。
二級快取的侷限性:
mybatis二級快取對細粒度的資料級別的快取實現不好,比如如下需求:對商品資訊進行快取,由於商品資訊查詢訪問量大,但是要求使用者每次都能查詢最新的商品資訊,此時如果使用mybatis的二級快取就無法實現當一個商品變化時只重新整理該商品的快取資訊而不重新整理其它商品的資訊,因為mybaits的二級快取區域以mapper為單位劃分,當一個商品資訊變化會將所有商品資訊的快取資料全部清空。解決此類問題需要在業務層根據需求對資料有針對性快取。
<!-- 延遲載入 -->
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading
lazyLoadingEnabled:全域性性設定懶載入。如果設為‘false’,則所有相關聯的都會被初始化載入。
aggressiveLazyLoading:當設定為‘true’的時候,懶載入的物件可能被任何懶屬性全部載入。否則,每個屬性都按需載入。
其次是OrderMapperCustomer.xml對映檔案:
<!-- 延遲載入 -->
<resultMap type="com.MrChengs.po.Orders" id="slow">
<id column="id" property="id"/>
<result column="user_id" property="userId"/>
<result column="number" property="number"/>
<result column="createtime" property="createtime"/>
<result column="note" property="note"/>
<!-- 實現對使用者資訊進行延遲載入
select:指定延遲載入需要執行的statement的id(是根據user_id查詢使用者資訊的statement)
要使用userMapper.xml中findUserById完成根據使用者id(user_id)使用者資訊的查詢,如果findUserById不在本mapper中需要前邊加namespace
column:訂單資訊中關聯使用者資訊查詢的列,是user_id
關聯查詢的sql理解為:
SELECT orders.
測試檔案:
//延遲載入 @Test public void testfindSlowing() throws Exception { SqlSession sqlSession = getSqlSessionFactory().openSession(); //代理物件 OrderMapperCustomer mapper = sqlSession.getMapper(OrderMapperCustomer.class); //測試findOrderUsers List<Orders> orders = mapper.findSlowing(); for(Orders order : orders){ User user = order.getUser(); System.out.println(user); } sqlSession.close(); }
結果:
DEBUG [main] - Setting autocommit to false on JDBC Connection [[email protected]] DEBUG [main] - ==> Preparing: SELECT * from orders DEBUG [main] - ==> Parameters: DEBUG [main] - <== Total: 3 DEBUG [main] - ==> Preparing: select * from user where id=? DEBUG [main] - ==> Parameters: 1(Integer) DEBUG [main] - <== Total: 1 User [id=1, username=王五, birthday=null, sex=2, address=null] User [id=1, username=王五, birthday=null, sex=2, address=null] DEBUG [main] - ==> Preparing: select * from user where id=? DEBUG [main] - ==> Parameters: 10(Integer) DEBUG [main] - <== Total: 1 User [id=10, username=張三, birthday=Thu Jul 10 00:00:00 CST 2014, sex=1, address=北京市] DEBUG [main] - Resetting autocommit to true on JDBC Connection [[email protected]]快取: 用於減輕資料庫壓力,提高資料庫的效能 mybatis提供一級快取&二級快取
在操作資料庫時需構造sqlsession物件,在物件中有一個數據結構(HashMap)用於儲存資料
不同的sqlsession之間的快取資料區域時互不影響的
一級快取:是sqlsession級別的快取
二級快取:是mapper級別的快取多個SqlSession去操作同一個Mapper的sql語句,多個SqlSession可以共用二級快取,二級快取是跨SqlSession的。
為什麼需要快取:
如果快取中有資料就不需要從資料庫中獲取,提高系統性能。
一級快取:
工作原理:
第一次查詢先去快取中查詢,若沒有則取資料庫中查詢
如果sqlsession去執行commit操作(插入,刪除,更新),清空sqlsession中的一級快取,使儲存區域得到最新的 資訊,避免髒讀。 第二次在查詢第一次資料,首先在快取中查詢,找到了則不再去資料庫想查詢 預設支援一級快取,不需要手動去開啟。 測試程式碼: 在testUserMapper.java//一級快取 @Test public void testCahseFiret() throws Exception{ SqlSession sqlSession = getSqlSessionFactory().openSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); //第一次查詢 User user = mapper.findUserById(1); System.out.println(user); //第二次查詢 User user1 = mapper.findUserById(1); System.out.println(user1); sqlsession.close(); }結果: 由此可見,查詢時,只查詢了一次
DEBUG [main] - Setting autocommit to false on JDBC Connection [[email protected]] DEBUG [main] - ==> Preparing: select * from user where id=? DEBUG [main] - ==> Parameters: 1(Integer) DEBUG [main] - <== Total: 1 User [id=1, username=王五, birthday=null, sex=2, address=null] User [id=1, username=王五, birthday=null, sex=2, address=null]有清空操作:
@Test public void testCahseFiret() throws Exception{ SqlSession sqlSession = getSqlSessionFactory().openSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); //第一次查詢 User user = mapper.findUserById(1); System.out.println(user); //commit User adduser = new User(); adduser.setUsername("Mr"); adduser.setSex(1); mapper.addUser(user); //清空快取 sqlSession.commit(); //第二次查詢 User user1 = mapper.findUserById(1); System.out.println(user1); sqlSession.close(); }
結果:
DEBUG [main] - Opening JDBC Connection DEBUG [main] - Created connection 149047107. DEBUG [main] - Setting autocommit to false on JDBC Connection [[email protected]] DEBUG [main] - ==> Preparing: select * from user where id=? DEBUG [main] - ==> Parameters: 1(Integer) DEBUG [main] - <== Total: 1 User [id=1, username=王五, birthday=null, sex=2, address=null] DEBUG [main] - ==> Preparing: insert into user(id,username,birthday,sex,address) value(?,?,?,?,?) DEBUG [main] - ==> Parameters: 1(Integer), 王五(String), null, 2(Integer), null一級快取的應用: 正式開發,是將mybatis和spring進行整合,事物控制在service中 一個servic包括很多mapper方法呼叫 二級快取:
首先開啟mybatis的二級快取。
sqlSession1去查詢使用者id為1的使用者資訊,查詢到使用者資訊會將查詢資料儲存到二級快取中。
如果SqlSession3去執行相同 mapper下sql,執行commit提交,清空該 mapper下的二級快取區域的資料。
sqlSession2去查詢使用者id為1的使用者資訊,去快取中找是否存在資料,如果存在直接從快取中取出資料
。
二級快取與一級快取區別,二級快取的範圍更大,多個sqlSession可以共享一個UserMapper的二級快取區域。
UserMapper有一個二級快取區域(按namespace分) ,其它mapper也有自己的二級快取區域(按namespace分)。
每一個namespace的mapper都有一個二快取區域,兩個mapper的namespace如果相同,這兩個mapper執行sql查詢到資料將存在相同 的二級快取區域中。
開啟二級快取:
<settings>
<!-- 開啟二級快取 -->
<setting name="cacheEnabled" value="true"/>
</settings>
cacheEnabled:對在此配置檔案下的所有cache 進行全域性性開/關設定。
開啟mapper下的二級快取: UserMapper.xml <!-- 開啟本mapper的namespace下的二級快取 -->
<cache>
</cache>
實現pojo類實現裡序列化介面:
public class User implements Serializable{ ...... }
為了將儲存資料取出執行反序列化的操作,以內二級快取儲存介質多種多種楊,不一定在記憶體
測試類 ://二級快取 @Test public void testCahseSecond() throws Exception{ SqlSession sqlSession = getSqlSessionFactory().openSession(); SqlSession sqlSession1 = getSqlSessionFactory().openSession(); //第一次查詢 UserMapper mapper = sqlSession.getMapper(UserMapper.class); User user = mapper.findUserById(1); System.out.println(user); //將執行關閉操作,將sqlsession寫道二級快取 sqlSession.close(); //第二次查詢 UserMapper mapper2 = sqlSession1.getMapper(UserMapper.class); User user1 = mapper2.findUserById(1); System.out.println(user1); sqlSession1.close(); }
結果:
DEBUG [main] - Setting autocommit to false on JDBC Connection [[email protected]] DEBUG [main] - ==> Preparing: select * from user where id=? DEBUG [main] - ==> Parameters: 1(Integer) DEBUG [main] - <== Total: 1 User [id=1, username=王五, birthday=null, sex=2, address=null] DEBUG [main] - Resetting autocommit to true on JDBC Connection [[email protected]] DEBUG [main] - Closing JDBC Connection [[email protected]] DEBUG [main] - Returned connection 428910174 to pool. DEBUG [main] - Cache Hit Ratio [com.MrChengs.mapper.UserMapper]: 0.0 DEBUG [main] - Opening JDBC Connection DEBUG [main] - Created connection 1873859565. DEBUG [main] - Setting autocommit to false on JDBC Connection [[email protected]] DEBUG [main] - ==> Preparing: select * from user where id=? DEBUG [main] - ==> Parameters: 1(Integer) DEBUG [main] - <== Total: 1 User [id=1, username=王五, birthday=null, sex=2, address=null]一些簡單的引數配置: 1. useCache:為fasle時,禁用快取 <select id="" useCache="true"></select> 針對每次查詢都需要最新資料的sql 2. flushCache:重新整理快取,實質就是清空快取,刷尋快取可以避免資料的髒讀 <select id="" flushCache="true"></select> 3. flushInterval:重新整理間隔,可以設定任意的毫秒數,代表一個何況i的時間段 <cache flushInterval="" /> mybatis整合ehcache ehcache分散式的快取
不使用分佈快取,快取的資料在各各服務單獨儲存,不方便系統 開發。所以要使用分散式快取對快取資料進行集中管理。
mybatis無法實現分散式快取,需要和其它分散式快取框架進行整合。
整和方法:
mybatis提供了cache介面,如果要實現自己的快取邏輯,實現cache介面即可
在mybatis包裡的cache類裡面
二級快取應用場景:
對於訪問多的查詢請求且使用者對查詢結果實時性要求不高,此時可採用mybatis二級快取技術降低資料庫訪問量,提高訪問速度,業務場景比如:耗時較高的統計分析sql、電話賬單查詢sql等。
實現方法如下:通過設定重新整理間隔時間,由mybatis每隔一段時間自動清空快取,根據資料變化頻率設定快取重新整理間隔flushInterval,比如設定為30分鐘、60分鐘、24小時等,根據需求而定。
二級快取的侷限性:
mybatis二級快取對細粒度的資料級別的快取實現不好,比如如下需求:對商品資訊進行快取,由於商品資訊查詢訪問量大,但是要求使用者每次都能查詢最新的商品資訊,此時如果使用mybatis的二級快取就無法實現當一個商品變化時只重新整理該商品的快取資訊而不重新整理其它商品的資訊,因為mybaits的二級快取區域以mapper為單位劃分,當一個商品資訊變化會將所有商品資訊的快取資料全部清空。解決此類問題需要在業務層根據需求對資料有針對性快取。