
Tensorflow學習筆記(2)
tf.random_normal([2,3], stddev=2):生成矩陣為2*3,均值為0,標準差為2的隨機數。 正態分佈:若隨機變數X服從一個數學期望為μ、方差為σ^2 的正態分佈,記為N(μ,σ^2)。其概率密度函式為正態分佈的期望值μ決定了其位置,其標準差σ決定了分佈的幅度。當μ = 0,σ = 1時的正態分佈是標準正態分佈。
tensorflow函式:(定義權值和偏置的初始化)。
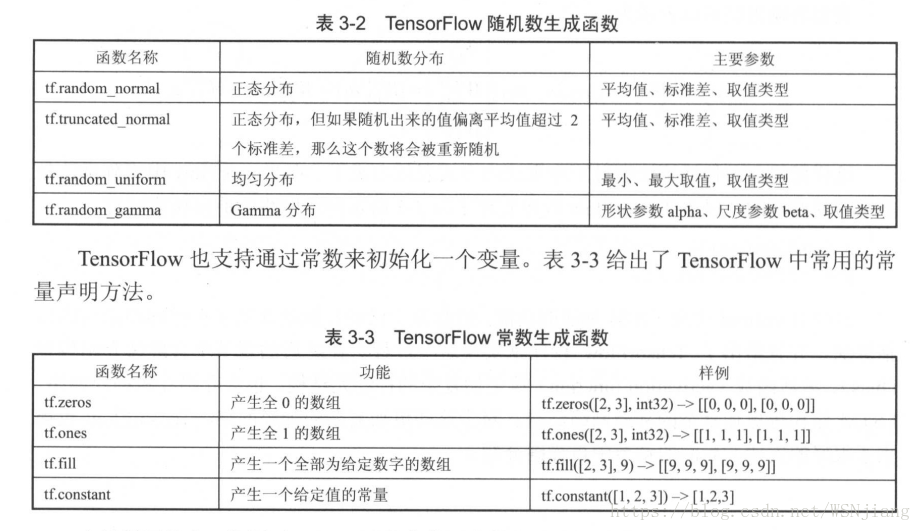
#########建立變數時,使用tf.Variable()時,隨機數等選擇函式tf.random_normal()。tf.get_variable()時,初始化選擇tf.random_normal_initializer()。#####################################
TensorFlow 也支援通過其他變數的初始值來初始化新的變數。 eg: w=tf.Variable(weights.initialized_value()*2.0) weights事先已經定義了。
所有的變數都會被自動加入到GraphKeys.VARIABLES這個集合中,通過tf.global_variables()函式可以拿到當前計算圖上所有的變數。一個變數在構建之後,它的型別就不能再改變了。
tf.assign(ref, value, validate_shape=None, use_locking=None, name=None)將value賦值給ref,並輸出ref。這使得需要使用復位值的連續操作變簡單。其中ref和value必須為同一個型別,當validate_shape為False時,ref和value可以維度不同。
tensorflow提供placeholder機制用於提供輸入資料,placeholder相當於提供了一個位置。在 placeholder定義時,這個位置上的資料型別是需要指定的。和其他張量一樣,placeholder的型別也是不可以改變的。placeholder 中資料的維度資訊可以根據提供的資料推導得出,所以不一定要給出。在新的程式中計算前向傳播結果時,需要提供一個feed_dict來指定x的取值。feed_dict是一個字典(map),在字典中需要給出每個用到的placeholder的取值。如果某個需要的placeholder沒有被指定取值,那麼程式在執行時將會報錯。
計算預測值和真實值的差距:cross_entropy=-tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y,1e-10,1.0))+(1-y_)*tf.log(tf.clip_by_value(1-y,1e-10,1.0)))(交叉熵)
tf.clip_by_value(v,a,b) 功能:可以將一個張量中的數值限制在一個範圍之內。(可以避免一些運算錯誤) 引數:(1)v:input資料(2)a、b是對資料的限制。
- 當v小於a時,輸出a;
- 當v大於a小於b時,輸出原值;
- 當v大於b時,輸出b;
train step =tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)反向優化演算法(優化器) TensorFlow支援10種不同的優化器,常見的為tf.train.GradientDescentOptimizer、tf.train.AdamOptimizer和tf.train.MomentumOptimizer。
編寫網路,不變的三個大的方向。 l. 定義神經網路的結構和前向傳播的輸出結果。 2. 定義損失函式以及選擇反向傳播優化的演算法 。 3. 生成會話(tf.Session)並且在訓練、資料上反覆執行反向傳播優化演算法 。