
Mybatis學習(五)————— 延遲載入和快取機制(一級二級快取)
一、延遲載入
延遲載入就是懶載入,先去查詢主表資訊,如果用到從表的資料的話,再去查詢從表的資訊,也就是如果沒用到從表的資料的話,就不查詢從表的資訊。所以這就是突出了懶這個特點。真是懶啊。
Mybatis中resultMap可以實現延遲載入
1.1、查詢訂單資訊,延遲載入使用者資訊,一對一關係。
1.1.1、開啟延遲載入
全域性配置檔案中,settings標籤用來設定全域性常量的,這裡就用到了。


1 <settings> 2 //開啟延遲載入的開關,預設為true 3 <setting name="lazyLoadingEnabled" value="true"/> 4 //積極的懶載入,預設是true,設定為false時,懶載入生效 5 <setting name="aggressiveLazyLoading" value="false"/> 6 </settings>

1 <settings> 2 //開啟延遲載入的開關,預設為true 3 <setting name="lazyLoadingEnabled" value="true"/> 4 //積極的懶載入,預設是true,設定為false時,懶載入生效 5 <setting name="aggressiveLazyLoading" value="false"/> 6 </settings>
1.1.2、編寫主表資訊的查詢對映
也就是先查詢orders

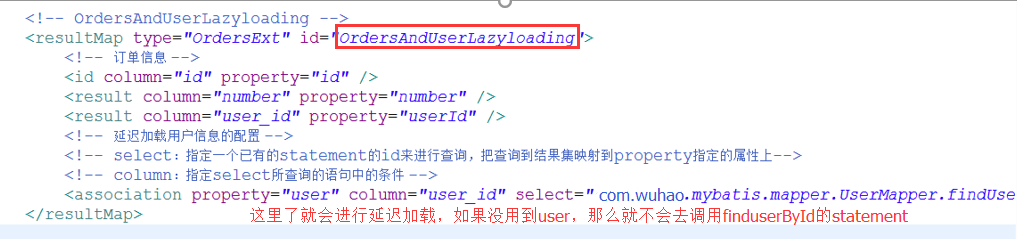
這裡asscciation中property中的user為OrderExt中的一個user屬性。注意區分。
1.1.3、編寫從表的查詢對映,findUserById

1.2、小總結
很簡單,就三步
1、開啟延遲載入
2、編寫主表的查詢對映
3、編寫從表的查詢對映
2、3兩步通俗點講就是將其分開來,並不是向之前一樣,一次性全寫了,注意這點就OK了。
二、快取機制
快取的作用是什麼?
mybatis提供查詢快取,如果快取中有資料就不用從資料庫中獲取,用於減輕資料壓力,提高系統性能,
mybatis中分兩個快取,一級快取和二級快取,現在來講講這兩個快取,也同樣很easy。
2.1、一級快取
一級快取是SqlSession級別的快取。在操作資料庫時需要構造 sqlSession物件,在物件中有一個數據結構(HashMap)用於儲存快取資料。不同的sqlSession之間的快取資料區域(HashMap)是互相不影響的
過程分析
第一次查詢id為1 的使用者,此時先去一級快取查詢,如果查詢不到,則去資料庫查詢,把查詢後的 結果儲存到一級快取中
第二次查詢id為1 的使用者,此時先去一級快取查詢,如果查詢到,則直接從一級快取中把資料取出,不去查詢資料庫
只要中間發生增刪改操作,那麼一級快取就清空
預設開啟一級快取
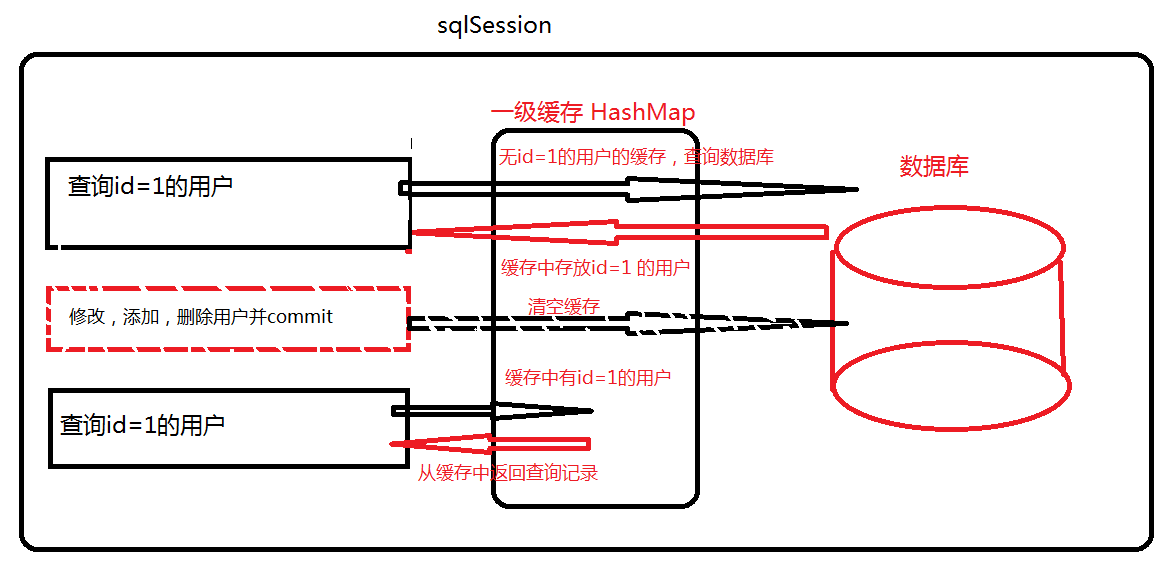
注意:第二步中,修改,新增,刪除是對快取中已經有的記錄進行這三個操作才會把一級快取全部清空,如果是操作的快取中沒有的資料,那麼就不會清空快取。
測試的話就不測試了,也不需要配置什麼東西開啟,預設開啟的,如果感興趣,那麼就對其進行測試。
2.2、二級快取
二級快取是mapper級別的快取,多個SqlSession去操作同一個Mapper的sql語句,多個SqlSession可以共用二級快取,二級快取是跨SqlSession的
過程分析
第一次查詢id為1 的使用者,此時先去二級快取查詢,如果查詢不到,則去資料庫查詢,把查詢後的 結果儲存到二級快取中
第二次查詢id為1 的使用者,此時先去二級快取查詢,如果查詢到,則直接從二級快取中把資料取出,不去查詢資料庫
只要中間發生增刪改操作,那麼二級快取就清空
二級快取預設不開啟,需要手動開啟。
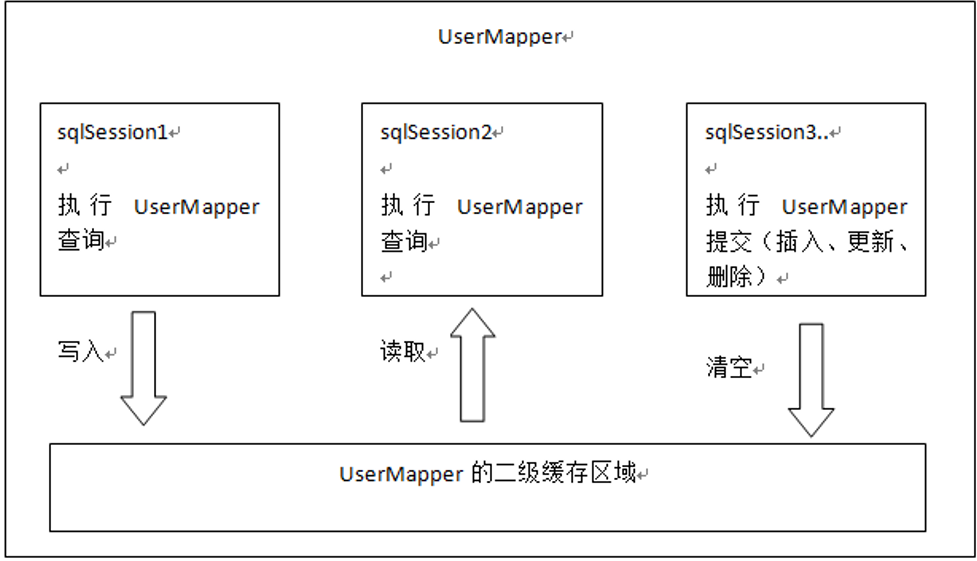
跟一級快取差不多,只是二級快取是mapper級別的,也就是每個sqlSession共享該快取,而不是每個sqlSession獨享。
一級快取和二級快取的作用範圍圖
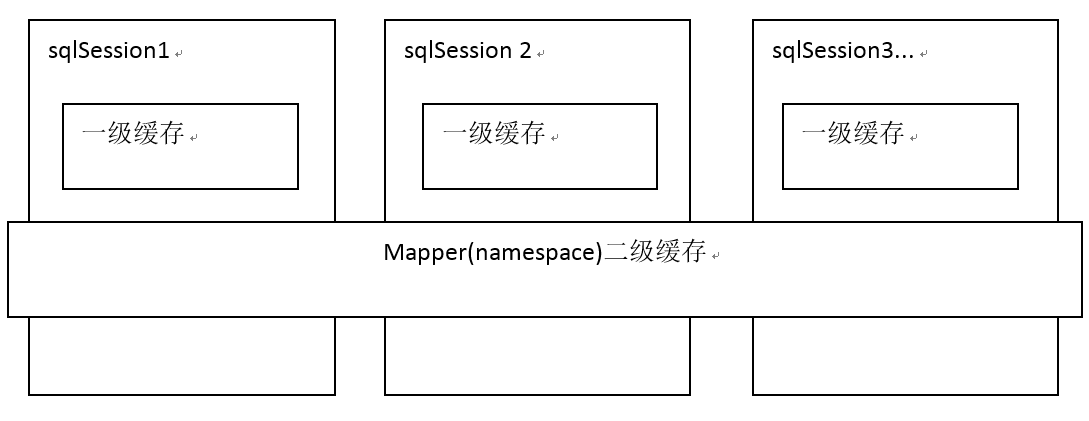
關係:當開啟了二級快取時,那麼一級快取就失效了,大家都共享二級快取,相當於沒有一級快取,不管幹什麼都是對二級快取進行操作。這裡跟hibernate的快取有區別,不要搞混淆了。
使用mybatis自帶的二級快取
5.2.1、開啟二級快取
第一步:在全域性配置檔案中開啟

第二步:在對映檔案中開啟二級快取的開關
因為使用的是自帶的,所以直接寫cache即可,如果使用的是第三方快取框架,那麼這裡就需要寫東西了,後面會講解到。

5.2.2、序列化物件
二級快取中的資料,可以儲存到磁碟中,因為快取中儲存的是物件,所以需要對物件進行一個序列化
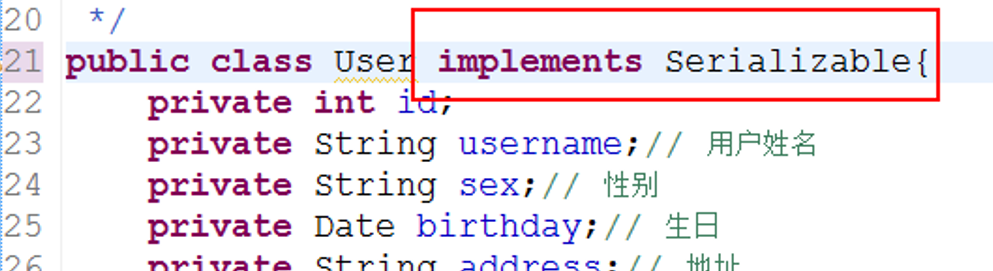
不開啟序列化,則會報下面的錯誤
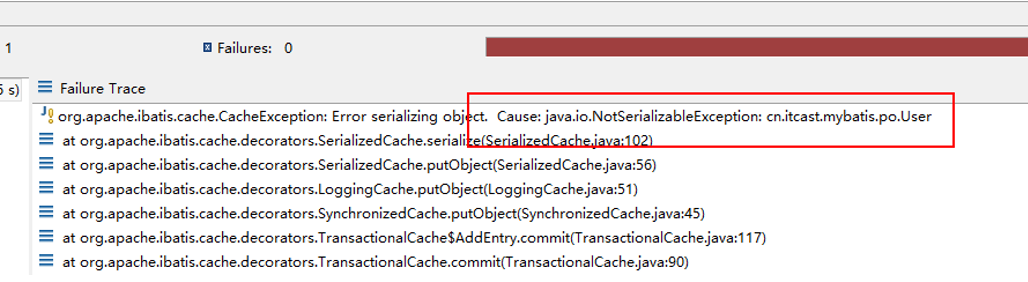
5.2.3、這樣二級快取就開啟了,下次在查詢或者別的操作,就會使用二級快取。
5.2.4、重新整理快取
在對映檔案的statement標籤,可以設定是否重新整理快取。這個要注意,

注意,這裡先不看userCache這個標籤。在下面會講解到
該statement中設定flushCache=true可以重新整理當前的二級快取,預設情況下
select語句:flushCache是false,也就是預設情況下,select語句是不會重新整理快取的。
如果設定成true,那麼每次查詢都市去資料庫查詢,意味著查詢的二級快取失效
insert、update、delete語句:flushCache是true,也就是預設情況下,增刪改是會重新整理快取的。
如果增刪改設定為false,即使用二級快取,那麼如果在資料庫中修改了資料,而快取資料還是原來的,這個時候就會出現問題。
所以一般不用手動設定,使用預設的即可。
5.2.5、禁用快取
該statement中設定userCache=false,可以禁用當前select語句的二級快取,即每次查詢都是去資料庫中查詢,預設情況下是true,即該statement使用二級快取
三、Mybatis整合使用ehcache
ehcache是一個分散式快取框架(叢集部署)
3.1、叢集是什麼意思?
比如開發一個電商網站,訪問的人數太多,伺服器壓力太大,所以想到一個方法,就是將該專案釋出到幾個伺服器上,讓使用者訪問過來,隨機分配一個伺服器,這樣幾個伺服器就均攤了壓力,但是這樣有一個問題,A使用者第一次訪問網站,隨機發配到了B伺服器,瀏覽了很多商品,也快取了很多資料,此時A不小心關閉了瀏覽器,接著在進行訪問,這次隨機分配到了C伺服器,此時快取卻沒有了,因為不是同一個伺服器,那麼怎麼解決這個快取問題呢?此時就有一種方法來解決。看下圖
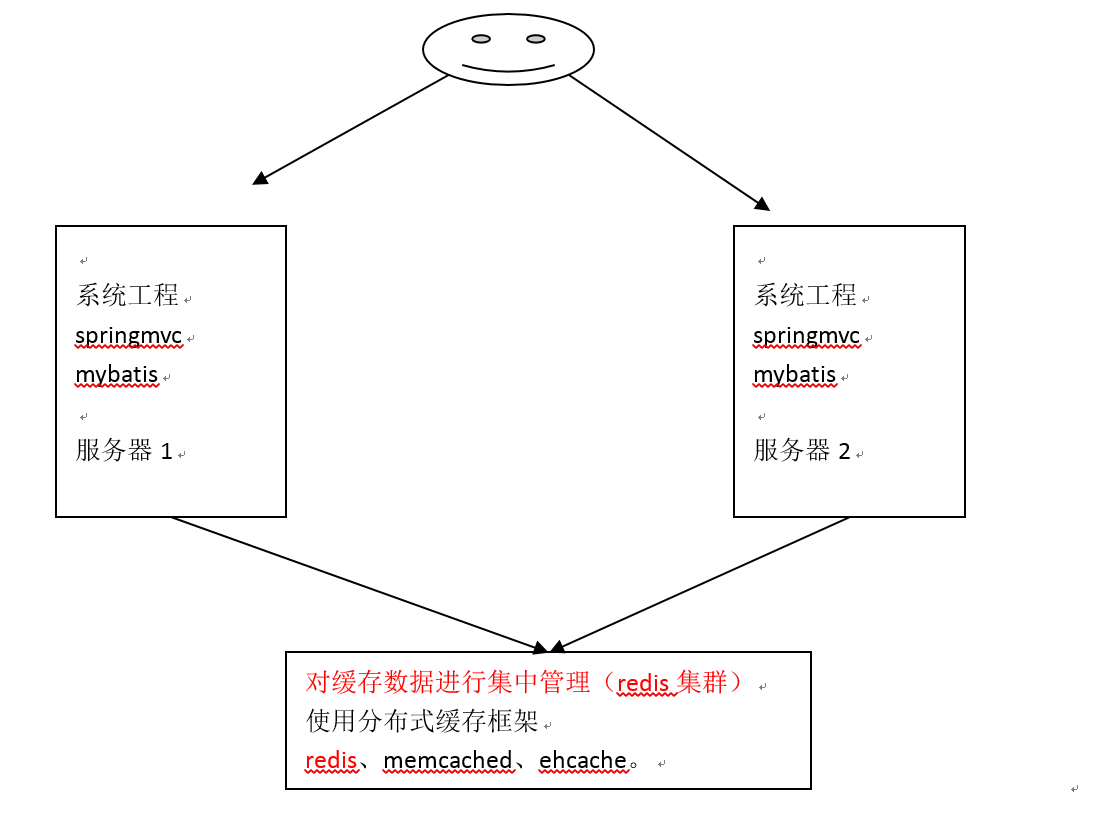
所以叢集就是將很多伺服器集中起來一起進行同一種服務,這裡進行的服務就是對快取資料進行集中管理。

3.2、為什麼使用第三方快取框架?
其實上面已經解釋過了,Mybatis它是一個持久層的框架,不是一個快取框架。所以說她本身的快取機制不是很好,不能支援分散式,所以需要對它進行整合,整合其他的分散式快取框架,在之前對hibernate中的二級快取,也是使用的ehcache,之後我們還會學到一個redis的快取框架
3.3、整合快取框架(例如ehcache)
前提是也需要開啟二級快取的開關呀,比如在全域性配置檔案中開啟開關,具體看上面
3.3.1、瞭解
Mybatis提供了一個cache介面,同時它自己有一個預設的實現類PerpetualCache
cache介面

預設的實現類PerpetualCache
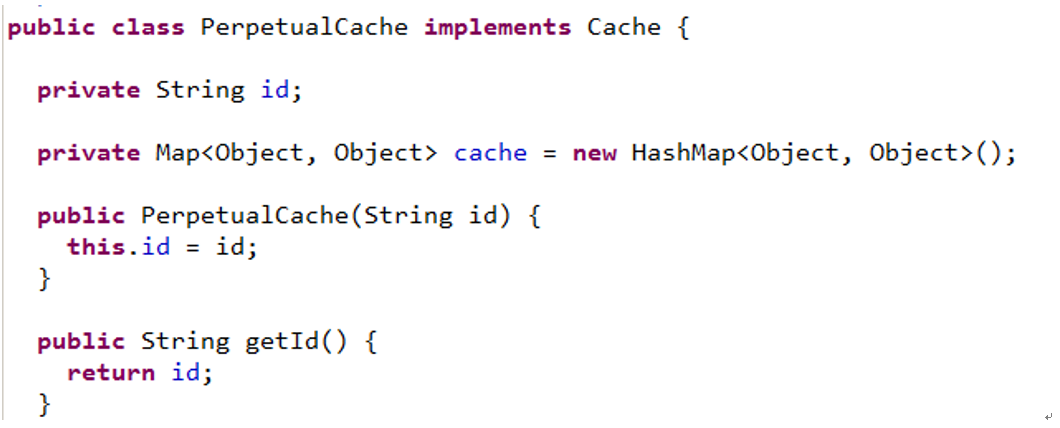
在我們使用mybatis預設的二級快取時,在對映檔案中只寫了一個cache,其中就是預設使用的mybatis預設的二級快取,也就是這個實現類,如果整合其他快取框架的話,那麼就需要改變了,下面會講解到,現在這裡瞭解一下。
3.3.2、新增ehcache的jar包
3.3.3、新增ehcache的配置檔案
建立ehcache.xml檔案,檔案內容如下

1 <ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
2 xsi:noNamespaceSchemaLocation="../config/ehcache.xsd">
3 <!-- 快取資料要存放的磁碟地址 -->
4 <diskStore path="F:\develop\ehcache" />
5 <!-- diskStore:指定資料在磁碟中的儲存位置。 defaultCache:當藉助CacheManager.add("demoCache")建立Cache時,EhCache便會採用<defalutCache/>指定的的管理策略
6 以下屬性是必須的: maxElementsInMemory - 在記憶體中快取的element的最大數目 maxElementsOnDisk
7 - 在磁碟上快取的element的最大數目,若是0表示無窮大 eternal - 設定快取的elements是否永遠不過期。如果為true,則快取的資料始終有效,如果為false那麼還要根據timeToIdleSeconds,timeToLiveSeconds判斷
8 overflowToDisk - 設定當記憶體快取溢位的時候是否將過期的element快取到磁碟上 以下屬性是可選的: timeToIdleSeconds
9 - 當快取在EhCache中的資料前後兩次訪問的時間超過timeToIdleSeconds的屬性取值時,這些資料便會刪除,預設值是0,也就是可閒置時間無窮大
10 timeToLiveSeconds - 快取element的有效生命期,預設是0.,也就是element存活時間無窮大 diskSpoolBufferSizeMB
11 這個引數設定DiskStore(磁碟快取)的快取區大小.預設是30MB.每個Cache都應該有自己的一個緩衝區. diskPersistent
12 - 在VM重啟的時候是否啟用磁碟儲存EhCache中的資料,預設是false。 diskExpiryThreadIntervalSeconds
13 - 磁碟快取的清理執行緒執行間隔,預設是120秒。每個120s,相應的執行緒會進行一次EhCache中資料的清理工作 memoryStoreEvictionPolicy
14 - 當記憶體快取達到最大,有新的element加入的時候, 移除快取中element的策略。預設是LRU(最近最少使用),可選的有LFU(最不常使用)和FIFO(先進先出) -->
15
16 <defaultCache maxElementsInMemory="1000"
17 maxElementsOnDisk="10000000" eternal="false" overflowToDisk="false"
18 timeToIdleSeconds="120" timeToLiveSeconds="120"
19 diskExpiryThreadIntervalSeconds="120" memoryStoreEvictionPolicy="LRU">
20 </defaultCache>
21 </ehcache>
1 <ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
2 xsi:noNamespaceSchemaLocation="../config/ehcache.xsd">
3 <!-- 快取資料要存放的磁碟地址 -->
4 <diskStore path="F:\develop\ehcache" />
5 <!-- diskStore:指定資料在磁碟中的儲存位置。 defaultCache:當藉助CacheManager.add("demoCache")建立Cache時,EhCache便會採用<defalutCache/>指定的的管理策略
6 以下屬性是必須的: maxElementsInMemory - 在記憶體中快取的element的最大數目 maxElementsOnDisk
7 - 在磁碟上快取的element的最大數目,若是0表示無窮大 eternal - 設定快取的elements是否永遠不過期。如果為true,則快取的資料始終有效,如果為false那麼還要根據timeToIdleSeconds,timeToLiveSeconds判斷
8 overflowToDisk - 設定當記憶體快取溢位的時候是否將過期的element快取到磁碟上 以下屬性是可選的: timeToIdleSeconds
9 - 當快取在EhCache中的資料前後兩次訪問的時間超過timeToIdleSeconds的屬性取值時,這些資料便會刪除,預設值是0,也就是可閒置時間無窮大
10 timeToLiveSeconds - 快取element的有效生命期,預設是0.,也就是element存活時間無窮大 diskSpoolBufferSizeMB
11 這個引數設定DiskStore(磁碟快取)的快取區大小.預設是30MB.每個Cache都應該有自己的一個緩衝區. diskPersistent
12 - 在VM重啟的時候是否啟用磁碟儲存EhCache中的資料,預設是false。 diskExpiryThreadIntervalSeconds
13 - 磁碟快取的清理執行緒執行間隔,預設是120秒。每個120s,相應的執行緒會進行一次EhCache中資料的清理工作 memoryStoreEvictionPolicy
14 - 當記憶體快取達到最大,有新的element加入的時候, 移除快取中element的策略。預設是LRU(最近最少使用),可選的有LFU(最不常使用)和FIFO(先進先出) -->
15
16 <defaultCache maxElementsInMemory="1000"
17 maxElementsOnDisk="10000000" eternal="false" overflowToDisk="false"
18 timeToIdleSeconds="120" timeToLiveSeconds="120"
19 diskExpiryThreadIntervalSeconds="120" memoryStoreEvictionPolicy="LRU">
20 </defaultCache>
21 </ehcache>
3.3.4、在mapper對映檔案中設定cache標籤的type

3.3.5、這樣就整合完成了。
四、總結
看了一遍之後,是不是覺得都不難,其實確實是不難,明白了怎麼回事就差不多了,但是到了實際用起來又是一回事,現在只是知道是什麼,怎麼去用還需要等到實際開發中慢慢體會。這裡提一下,使用二級快取的侷限性
二級快取對細粒度的資料快取效果不好,什麼意思呢?
場景:對商品資訊進行快取,由於商品資訊查詢訪問量大,但是要求使用者每次查詢都是最新的商品資訊,此時如果使用二級快取,就無法實現當一個商品發生變化只重新整理該商品的快取資訊而不重新整理其他商品快取資訊,因為二級快取是mapper級別的,當一個商品的資訊傳送更新,所有的商品資訊快取資料都會清空
解決此類問題,需要在業務層根據需要對資料有針對性的快取,比如可以對經常變化的 資料操作單獨放到另一個namespace的mapper中
其他沒什麼,這個是順帶說一下,具體開發中肯定會有很多對應的方法的,不過二級快取確實有這樣的缺點。有問題就有解決的方法。
mybatis差不多就快要結束了,下一節將講與spring整合和逆向工程了。加油。